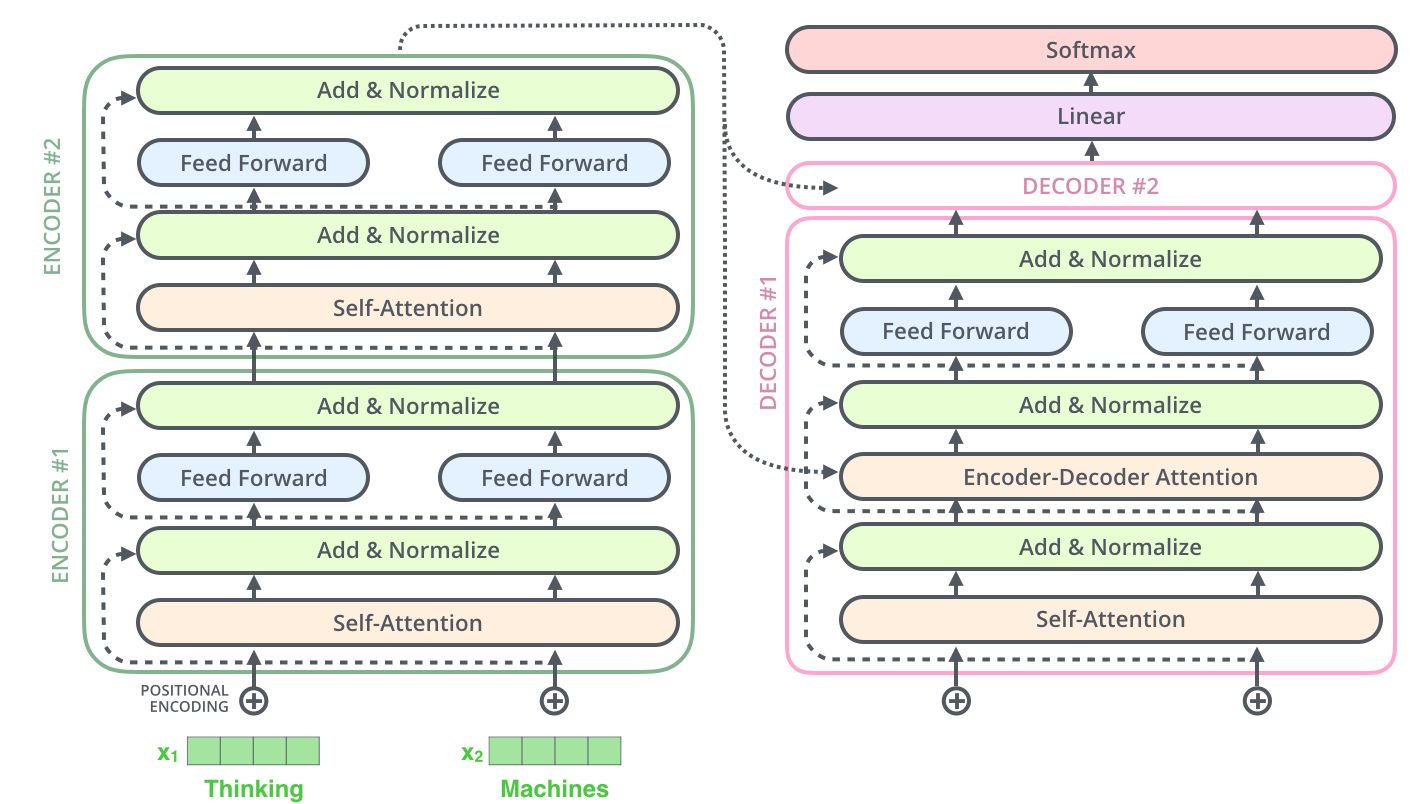
Мы живём в эпоху LLM — компании применяют на практике всё более крупные модели с миллиардами параметров. Это здорово, потом что большие модели открывают пользователям сервисов новые возможности, но не всё так просто. Размер накладывает ограничения — запускать такие модели очень дорого, а на пользовательских компьютерах — ещё дороже и сложнее. Поэтому часто исследователи и инженеры сначала обучают большую модель, а потом придумывают, как сжать её с минимальными потерями качества, чтобы сделать доступнее.
Модели выкладываются в формате float16, где на один вес выделяется 16 бит. Два года назад человечество научилось хорошо сжимать нейросети до 4 бит с помощью таких методов, как GPTQ. Но на этом исследователи не остановились, и сейчас актуальная задача — сжатие моделей до 2 бит, то есть в 8 раз.
Недавно исследователи Yandex Research совместно с коллегами из IST Austria и KAUST предложили новый способ сжатия моделей в 8 раз с помощью комбинации методов AQLM и PV-tuning, который уже доступен разработчикам и исследователям по всему миру — код опубликован в репозитории GitHub. Специалисты также могут скачать сжатые с помощью наших методов популярные опенсорс-модели. Кроме того, мы выложили обучающие материалы, которые помогут разработчикам дообучить уменьшенные нейросети под свои сценарии.
О том, как исследователи пришли к сегодняшним результатам, мы расскажем на примере двух «конкурирующих» команд и их state-of-the-art алгоритмов сжатия — QuIP и AQLM. Это короткая, но увлекательная история «противостояния» исследователей, в которой каждые пару месяцев случаются новые повороты, появляются оптимизации и оригинальные подходы к решению проблем.