В деле познания SAN столкнулся с определённым препятствием — труднодоступностью базовой информации. В вопросе изучения прочих инфраструктурных продуктов, с которыми доводилось сталкиваться, проще — есть пробные версии ПО, возможность установить их на вирутальной машине, есть куча учебников, референс гайдов и блогов по теме. Cisco и Microsoft клепают очень качественные учебники, MS вдобавок худо-бедно причесал свою адскую чердачную кладовку под названием technet, даже по VMware есть книга, пусть и одна (и даже на русском языке!), причём с КПД около 100%. Уже и по самим устройствам хранения данных можно получить информацию с семинаров, маркетинговых мероприятий и документов, форумов. По сети же хранения — тишина и мёртвые с косами стоять. Я нашёл два учебника, но купить не решился. Это "
Storage Area Networks For Dummies" (есть и такое, оказывается. Очень любознательные англоговорящие «чайники» в целевой аудитории, видимо) за полторы тысячи рублей и "
Distributed Storage Networks: Architecture, Protocols and Management" — выглядит более надёжно, но 8200р при скидке 40%. Вместе с этой книгой Ozon рекомендует также книгу «Искусство кирпичной кладки».
Что посоветовать человеку, который решит с нуля изучить хотя бы теорию организации сети хранения данных, я не знаю. Как показала практика, даже
дорогостоящие курсы могут дать на выходе ноль. Люди, применительно к SAN делятся на три категории: те, кто вообще не знает что это, кто знает, что такое явление просто есть и те, кто на вопрос «зачем в сети хранения делать две и более фабрики» смотрят с таким недоумением, будто их спросили что-то вроде «зачем квадрату четыре угла?».
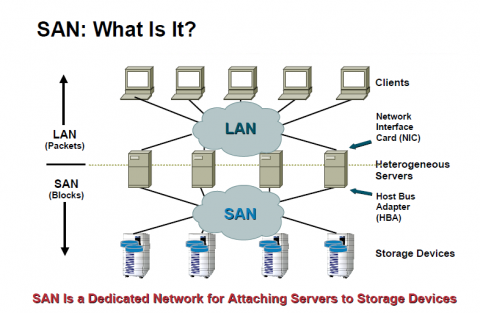
Попробую восполнить пробел, которого не хватало мне — описать базу и описать просто. Рассматривать буду SAN на базе её классического протокола — Fibre Channel.