Описание алгоритмов сортировки и сравнение их производительности
24 мин
Вступление
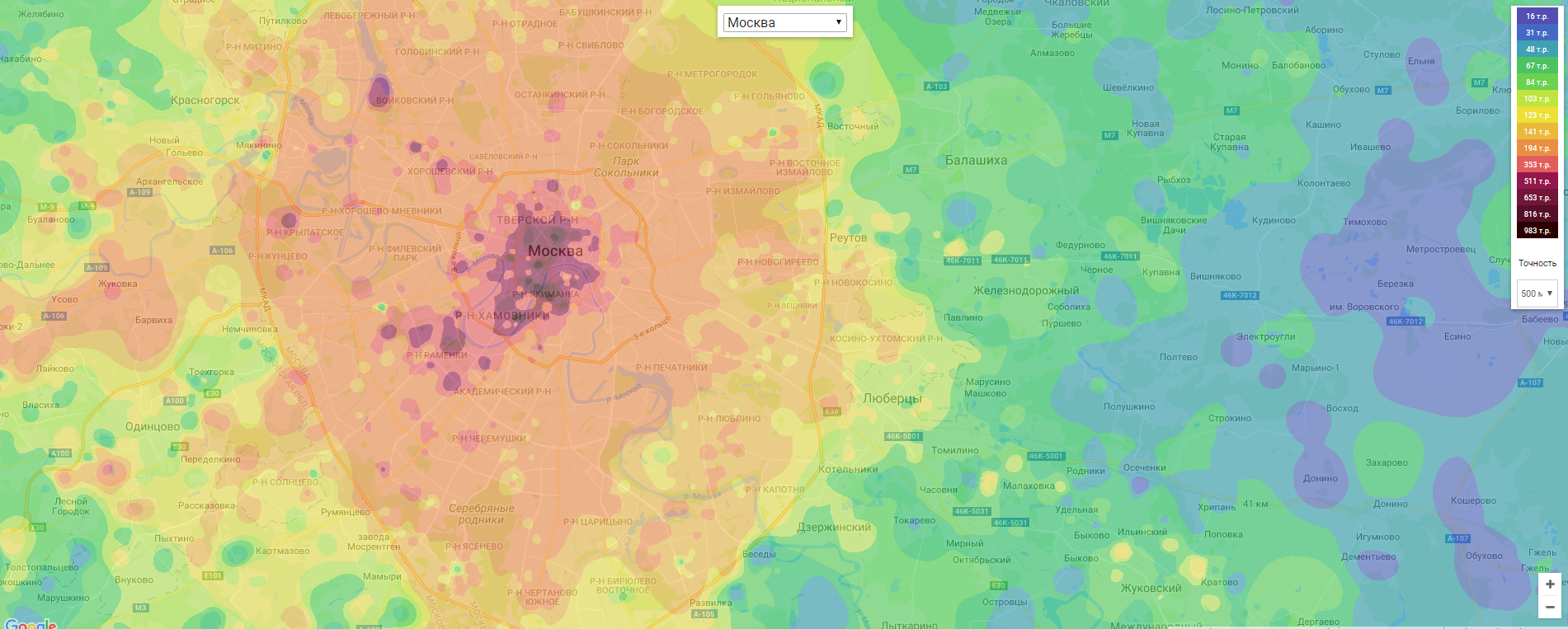
На эту тему написано уже немало статей. Однако я еще не видел статьи, в которой сравниваются все основные сортировки на большом числе тестов разного типа и размера. Кроме того, далеко не везде выложены реализации и описание набора тестов. Это приводит к тому, что могут возникнуть сомнения в правильности исследования. Однако цель моей работы состоит не только в том, чтобы определить, какие сортировки работают быстрее всего (в целом это и так известно). В первую очередь мне было интересно исследовать алгоритмы, оптимизировать их, чтобы они работали как можно быстрее. Работая над этим, мне удалось придумать эффективную формулу для сортировки Шелла.
Во многом статья посвящена тому, как написать все алгоритмы и протестировать их. Если говорить о самом программировании, то иногда могут возникнуть совершенно неожиданные трудности (во многом благодаря оптимизатору C++). Однако не менее трудно решить, какие именно тесты и в каких количествах нужно сделать. Коды всех алгоритмов, которые выложены в данной статье, написаны мной. Доступны и результаты запусков на всех тестах. Единственное, что я не могу показать — это сами тесты, поскольку они весят почти 140 ГБ. При малейшем подозрении я проверял и код, соответствующий тесту, и сам тест. Надеюсь, что статья Вам понравится.