Яндекс, как и любая другая большая интернет-компания, хранит много, а точнее очень много данных. Это и пользовательские данные из разных сервисов, и намайненные сайты, и промежуточные данные для расчёта погоды, и резервные копии баз данных. Стоимость хранения ($/ГБ) — один из важных показателей системы. В этой статье я хочу рассказать вам про один из методов, который позволил нам серьезно удешевить хранилище.

В 2015 году, как вы все помните, сильно вырос курс доллара. Точнее, расти-то он начал в конце 2014-го, но новые партии железа мы заказывали уже в 2015-м. Яндекс зарабатывает в рублях, и поэтому вместе с курсом выросла и стоимость железа для нас. Это заставило нас в очередной раз подумать о том, как сделать, чтобы в текущий кластер можно было положить больше данных. Мы такое, конечно, делаем регулярно, но в этот раз мотивация была особенно сильной.
Каждый сервер кластера предоставляет для нас следующие ресурсы: процессор, оперативную память, жёсткие диски и сеть. Сеть здесь — более сложное понятие, чем просто сетевая плата. Это ещё и вся инфраструктура внутри дата-центра, и связность между разными дата-центрами и точками обмена трафиком. В кластере для обеспечения надёжности применялась репликация, и суммарный объём кластера определялся исключительно через суммарную ёмкость жёстких дисков. Нужно было придумать, как обменять оставшиеся ресурсы на увеличение места. Кстати, если после поста у вас останутся вопросы, которые бы вы хотели обсудить лично, приходите на нашу встречу.


 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.




 Цвет, безусловно, является важным источником эмоции. Цвета могут устанавливать правильный тон и передавать необходимые эмоции посетителям, могут взволновать, вызвать множество чувств и стимулировать к действиям. Он является чрезвычайно мощным фактором воздействия на пользователей.
Цвет, безусловно, является важным источником эмоции. Цвета могут устанавливать правильный тон и передавать необходимые эмоции посетителям, могут взволновать, вызвать множество чувств и стимулировать к действиям. Он является чрезвычайно мощным фактором воздействия на пользователей.



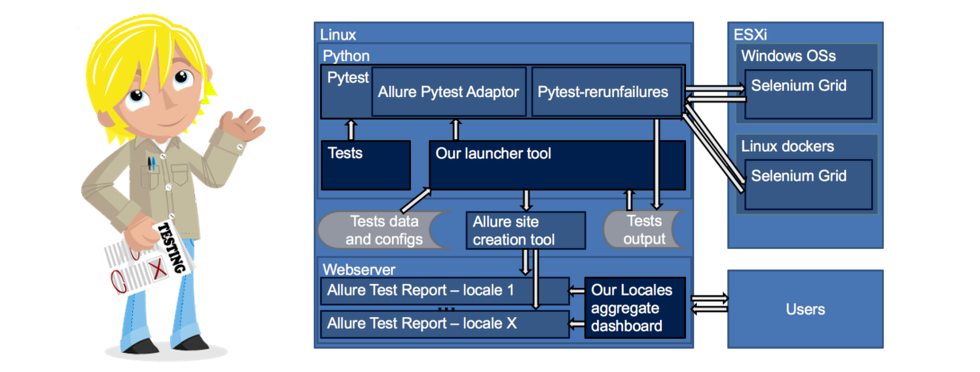
 Итак, Игорь Хрол — специалист по автоматизации тестирования в Toptal. Игорь имеет большой опыт работы с большинством популярных инструментов (Selenium, HP QTP, TestComplete, JMeter).
Итак, Игорь Хрол — специалист по автоматизации тестирования в Toptal. Игорь имеет большой опыт работы с большинством популярных инструментов (Selenium, HP QTP, TestComplete, JMeter). 