Оптимизация кода: память
Сложный
12 мин
Большинство программистов представляют вычислительную систему как процессор, который выполняет инструкции, и память, которая хранит инструкции и данные для процессора. В этой простой модели память представляется линейным массивом байтов и процессор может обратиться к любому месту в памяти за константное время. Хотя это эффективная модель для большинства ситуаций, она не отражает того, как в действительности работают современные системы.
В действительности система памяти образует иерархию устройств хранения с разными ёмкостями, стоимостью и временем доступа. Регистры процессора хранят наиболее часто используемые данные. Маленькие быстрые кэш-памяти, расположенные близко к процессору, служат буферными зонами, которые хранят маленькую часть данных, расположеных в относительно медленной оперативной памяти. Оперативная память служит буфером для медленных локальных дисков. А локальные диски служат буфером для данных с удалённых машин, связанных сетью.
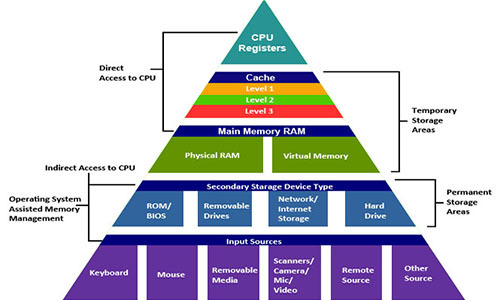
Иерархия памяти работает, потому что хорошо написанные программы имеют тенденцию обращаться к хранилищу на каком-то конкретном уровне более часто, чем к хранилищу на более низком уровне. Так что хранилище на более низком уровне может быть медленнее, больше и дешевле. В итоге мы получаем большой объём памяти, который имеет стоимость хранилища в самом низу иерархии, но доставляет данные программе со скоростью быстрого хранилища в самом верху иерархии.
В действительности система памяти образует иерархию устройств хранения с разными ёмкостями, стоимостью и временем доступа. Регистры процессора хранят наиболее часто используемые данные. Маленькие быстрые кэш-памяти, расположенные близко к процессору, служат буферными зонами, которые хранят маленькую часть данных, расположеных в относительно медленной оперативной памяти. Оперативная память служит буфером для медленных локальных дисков. А локальные диски служат буфером для данных с удалённых машин, связанных сетью.
Иерархия памяти работает, потому что хорошо написанные программы имеют тенденцию обращаться к хранилищу на каком-то конкретном уровне более часто, чем к хранилищу на более низком уровне. Так что хранилище на более низком уровне может быть медленнее, больше и дешевле. В итоге мы получаем большой объём памяти, который имеет стоимость хранилища в самом низу иерархии, но доставляет данные программе со скоростью быстрого хранилища в самом верху иерархии.






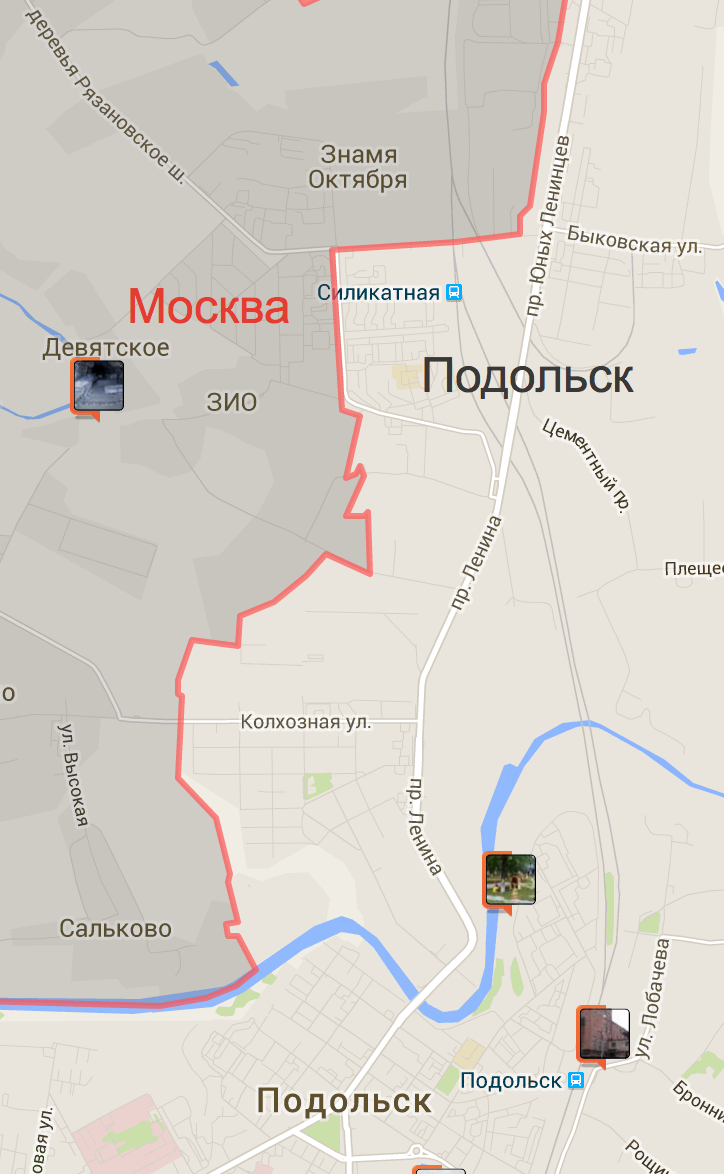 В подмосковном Подольске, в микрорайоне Силикатная-2, есть один лайфхак — когда на дворе уже 9 вечера, и пиво в магазинах уже не продают — достаточно просто перейти дорогу, чтобы его купить. Через дорогу Москва — в ней желаемое до 11 найти можно.
В подмосковном Подольске, в микрорайоне Силикатная-2, есть один лайфхак — когда на дворе уже 9 вечера, и пиво в магазинах уже не продают — достаточно просто перейти дорогу, чтобы его купить. Через дорогу Москва — в ней желаемое до 11 найти можно.