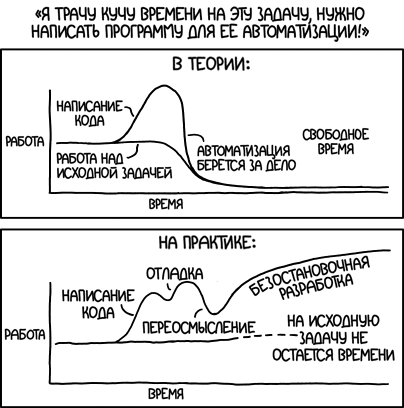
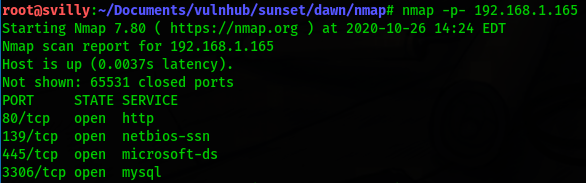
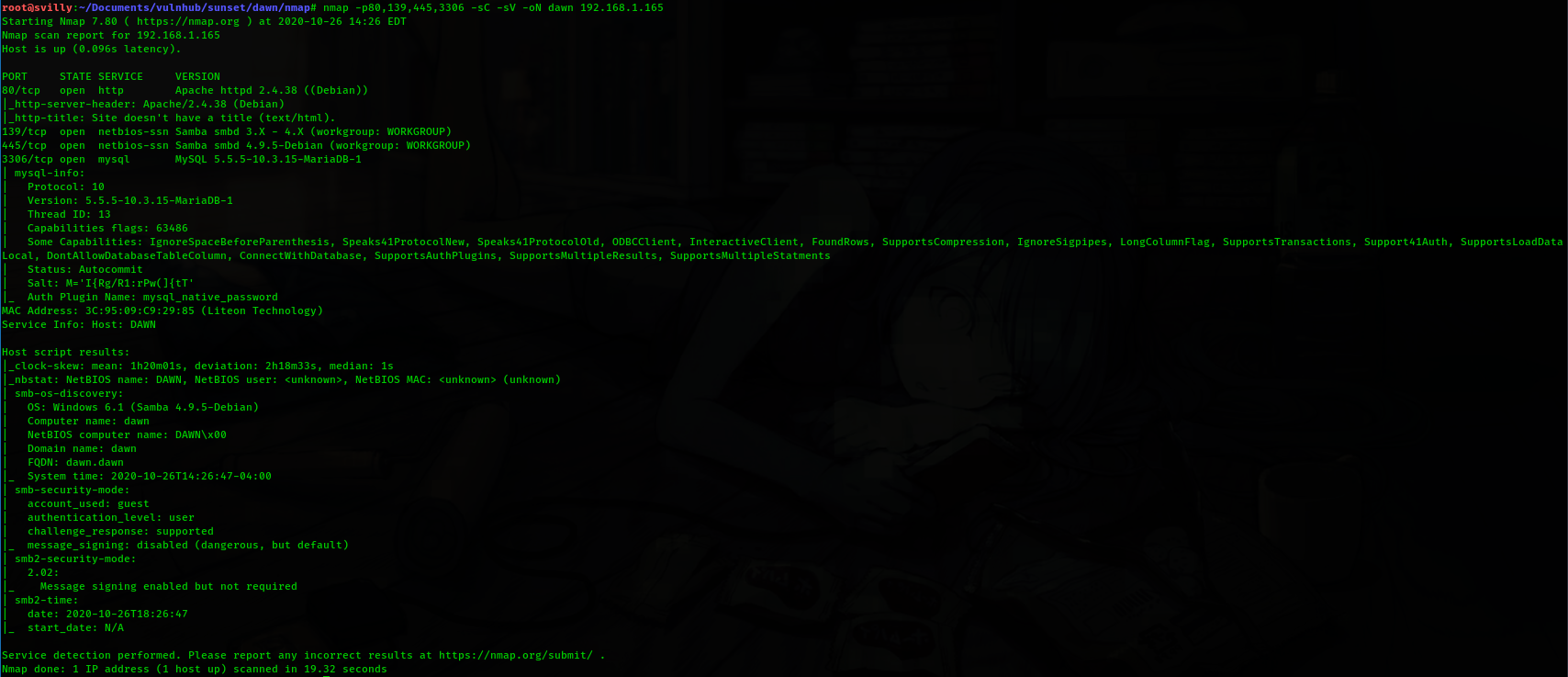
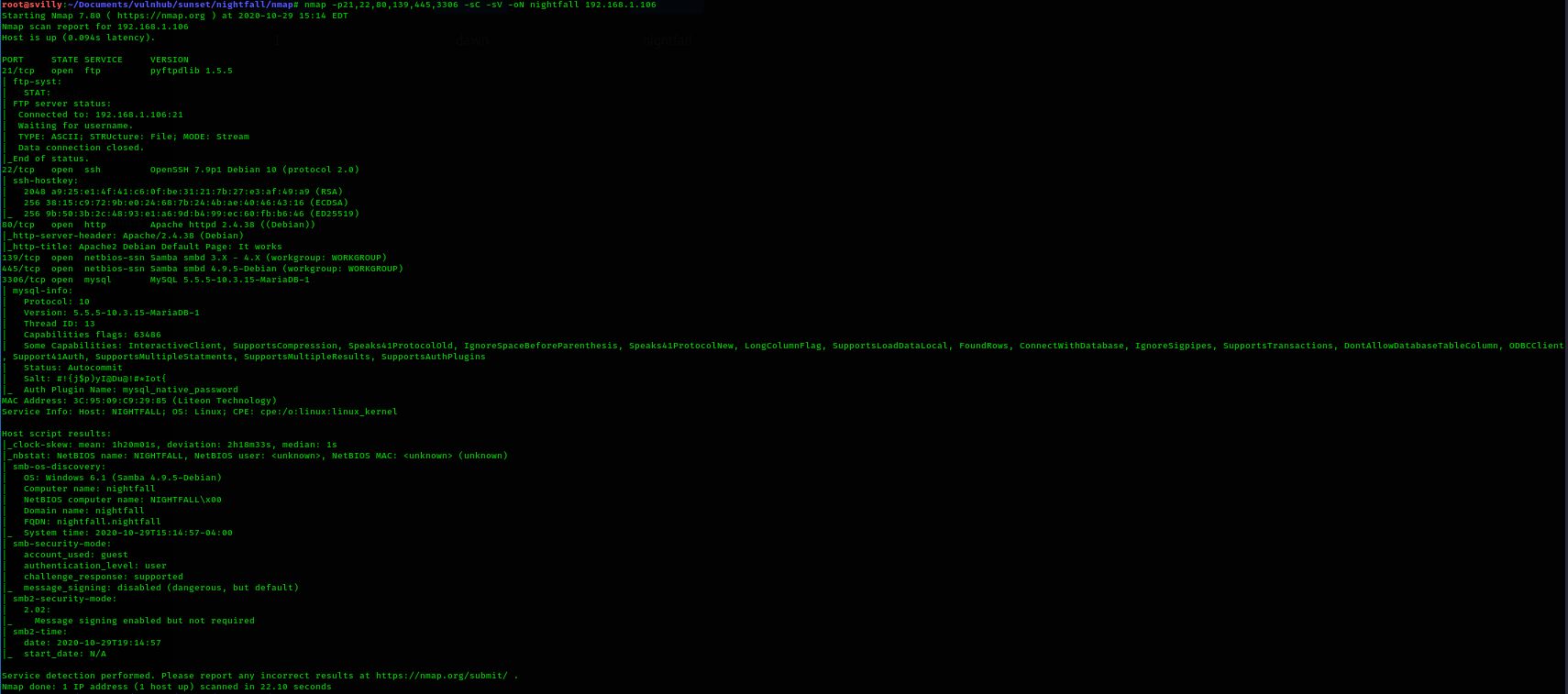
Многие слышали про AutoGPT и GPT Engineer — агентные системы, которые позволяют генерировать код по промпту от пользователя. Меня зовут Евгений Кокуйкин. Я руководитель AI продуктов компании Raft. Сегодня расскажу про Replit Agent — AI Copilot для написания кода без знаний в программировании. Без шуток! Раньше у меня на такие прототипы уходили часы кодинга и отладки. А сейчас я сгенерировал код приложения через агент — быстрее, чем писал эту статью. Так что теперь можно участвовать в хакатоне, не зная Python.
Replit — это онлайн-IDE, где с помощью AI можно быстро создать прототип приложения и задеплоить его прямо в облаке. Недавно вышла экспериментальная фича Replit Agent, которая стоит 25 баксов. Правда, для оплаты потребуется зарубежная карта, но это уже каждый сам решает, стоит заморачиваться или нет. Эта фича позволяет начать генерацию проекта одним промптом. Я так вдохновился постом Степана Гершуни, что тестировал кодинг-агента в Replit, а потом не спал всю ночь, записывая впечатления. Так появился этот обзор.