
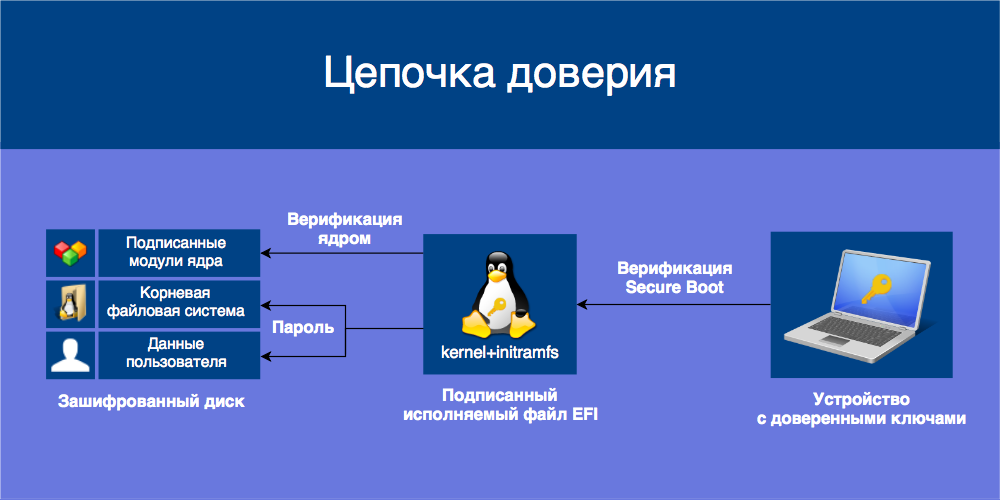
Технология Secure Boot нацелена на предотвращение исполнения недоверенного кода при загрузке операционной системы, то есть защиту от буткитов и атак типа Evil Maid. Устройства с Secure Boot содержат в энергонезависимой памяти базу данных открытых ключей, которыми проверяются подписи загружаемых UEFI-приложений вроде загрузчиков ОС и драйверов. Приложения, подписанные доверенным ключом и с правильной контрольной суммой, допускаются к загрузке, остальные блокируются.
Более подробно о Secure Boot можно узнать из цикла статей от CodeRush.
Чтобы Secure Boot обеспечивал безопасность, подписываемые приложения должны соблюдать некоторый «кодекс чести»: не иметь в себе лазеек для неограниченного доступа к системе и параметрам Secure Boot, а также требовать того же от загружаемых ими приложений. Если подписанное приложение предоставляет возможность недобросовестного использования напрямую или путём загрузки других приложений, оно становится угрозой безопасности всех пользователей, доверяющих этому приложению. Такую угрозу представляют загрузчик shim, подписываемый Microsoft, и загружаемый им GRUB.
Чтобы от этого защититься, мы установим Ubuntu с шифрованием всего диска на базе LUKS и LVM, защитим initramfs от изменений, объединив его с ядром в одно UEFI-приложение, и подпишем его собственными ключами.

 Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.
Так как карьера программиста тесно связана с процессором, неплохо бы знать как он работает.




 С этой статьей я начинаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом. Тема IDisposable была выбрана в качестве разгона, пробы пера. Вся книга будет доступна на GitHub:
С этой статьей я начинаю публиковать целую серию статей, результатом которой будет книга по работе .NET CLR, и .NET в целом. Тема IDisposable была выбрана в качестве разгона, пробы пера. Вся книга будет доступна на GitHub:  CLR Book:
CLR Book:  Релиз 0.5.2 книги, PDF:
Релиз 0.5.2 книги, PDF: 




 Напомним на всякий случай, если кто-то забыл, что GitHub – это одна из крупнейших платформ для разработки программного обеспечения и дом для многих популярных проектов с открытым исходным кодом. На страничке «
Напомним на всякий случай, если кто-то забыл, что GitHub – это одна из крупнейших платформ для разработки программного обеспечения и дом для многих популярных проектов с открытым исходным кодом. На страничке «