Только что вернулся с конференции
ПАВТ 2011 и хотел бы познакомить уважаемое хабрасообщество с современным состоянием дел в области высокопроизводительных вычислений.
Постараюсь по возможности ссылаться на первоисточники — а именно, на статьи из журнала "
Суперкомпьютеры" и
материалы конференции.
Зачем это все нужно
Суперкомпьютеры традиционно использовались в военных и научных целях, но в последние годы в их применении произошли революционные изменения, связанные с тем, что их мощность «доросла» до моделирования реальных процессов и предметов при доступной для бизнеса стоимости.
Все, наверное, знают, что в автомобилестроении расчеты на суперкомпьютерах используются для повышения безопасности, например так получил свои
5 звезд Ford Focus. В авиапромышленности выпуск нового реактивного двигателя по традиционной технологии — дорогостоящее удовольствие, например создание АЛ-31 для СУ-27 заняло 15 лет, потребовало создать и разрушить 50 опытных экземпляров и стоило 3,5 млрд. долларов.
Двигатель для Сухой Супержет, спроектированный уже с участием суперкомпьютеров, сделали за 6 лет, 600 млн евро и было построено 8 опытных экземпляров.
Нельзя не отметить и фармацевтику — большая часть современных лекарств проектируется с помощью
виртуального скрининга , который позволяет радикально снизить затраты и повысить безопасность лекарств.
Дальше — больше.
Сегодня в развитых европейских странах:
47,3% высокотехнологической продукции производится с использованием имитационного моделирования фрагментов проектируемых сложных систем или изделий;
32,3% продукции производится с использованием имитационного моделирования мелкомасштабных аналогов проектируемых систем и изделий;
15% продукции производится с использованием полномасштабного имитационного моделирования проектируемых систем и изделий;
и лишь 5,4% проектируемых сложных систем и изделий производится без имитационного моделирования.
Суперкомпьютерные технологии в современном мире стали стратегической областью, без которой невозможно дальнейшее развитие. Мощность национальных суперкомпьютеров сейчас так же важна, как мощность электростанций или количество боеголовок.
И сейчас в мире началась

 В последние несколько дней по интернету стали ходить статьи с заголовками вроде “Dropbox небезопасен”, “Обнаружена серьезная уязвимость в Dropbox” и т.п. Я, как пользователь дропбокса, решил разобраться, в чем же тут дело. Русскоязычные источники информации, как это обычно бывает, пестрят громкими заявлениями в духе “Все пропало!!!!!!!!”, а ссылку на первоисточник указывать считают дурным тоном. Под катом я расскажу, как дело обстоит на самом деле.
В последние несколько дней по интернету стали ходить статьи с заголовками вроде “Dropbox небезопасен”, “Обнаружена серьезная уязвимость в Dropbox” и т.п. Я, как пользователь дропбокса, решил разобраться, в чем же тут дело. Русскоязычные источники информации, как это обычно бывает, пестрят громкими заявлениями в духе “Все пропало!!!!!!!!”, а ссылку на первоисточник указывать считают дурным тоном. Под катом я расскажу, как дело обстоит на самом деле.


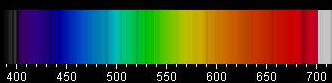 Часто (в том числе и на хабре) всплывает вопрос освещения, особенно
Часто (в том числе и на хабре) всплывает вопрос освещения, особенно