Прим. перев.: эта поучительная история Omio — европейского агрегатора путешествий — проводит читателей от базовой теории до увлекательных практических тонкостей в конфигурации Kubernetes. Знакомство с такими случаями помогает не только расширять кругозор, но и предотвращать нетривиальные проблемы.
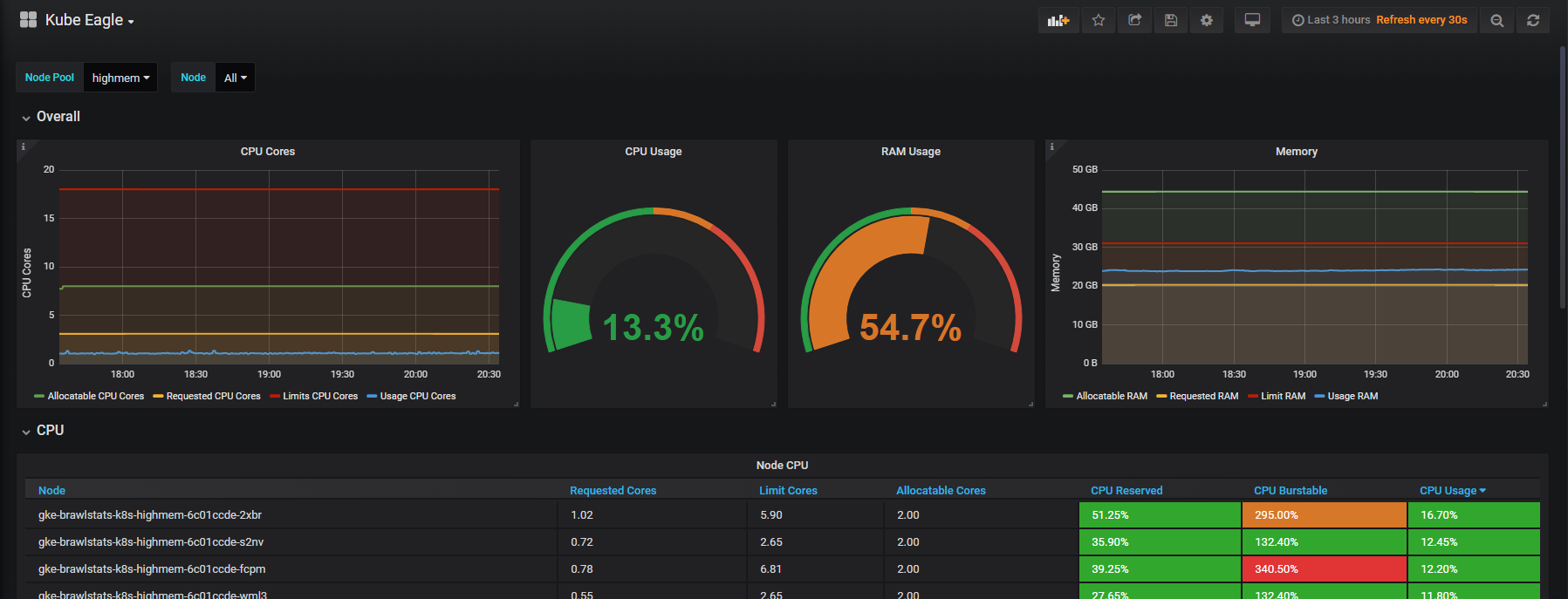
Доводилось ли вам сталкиваться с тем, что приложение «застревало» на месте, переставало отвечать на запросы о проверке состояния (health check'и) и вы не могли понять причину такого поведения? Одно из возможных объяснений связано с лимитом квот на ресурсы CPU. О нем и пойдет речь в этой статье.
TL;DR:
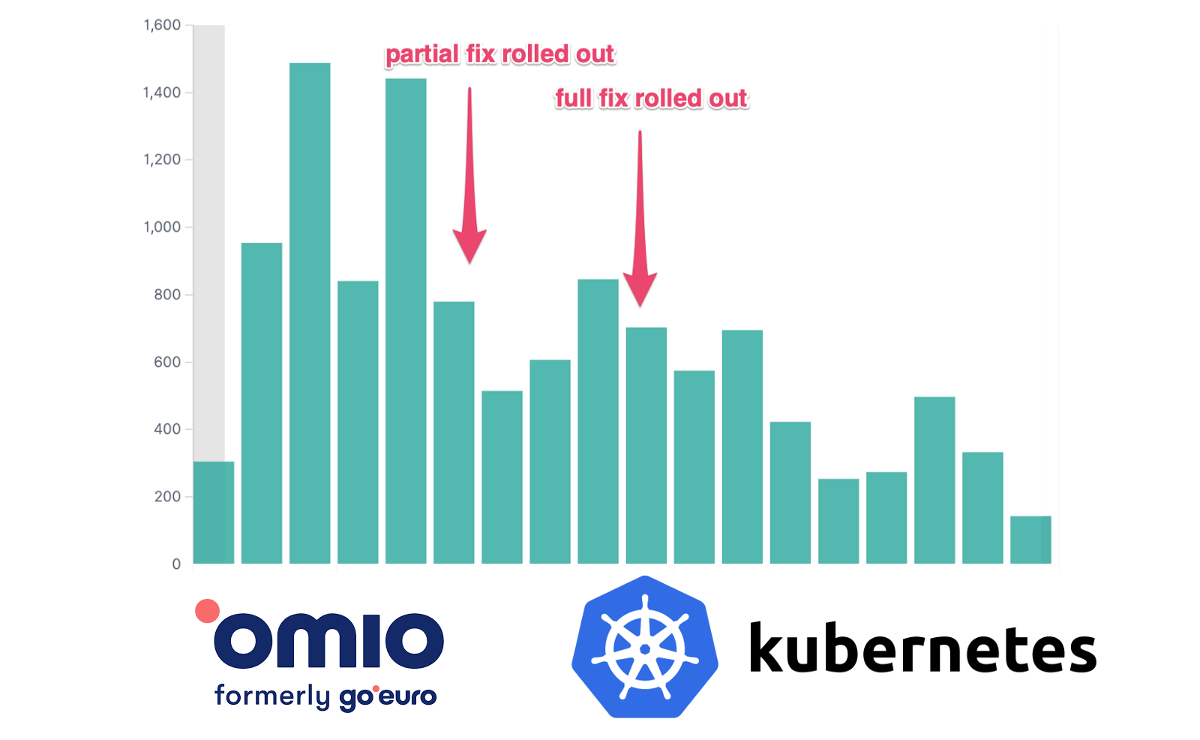
Мы настоятельно рекомендуем отказаться от CPU limit'ов в Kubernetes (или отключить квоты CFS в Kubelet), если используется версия ядра Linux с ошибкой CFS-квот. В ядре имеется серьезный и хорошо известный баг, который приводит к избыточному троттлингу и задержкам.
Доводилось ли вам сталкиваться с тем, что приложение «застревало» на месте, переставало отвечать на запросы о проверке состояния (health check'и) и вы не могли понять причину такого поведения? Одно из возможных объяснений связано с лимитом квот на ресурсы CPU. О нем и пойдет речь в этой статье.
TL;DR:
Мы настоятельно рекомендуем отказаться от CPU limit'ов в Kubernetes (или отключить квоты CFS в Kubelet), если используется версия ядра Linux с ошибкой CFS-квот. В ядре имеется серьезный и хорошо известный баг, который приводит к избыточному троттлингу и задержкам.