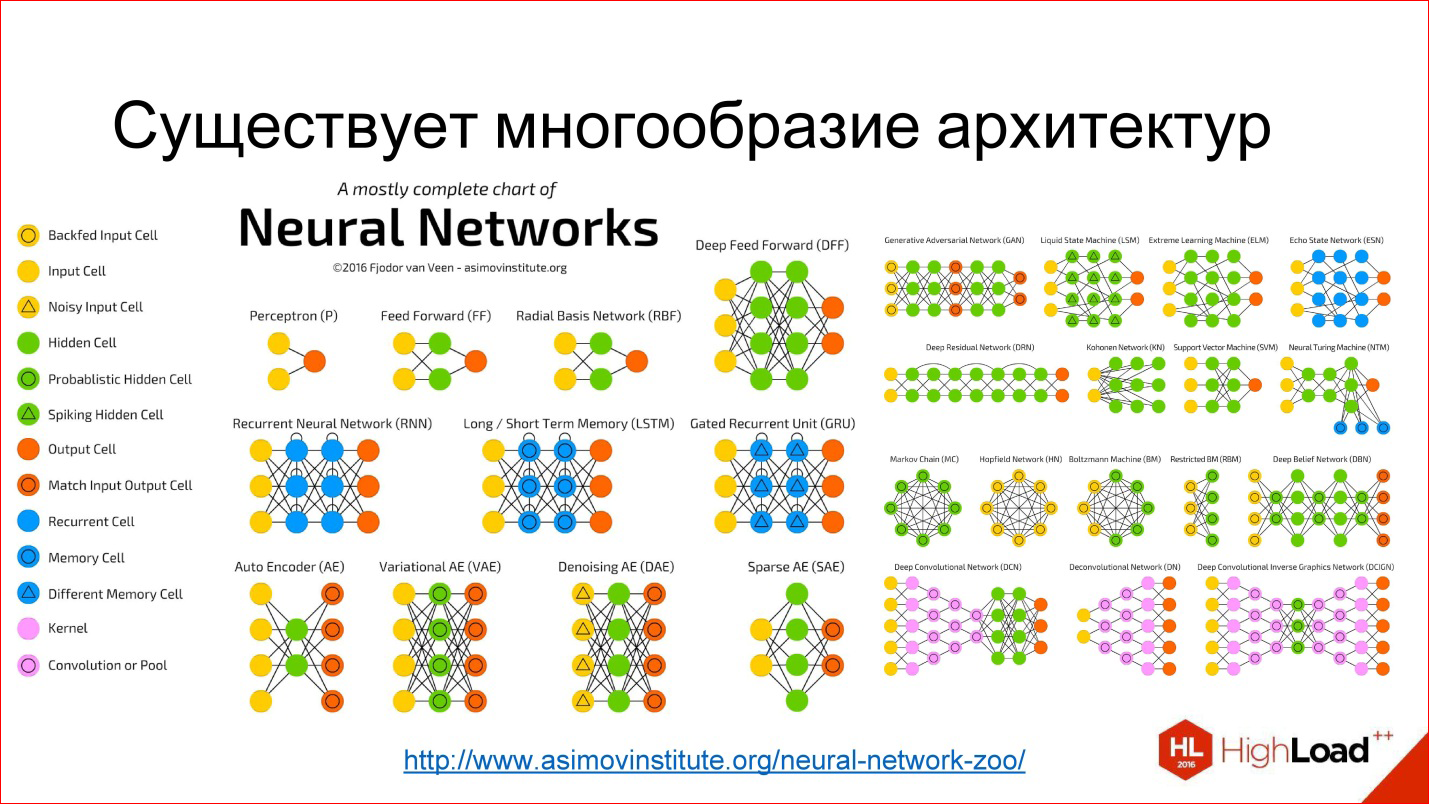
В последнее время всё чаще и чаще натыкаюсь на термин data contract. И чтобы не отставать от трендов на рынке data engineering, решил изучить эту тему и рассмотреть тенденции. Постараемся понять, с чем его кушать и стоит ли кушать вовсе.

User
В последнее время всё чаще и чаще натыкаюсь на термин data contract. И чтобы не отставать от трендов на рынке data engineering, решил изучить эту тему и рассмотреть тенденции. Постараемся понять, с чем его кушать и стоит ли кушать вовсе.

Apache Ozone: следующее поколение хранилища для платформы больших данных
Распределенная файловая система Apache Hadoop (HDFS) де-факто является файловой системой для больших данных. Верная своим корням big data, HDFS работает лучше всего, когда большинство файлов имеют большой размер - от десятков до сотен мегабайт.
Ozone - это распределенное хранилище, которое может управлять как малыми, так и большими файлами. Ozone разрабатывается и внедряется командой инженеров и архитекторов, имеющих значительный опыт управления большими кластерами Apache Hadoop. Это дало нам представление о том, что HDFS делает хорошо, и о некоторых вещах, которые можно делать по-другому.

Для запуска и эксплуатации высоконагруженных ИТ-решений с петабайтами данных в активе, нужно проработанное решение, позволяющее гибко управлять ресурсами. Одним из критичных аспектов этого решения, является разделение Compute & Storage — разделение ресурсов инфраструктуры под вычисление и хранение соответственно. Если не реализовать такое разделение в крупном проекте, инфраструктура рискует превратиться в «чемодан без ручки» — эффективность использования ресурсов будет низкой, а сложность управления ресурсами и средами будет высока. На примере команды SberData и их корпоративной аналитической платформы я расскажу, когда требуется разделение Compute & Storage и как это реализовать максимально нативно.
Статья подготовлена по мотивам доклада на VK Data Meetup «Как разделить Compute & Storage в Hadoop и не утонуть в лавине миграций».

В этой статье собрано 10 инструментов на основе искусственного интеллекта, большинство из которых просты в использовании и бесплатны для тестирования.
Всем привет! Меня зовут Маруся, я аналитик данных, веду блог в телеграме Аналитика и growth mind-set.
Практически все инструменты я использовала и была с одной стороны вдохновлена тем, насколько они упрощают работу, с другой стороны я отчетливо увидела, что эти новые инструменты уже начинают видоизменять текущие профессии и рождать совершенно новые.
Первую часть с инструментами можно почитать тут.

'По одной капле воды человек, умеющий мыслить логически, может сделать вывод о возможности существования Атлантического океана или Ниагарского водопада, даже если он не видал ни того, ни другого и никогда о них не слыхал' - Артур Конан-Дойль, «Этюд в багровых тонах».
Меня всегда восхищали древние философы, которые не имея никаких инструментов познания мира кроме собственного разума, бесстрашно погружались в пучины тайн мироздания. С помощью одних лишь только рассуждений они обретали исключительно глубокое понимание принципов работы механизма Вселенной, тем самым расширяя наши представления о мире.
Трудно переоценить влияние философии на науку, так как наука произошла именно от философии. Использующаяся для формализации процесса рассуждений математика стала первенцем философии. Даже сами слова "философия" и "математика" произошли из терминов религиозной школы одного из величайших философов античности - Пифагора. Физика, названию которой мы обязаны другому великому античному философу - Аристотелю, примерно до XVIII века именовалась натуральной философией. Ему же мы обязаны появлением логики - науки о мышлении. Кроме того, философы, изучавшие процесс познания и его ограничения, создали важнейший инструмент исследования природы - научный метод.
Даже многие научные открытия последних веков были вдохновлены философией. Иоганн Кеплер, Николай Коперник и Исаак Ньютон вдохновлялись теорией о гармонии мира Пифагора, о чем сами и писали в своих научных трудах. Альберт Эйнштейн был ярым приверженцем философии средневекового философа Бенедикта Спинозы, но также считал себя в некотором смысле платоником и пифагорейцем. Один из основоположников квантовой механики Эрвин Шрёдингер написал целую книгу о том, как его открытия в квантовой механике согласуются с индийской философией веданты.
До сих пор в западных университетах всем специалистам в точных и естественных науках, успешно защитившим свою диссертацию, присваивают почетное звание доктора философии - Philosophiæ Doctor, часто сокращаемое в речи и на письме до простого PhD. Тем самым университеты подчеркивают, что философия лежит в самом основании всего человеческого знания. Но чем именно занимается философия, в чем состоит её роль?
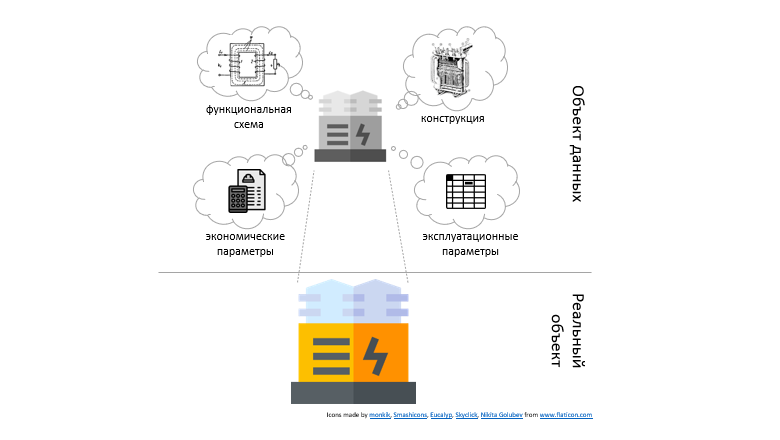
Каждая организация использует множество приложений, каждое приложение имеет свою базу данных. В этих базах хранится описание одних и тех же объектов бизнес-процессов с разных точек зрения. Это порождает необходимость в сложных, дорогих и не всегда эффективных интеграционных решениях.
Мы расскажем о дата-центрической архитектуре — «волшебной пуле», позволяющей забыть об интеграции и открыть новые возможности для создания гибких и управляемых бизнес-приложений, аналитики и монетизации данных за счет их использования при принятии решений.
Все крупные компании сейчас пытаются строить огромные централизованные хранилища данных. Или же ещё более огромные кластерные Data Lakes (как правило, на хадупе). Но мне не известно ни одного примера успешного построения такой платформы данных. Везде это боль и страдание как для тех, кто строит платформу данных, так и для пользователей. В статье ниже автор (Жамак Дегани) предлагает совершенно новый подход к построению платформы данных. Это архитектура платформы данных четвертого поколения, которая называется Data Mesh. Оригинальная статья на английском весьма объёмна и откровенно тяжело читается. Перевод так же получился немаленьким и текст не очень прост: длинные предложения, суховатая лексика. Я не стал переформулировать мысли автора, дабы сохранить точность формулировок. Но я крайне рекомендую таки продраться через этот непростой текст и ознакомиться со статьёй. Для тех, кто занимается данными, это будет очень полезно и весьма интересно.
Евгений Черный

У каждого есть мечта; я хотел бы дожить до рассвета, но знаю, что мне осталось менее трёх часов. Будет ночь, но это неважно. Умирать просто. Для этого не нужен свет. Так тому и быть: я умру при свете звёзд.
— Виктор Гюго
 Конечно, на слово мне никто верить не должен, поэтому специально для Хабра я сорвался на самолёт в Москву, чтобы пообщаться с начальником отдела разработки спецпроектов в Сбербанк-Технологиях. Вадим Сурпин потратил на меня чуть больше часа, а в этом интервью будут только самые важные мысли из нашего разговора. Кроме того, удалось уговорить Вадима подать заявку на участие в нашей конференции JBreak. Более того, Вадим — первый человек, который показался мне достойным инвайта на Хабр: vadsu (инвайт был честно заработан статьей про хакинг ChromeDriver).
Конечно, на слово мне никто верить не должен, поэтому специально для Хабра я сорвался на самолёт в Москву, чтобы пообщаться с начальником отдела разработки спецпроектов в Сбербанк-Технологиях. Вадим Сурпин потратил на меня чуть больше часа, а в этом интервью будут только самые важные мысли из нашего разговора. Кроме того, удалось уговорить Вадима подать заявку на участие в нашей конференции JBreak. Более того, Вадим — первый человек, который показался мне достойным инвайта на Хабр: vadsu (инвайт был честно заработан статьей про хакинг ChromeDriver).