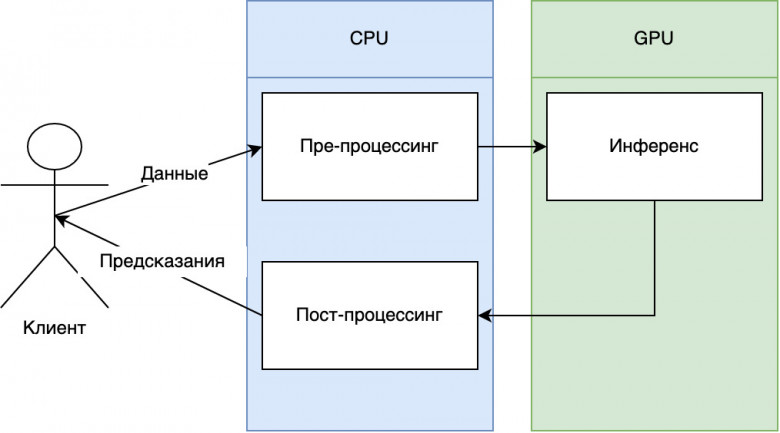
Я работаю ML-инженером в OK и последнее время занимался оптимизацией скорости инференса нейросетей, поэтому сегодня расскажу о них. И не просто о нейросетях, а о нейросетях в продакшене.

Data Scientist
Я работаю ML-инженером в OK и последнее время занимался оптимизацией скорости инференса нейросетей, поэтому сегодня расскажу о них. И не просто о нейросетях, а о нейросетях в продакшене.

Привет, Хабр! Я расскажу о трех опциональных, но довольно полезных инструментах фреймворка dash, которые сделают ваш dashbord показательным и интерактивным.

Естественный источник обратной связи для любой компании — отзывы их клиентов. И Альфа-Банк не исключение: за год мы собираем больше 100 млн оценок по различным каналам и продуктам. Но среди этих оценок очень мало содержательных текстовых комментариев, а самый популярных среди них (за 2021 год) — «Вопрос не решен!»
Чтобы решить эту проблему, Альфа-Банк собирает дополнительно до 500 тысяч отзывов в год. Этим занимается команда по сохранению лояльности клиентов: обзванивает клиентов, которые поставили негативную оценку, подробно их опрашивает, и старается решить проблему клиента на звонке, формируя свой экспертный отзыв.
Накапливаемые данные практически невозможно анализировать в ручном режиме в полном объеме, но можно сократить объем труда за счет машинного обучения. О том, как мы помогли оптимизировать процесс вычитки с помощью суммаризации на основе тематических моделей и будет эта статья.

Сталкивались ли вы с трудностями при отладке Python-кода? Если это так — то изучение того, как наладить логирование (журналирование, logging) в Python, способно помочь вам упростить задачи, решаемые при отладке.
Если вы — новичок, то вы, наверняка, привыкли пользоваться командой print(), выводя с её помощью определённые значения в ходе работы программы, проверяя, работает ли код так, как от него ожидается. Использование print() вполне может оправдать себя при отладке маленьких Python-программ. Но, когда вы перейдёте к более крупным и сложным проектам, вам понадобится постоянный журнал, содержащий больше информации о поведении вашего кода, помогающий вам планомерно отлаживать и отслеживать ошибки.
Из этого учебного руководства вы узнаете о том, как настроить логирование в Python, используя встроенный модуль logging. Вы изучите основы логирования, особенности вывода в журналы значений переменных и исключений, разберётесь с настройкой собственных логгеров, с форматировщиками вывода и со многим другим.
Вы, кроме того, узнаете о том, как Sentry Python SDK способен помочь вам в мониторинге приложений и в упрощении рабочих процессов, связанных с отладкой кода. Платформа Sentry обладает нативной интеграцией со встроенным Python-модулем logging, и, кроме того, предоставляет подробную информацию об ошибках приложения и о проблемах с производительностью, которые в нём возникают.

Про последствия пандемии для ИТ-компаний как-то не принято говорить. Считается, что среди других бизнесов именно программная разработка была лучше всего подготовлена к разобщению мира, закрытым границам и массовому выносу стульев, мониторов и ноутбуков для надомного труда. И первое время, пока вирус косил один бизнес за другим, казалось, что ИТ-сфера справляется с современными вызовами лучше всех. Спрос на программную разработку вырос, но вместе с ним обострилась проблема нехватки кадров, стали разогреваться зарплаты разработчиков, а удаленка постепенно утратила свой шарм. Пандемия сильнее ударила по ИТ, чем кажется. Мы попросили представителей индустрии рассказать о ключевых трендах двух пандемийных лет: что хорошего и плохого появилось в ИТ-индустрии из-за пандемии и могут ли стать произошедшие изменения необратимыми.

В этом году мы много работали над качеством предсказания времени в пути (ETA) в навигаторе 2ГИС и на 30% увеличили количество маршрутов, у которых прогнозное время совпадает с реальным с точностью до минуты. Меня зовут Кирилл, я Data Scientist в 2ГИС, и я расскажу, как максимально точно рассчитывать время прибытия из точки А в точку Б в условиях постоянного изменения дорожной ситуации.
Поговорим про то, как мы постепенно меняли подходы к оценке времени в пути: от простой аддитивной модели до использования ML-моделей прогноза пробок и корректировки ETA. Ввели Traversal Time на смену GPS-скоростей, а ещё проводили эксперименты и оценивали качество изменений алгоритма, чистили мусор из данных и закатывали модели в продакшн. Обо всём по порядку.

В 2022 году удаленная работа кажется настолько обыденной, что не вызывает никакого удивления. Но в начале 2020 года об удаленке многие, в том числе и авторы статьи, только мечтали (давно и много). Переход к такому формату оказался менее радужным, чем наши мечты. Выяснилось, что коммуникация по проекту с коллегами на удаленке может превратиться в квест, особенно если коллеги слишком увлечены домашними делами.
В блоге ЛАНИТ мы хотим поделиться своими наблюдениями и представляем ТОП-10 антилайфхаков удаленки. Итак, вот что точно не стоить делать, работая дистанционно.

В телепередачах и кинофильмах мы часто видим эффектный взлет истребителей в ночное небо, как из сопла двигателей рвется раскаленное пламя с температурой выше 1100 градусов и не задумываемся, какие же материалы могут работать в этой раскаленной среде. Такие металлические сплавы существуют, и разработка их началась еще в 30-е годы прошлого века. Сегодня в блоге ЛАНИТ я расскажу о некоторых вариантах разработки составов таких сплавов.

С 15 по 24 августа в Москве в восьмой раз пройдет международный фестиваль документального кино «Докер». С 2016 года ЛАНИТ поддерживает «Докер» и вместе с оргкомитетом проводит единственный в мире конкурс фильмов об информационных технологиях – «Let IT dok!».
В этом году документалисты продолжают исследовать и фиксировать, что происходит с нашей жизнью, в которую все глубже проникают цифровые технологии. В этой статье мы подробнее расскажем о каждом фильме-финалисте программы «Let IT dok!». Увидеть их на большом экране можно будет в кинотеатре «Октябрь» на Новом Арбате в дни проведения фестиваля.

Во многих популярных курсах машинного и глубокого обучения вас научат классифицировать собак и кошек, предсказывать цены на недвижимость, покажут еще десятки задач, в которых машинное обучение, вроде как, отлично работает. Но вам расскажут намного меньше (или вообще ничего) о тех случаях, когда ML-модели не работают так, как ожидалось.
Частой проблемой в машинном обучении является неспособность ML-моделей корректно работать на большем разнообразии примеров, чем те, что встречались при обучении. Здесь идет речь не просто о других примерах (например, тестовых), а о других типах примеров. Например, сеть обучалась на изображениях коровы, в которых чаще всего корова был на фоне травы, а при тестировании требуется корректное распознавание коровы на любом фоне. Почему ML-модели часто не справляются с такой задачей и что с этим делать – мы рассмотрим далее. Работа над этой проблемой важна не только для решения практических задач, но и в целом для дальнейшего развития ИИ.

Сегодня разбираемся, как создавать собственные преобразователи Sklearn, позволяющие интегрировать практически любую функцию или преобразование данных в классы конвейера Sklearn. Подробности под катом к старту флагманского курса по Data Science.

Чтобы исправить кое-какие ошибки, человечество решило отправиться в прошлое. Для этого надо найти правильную кротовую нору — просторную, но не слишком гравитирующую и по приемлемой цене — чтобы забронировать телепортацию.
В космосе россыпи всяческих дыр и нор, по которым вдобавок катаются клубки перепутанных суперструн: вручную такое не проанализировать. Поэтому тут не обойтись без специалиста по большим данным.
Твоё резюме было таким убедительным, что эксперты из Академии больших данных MADE и VK Образования решили провести собеседование прямо на космическом шаттле. Ответь на вопросы, подтверди свою квалификацию и помоги капитану определить маршрут. Поехали!

Наверняка вы мечтали поговорить с великим философом: задать ему вопрос о своей жизни, узнать его мнение или просто поболтать. В наше время это возможно за счет чат-ботов, которые поддерживают диалог, имитируя манеру общения живого человека. Подобные чат-боты создаются благодаря технологиям обработки естественного языка и генерации текста. Уже сейчас существуют обученные модели, которые неплохо справляются с данной задачей.
В этой статье я расскажу о своем опыте обучения алгоритма генерации текста, основанного на высказываниях великих личностей. В датасете для обучения модели используются цитаты десяти известных философов, писателей и ученых.
В этой статье я расскажу, как мы командой пилили пет-проджект в рамках курса ODS по MLOps. Покажу не только финальный результат, но и немного расскажу про процесс работы, какие были сложности, как организовывали эффективную работу в команде. Может оказаться полезным для тех, кто хочет окунуться в Machine Learning и сделать свой пет-проджект, но пока чего-то не хватало. Также будет полезно тем, кто уже работает в области Data Science, но пока не окунулся в атмосферу DS, нет крутых коллег и разгвооров про фреймворки у кофемашины, а опыт командной работы именно в области DS получить хочется.
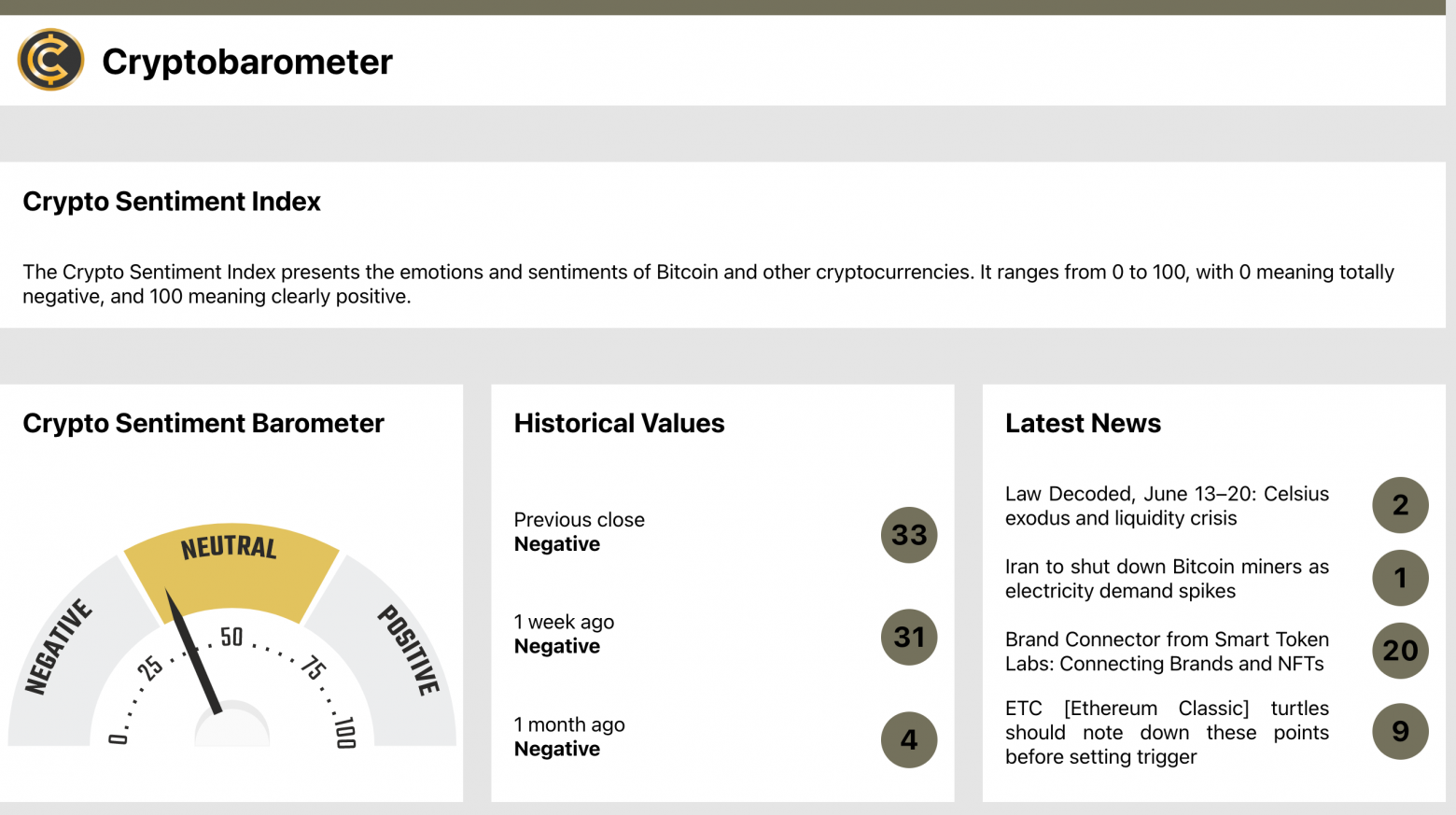
Сразу про то, что получилось на выходе: https://cryptobarometer.org/
В этой статье мы поговорим о ранжирующих (retrieval) моделях диалоговых систем, и методах их персонификации.
Данный текст не является подробной и всеобъемлющей, пошаговой инструкцией по созданию диалогового агента и не претендует на большую научную ценность. Эта статья, скорее, представляет собой краткий обзор существующих методов и инструментов, применяющихся в наши дни и единственная ее задача - заинтересовать читателя и дать начальное представление о такого рода моделях оставив большой простор для собственных экспериментов.
Краткий список всего необходимого: базовое знания Python и PyTorch (если вы являетесь адептом TensorFlow, не пугайтесь, здесь будут показаны общие приемы, которые легко реализовать в других библиотеках), желательно знание библиотеки transformers, а также полезным будет минимальный опыт написания ботов для telegram (это, совершенно, не обязательно, ведь, с ботом можно общаться и в терминале) Ну что ж если вы готовы, то мы отправляемся в наше небольшое путешествие по миру диалоговых моделей.

Всем известный закон Мёрфи гласит: «Если что-то плохое может случиться, то оно обязательно произойдет». Согласитесь, не самая позитивная установка, особенно когда это касается работы. И тут мне стало любопытно, а есть ли такие законы, которые мне, как ИТ-специалисту, максимально помогут избежать «чего-то плохого». К своему удивлению, я их нашел, и даже не один. Потому делюсь с вами сегодня своими сакральными знаниями в блоге ЛАНИТ.

Традиционно рынок спортивных событий воспринимается обществом весьма негативно. Принято считать, что какой-либо заработок в этой области маловероятен или невозможен вовсе, а мат. аппарат в лице теории вероятностей и математической статистики представляет мало интереса с точки зрения эффективного для заработка применения.
В какой-то мере такая позиция является обоснованной, ведь эффективность исследования этого рынка напрямую определяется пониманием, достичь которого не так просто. Сегодня мы с вами рассмотрим рынок спортивных событий под абсолютно новым углом, сделав акцент на системности и распределениях, а за одним и узнаем, при чём же здесь печатный станок.

В предыдущих материалах из этой серии мы рассказали о том, что такое обучение с подкреплением (Reinforcement learning, RL), поговорили о том, почему это важно, разобрались с математическим аппаратом, используемым для создания RL-агентов.

В предыдущем материале из этой серии мы рассказали о сетях Deep Q (Deep Q Network, DQN) и написали алгоритм их обучения на псевдокоде. Хотя такие сети, в принципе, работоспособны, практическая реализация алгоритмов обучения с подкреплением (Reinforcement Learning, RL), выполняемая без понимания их ограничений, может вести к нестабильности создаваемых систем и к плохим результатам обучения. В этом материале мы обсудим два важных ограничения, две проблемы, способных привести к нестабильности Q-обучения. Мы поговорим и о том, как, на практике, решать эти проблемы. Вспомните о том, что уравнение Беллмана связывает, с помощью рекурсии, Q-функции для текущего и следующего временных шагов.