Карта Интернета
3 мин
Привет всем!
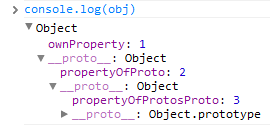
Хочу представить вам Карту Интернета или результат кластеризации более чем 350 тысяч сайтов в соответствии с переходами пользователей между ними. Размер круга определяется посещаемостью сайта, цвет – национальной принадлежностью, а положение на карте – его связями с другими сайтами. Если два сайта имеют стабильный поток пользователей между ними, то они будут «стараться» расположиться ближе друг к другу. После завершения работы алгоритма, на карте можно наблюдать скопления сайтов (кластеры) объединенные общими пользователями.

Например, если ввести в поиск habrahabr.ru, то можно увидеть, что dirty.ru и leprosorium.ru в том же «созвездии», а еще подальше livejournal.ru. Это говорит о том, что тот, кто сейчас читает этот текст, также с высокой вероятностью посещает эти сайты (относительно усредненного пользователя Рунета конечно).
Еще более интересный пример кластеризации можно увидеть внизу карты, между фиолетовой Японией и желтоватой Бразилией: там расположилась целая порнострана по размерам сопоставимая со всем Евронетом. Интересно, что будучи достаточно компетентным в рассматриваемом вопросе, внутри большого порнокластера можно различить тематические подкластеры меньшего размера.
Тем, кого интересует краткое техническое описание – добро пожаловать под кат
Хочу представить вам Карту Интернета или результат кластеризации более чем 350 тысяч сайтов в соответствии с переходами пользователей между ними. Размер круга определяется посещаемостью сайта, цвет – национальной принадлежностью, а положение на карте – его связями с другими сайтами. Если два сайта имеют стабильный поток пользователей между ними, то они будут «стараться» расположиться ближе друг к другу. После завершения работы алгоритма, на карте можно наблюдать скопления сайтов (кластеры) объединенные общими пользователями.
Например, если ввести в поиск habrahabr.ru, то можно увидеть, что dirty.ru и leprosorium.ru в том же «созвездии», а еще подальше livejournal.ru. Это говорит о том, что тот, кто сейчас читает этот текст, также с высокой вероятностью посещает эти сайты (относительно усредненного пользователя Рунета конечно).
Еще более интересный пример кластеризации можно увидеть внизу карты, между фиолетовой Японией и желтоватой Бразилией: там расположилась целая порнострана по размерам сопоставимая со всем Евронетом. Интересно, что будучи достаточно компетентным в рассматриваемом вопросе, внутри большого порнокластера можно различить тематические подкластеры меньшего размера.
Тем, кого интересует краткое техническое описание – добро пожаловать под кат

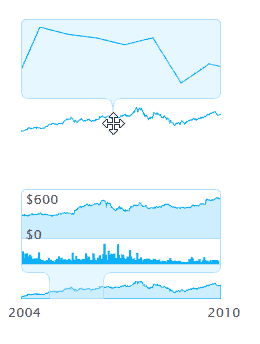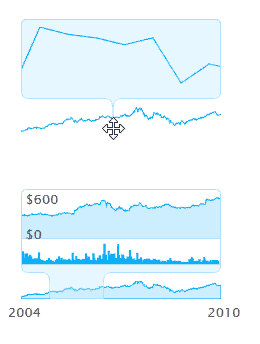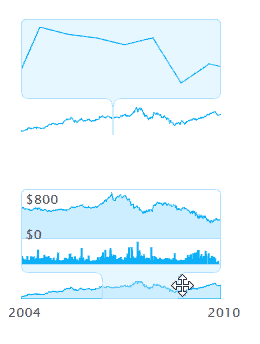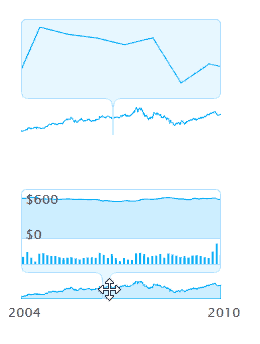
 В этой статье я кратко в примерах объясню что такое свойства __proto__, prototype и работу оператора new в JavaScript.
В этой статье я кратко в примерах объясню что такое свойства __proto__, prototype и работу оператора new в JavaScript.