Я люблю читать Хабр (а также ЖЖ, roem.ru, новости рамблера и ещё много чего) на своей любимой электронной книге
Nook и, изредка, на своём мобильном на андроиде. На читалке я читаю, чтобы не портить глаза, и не напрягаться лишний раз, сидя за компьютером, а на мобильном от безысходности стоя в какой-нибудь очереди.
Я сделал страницу
readitlaterlist.com/unread (сервис из серии «прочту позже») домашней на моей читалке, поставил приложение на мой телефон, и удобно добавляю топики с Хабра (ЖЖ и прочих), которые хочу почитать на читалке, с помощью
плагина для Firefox'а.
Казалось бы, всё замечательно, но вот беда: обычная версия Хабра грузится в браузере моего Нука больше минуты, притормаживает и из-за вёрстки под обычные экраны необходимо вручную центровать колонку с текстом. Впрочем, неудобства я испытывал с большинством полноразмерных страниц различных СМИ и блогов.
Я пробовал мигрировать на
Instapaper, т.к. он поддерживает выгрузку в epub и mobi (можно даже слать себе на email, например, для автоподгрузки на Kindle), но и тут проблема: все сервисы при вытаскивании текста статьи с Хабра режут комментарии (Хабр без комментариев?!?!).
В конце-концов, я пришёл к тому, что перед отправкой в ReadItLater я вручную правил url поста на хабре, чтобы переключиться на мобильную версию этого поста (сейчас это лишь добавить
m., а раньше приходилось удалять
/<имя блога>/, ставить
posts, а также добавлять
m.). А на сайтах СМИ я выискивал ссылки вида «версия для печати» или «версия для PDA».

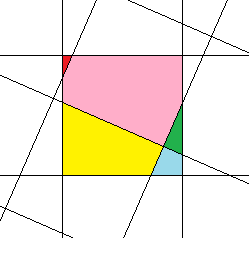 Довольно давно, из чисто спортивного интереса, меня заинтересовала задача максимально точного поворота растрового изображения на произвольный угол. К сожалению, мне нигде не удалось найти готовый алгоритм, поэтому пришлось делать его собственноручно. Даже если в итоге я «изобрёл велосипед», результат, как мне кажется, получился достаточно интересным, чтобы им можно было поделиться.
Довольно давно, из чисто спортивного интереса, меня заинтересовала задача максимально точного поворота растрового изображения на произвольный угол. К сожалению, мне нигде не удалось найти готовый алгоритм, поэтому пришлось делать его собственноручно. Даже если в итоге я «изобрёл велосипед», результат, как мне кажется, получился достаточно интересным, чтобы им можно было поделиться.

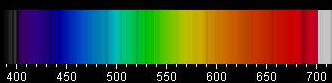 Часто (в том числе и на хабре) всплывает вопрос освещения, особенно
Часто (в том числе и на хабре) всплывает вопрос освещения, особенно