Желание познакомиться с сопроцессором Xeon Phi возникло давно, но то все не было возможности, то времени. В конце концов чудо свершилось и добрался до предмета вожделения. К сожалению, в руки попала далеко не самая последняя модель – 5110P, но для первого знакомства сойдет. Имея опыт работы с CUDA, меня очень интересовал вопрос отличий между программированием для GPU и сопроцессора. Вторым вопросом был: «А что (кроме дополнительной головной боли) я буду иметь используя сей девайс вместо GPU или CPU?».

Dmitry Spodarets @m31
Head of R&D at V.I.Tech
Bash скрипт для создания архива данных
12 min
На днях озадачился резервным копированием данных в облако. Нашёл подходящий сервис попробовал, и понял, что существует необходимость в сжатии бэкапа перед отправкой (думаю нет необходимости объяснять зачем). Не стал заморачиваться в поиске готовых решений и решил сам написать скромный скриптик для этой цели. Исходные файл или папка жмутся в .tar.xz с уровнем сжатия 9, что позволяет сохранить права и выдаёт хорошую компрессию на выходе (у меня снэпшот системы сжимается 4 раза). Результатом остался доволен, думаю для малого бизнеса, да и для личных целей многим пригодиться.
Возможности скрипта:
Возможности скрипта:
- гибкая настройка
- проверка на доступность ресурсов (источник, директория назначения, рабочая директория)
- проверка на файл блокировки (предотвращает выполнение если источник еще создаётся)
- вывод информации о сжатии (размер источника, размер архива, соотношение этих размеров)
- логирование и дебагинг (вывод дополнительной информации о процессе выполнения)
- возможность менять вывод (как в консоль и лог-файл, так и только в лог-файл)
- сохраняет и ротирует предыдущие архивы
- возможность форматирования текста вывода
- отправка e-mail-а в случае успешного и/или неуспешного завершения
Как за месяц сильно прокачаться в Data Science
12 min
Привет, хабр!

Меня зовут Глеб, я долгое время работаю в ритейловой аналитике и сейчас занимаюсь применением машинного обучения в данной области. Не так давно я познакомился с ребятами из MLClass.ru, которые за очень короткий срок довольно сильно прокачали меня в области Data Science. Благодаря им, буквально за месяц я стал активно сабмитить на kaggle. Поэтому данная серия публикаций будет описывать мой опыт изучения Data Science: все ошибки, которые были допущены, а также ценные советы, которые мне передали ребята. Сегодня я расскажу об опыте участия в соревновании The Analytics Edge (Spring 2015). Это моя первая статья — не судите строго.
Меня зовут Глеб, я долгое время работаю в ритейловой аналитике и сейчас занимаюсь применением машинного обучения в данной области. Не так давно я познакомился с ребятами из MLClass.ru, которые за очень короткий срок довольно сильно прокачали меня в области Data Science. Благодаря им, буквально за месяц я стал активно сабмитить на kaggle. Поэтому данная серия публикаций будет описывать мой опыт изучения Data Science: все ошибки, которые были допущены, а также ценные советы, которые мне передали ребята. Сегодня я расскажу об опыте участия в соревновании The Analytics Edge (Spring 2015). Это моя первая статья — не судите строго.
Пишем документацию API при помощи RAML
10 min
Tutorial

Удобство работы с любым API во многом зависит от того, как написана и оформлена его документация. Cейчас мы ведём работу по стандартизации и унификации описания всех наших API, и вопросы документирования для нас особенно актуальны.
После долгих поисков мы решили оформлять документацию в формате RAML. Так называется специализированный язык для описания REST API. О его возможностях и преимуществах мы расскажем в этой статье.
300 потрясающих бесплатных сервисов
11 min
Translation

Автор оригинальной статьи Ali Mese добавил ещё 100 новых бесплатных сервисов. Все 400 потрясающих сервисов доступны здесь. И еще подборку +500 инструментов от 10 марта 2017 г. смотрите здесь.

A. Бесплатные Веб-Сайты + Логотипы + Хостинг + Выставление Счета
- HTML5 UP: Адаптивные шаблоны HTML5 и CSS3.
- Bootswatch: Бесплатные темы для Bootstrap.
- Templated: Коллекция 845 бесплатных шаблонов CSS и HTML5.
- Wordpress.org | Wordpress.com: Бесплатное создание веб-сайта.
- Strikingly.com Domain: Конструктор веб-сайтов.
- Logaster: Онлайн генератор логотипов и элементов фирменного стиля (new).
- Withoomph: Мгновенное создание логотипов (англ.).
- Hipster Logo Generator: Генератор хипстерских логотипов.
- Squarespace Free Logo: Можно скачать бесплатную версию в маленьком разрешении.
- Invoice to me: Бесплатный генератор счета.
- Free Invoice Generator: Альтернативный бесплатный генератор счета.
- Slimvoice: Невероятно простой счет.
Облако для компаний разработчиков, выпуск первый: Azure Marketplace – магазин сервисов и решений на любой вкус
7 min
Наша очередная колонка авторских статей носит название “Облако для компаний разработчиков”. В ней мы будем знакомить вас с интересными сценариями использования облачных технологий и платформ Microsoft Azure, Office 365 и других для извлечения максимальной выгоды при профессиональной разработке программного обеспечения.

Первая статья расскажет вам о магазине Azure Marketplace, который, с помощью компании Microsoft, открывает для разработчиков и ИТ-профессионалов удобный способ развертывания готовых сертифицированных решений и доступ к облачным сервисам независимых разработчиков, расширяющих возможности облачной платформы. Кроме того, магазин предлагает разработчикам из ряда стран (список будет расширяться) новый канал продаж своих решений в 100+ стран мира.
Первая статья расскажет вам о магазине Azure Marketplace, который, с помощью компании Microsoft, открывает для разработчиков и ИТ-профессионалов удобный способ развертывания готовых сертифицированных решений и доступ к облачным сервисам независимых разработчиков, расширяющих возможности облачной платформы. Кроме того, магазин предлагает разработчикам из ряда стран (список будет расширяться) новый канал продаж своих решений в 100+ стран мира.
В чем разница между наукой о данных, анализом данных, большими данными, аналитикой, дата майнингом и машинным обучением
4 min
Recovery Mode
В последнее время слово big data звучит отовсюду и в некотором роде это понятие стало мейнстримом. С большими данными тесно связаны такие термины как наука о данных (data science), анализ данных (data analysis), аналитика данных (data analytics), сбор данных (data mining) и машинное обучение (machine learning).
Почему все стали так помешаны на больших данных и что значат все эти слова?

Почему все стали так помешаны на больших данных и что значат все эти слова?
Как компьютеры складывают числа
1 min
Tutorial
Translation
Мы в Хекслете любим разрабатывать не только прикладные курсы, но и более фундаментальные (например, про алгоритмы или операционные системы). Но мы пока не спускались ниже уровня ОС в иерархии абстракций. А там, внутри, столько всего интересного! Для многих людей, да даже для многих профессиональных программистов остаются загадкой процессы, происходящие внутри микропроцессора, на уровне отдельных транзисторов.
Публикуем перевод замечательного видео, в котором меньше чем за 15 минут объясняется, как компьютеры складывают числа с помощью транзисторов, двоичной системы счисления, простых логических схем и их хитрых комбинаций.
Публикуем перевод замечательного видео, в котором меньше чем за 15 минут объясняется, как компьютеры складывают числа с помощью транзисторов, двоичной системы счисления, простых логических схем и их хитрых комбинаций.
Первый в истории ReactOS Hackfest
1 min
Спешим поделится важной информацией. Первому в истории ReactOS хакфесту быть! Мероприятие пройдет с 7 по 12 августа 2015 года в городе А́хен (Германия). Приглашаются все желающие.
Всю информацию о событии можно получить на специальной вики-страничке.

Фотография с аналогичного мероприятия GNOME WebKitGtk+ Hackfest
Город Ахен расположен в месте, где Германия смыкается с Бельгией и Нидерландами, в 4-5 км от границ с этими странами. К югу от города начинается национальный парк Эйфель. Откройте для себя наиболее западный город Германии. В историческом центре города, Аахен предлагает одновременно вкусить дух научной среды с возможностью оценить огромное разнообразие пабов. Давайте поймаем эту атмосферу и будем кодить неделю напролет, чтобы в команде добиться достойных результатов!
Всю информацию о событии можно получить на специальной вики-страничке.
Фотография с аналогичного мероприятия GNOME WebKitGtk+ Hackfest
Город Ахен расположен в месте, где Германия смыкается с Бельгией и Нидерландами, в 4-5 км от границ с этими странами. К югу от города начинается национальный парк Эйфель. Откройте для себя наиболее западный город Германии. В историческом центре города, Аахен предлагает одновременно вкусить дух научной среды с возможностью оценить огромное разнообразие пабов. Давайте поймаем эту атмосферу и будем кодить неделю напролет, чтобы в команде добиться достойных результатов!
Как сделать красивую документацию для Web API, за которую будет не стыдно
3 min
Tutorial
Я хотел бы рассказать вам об утилите, с которой вы сможете забыть о боли создания документации для Web API. О том как это сделать прошу всех под кат.
Моделирование и анализ вычислительных процессов
1 min
Машины Тьюринга, Поста, Минского, алгоритмы Маркова, рекурсивные функции Клини были придуманы в первой половине двадцатого века в результате попыток формализовать понятие алгоритма. Эти математические модели до сих пор успешно применяются для решения задач разрешимости и алгоритмической сложности, но бесполезны для моделирования поведения сетевых протоколов или компонентов операционной системы. В докладе представлены некоторые современные подходы к моделированию вычислений, которые используются в индустрии при разработке сложных информационных систем.
Лекцию в марте прошлого года прочитал на факультете компьютерных наук Ростислав Яворский, доцент департамента анализа данных и искусственного интеллекта. На факультете Ростислав Эдуардович ведет курсы «Введение в программирование», «Компьютерная алгебра», «Неклассические логики и представление знаний».
Лекцию в марте прошлого года прочитал на факультете компьютерных наук Ростислав Яворский, доцент департамента анализа данных и искусственного интеллекта. На факультете Ростислав Эдуардович ведет курсы «Введение в программирование», «Компьютерная алгебра», «Неклассические логики и представление знаний».
Microsoft и Интернет Вещей? Статья вводная — о том, как мы видим эту концепцию
8 min
Привет!
Сегодня и на ближайшие две недели в нашем хаброблоге тематическая секция — и посвящена она тому, чему последние несколько лет уделяется много внимания как от крупнейших корпораций (Microsoft, Intel, HP и др.), так и компаний меньшего масштаба, но с не менее интересными проектами (например, Aura) — а именно Интернету Вещей. Мы расскажем обо всём, что делаем.
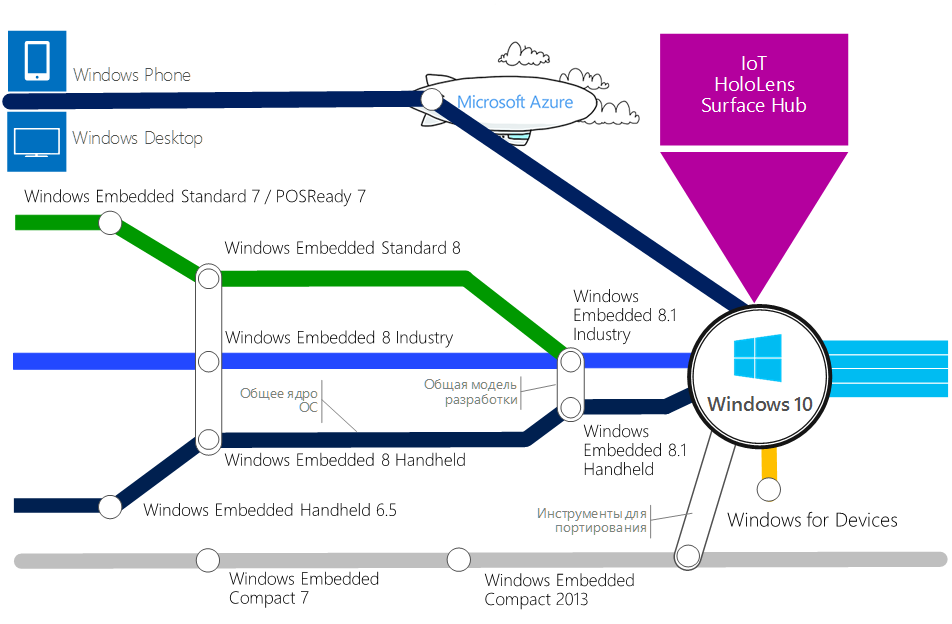
Сегодня и на ближайшие две недели в нашем хаброблоге тематическая секция — и посвящена она тому, чему последние несколько лет уделяется много внимания как от крупнейших корпораций (Microsoft, Intel, HP и др.), так и компаний меньшего масштаба, но с не менее интересными проектами (например, Aura) — а именно Интернету Вещей. Мы расскажем обо всём, что делаем.
Лекция Дмитрия Ветрова о математике больших данных: тензоры, нейросети, байесовский вывод
2 min
Сегодня лекция одного из самых известных в России специалистов по машинному обучению Дмитрия Ветрова, который руководит департаментом больших данных и информационного поиска на факультете компьютерных наук, работающим во ВШЭ при поддержке Яндекса.
Как можно хранить и обрабатывать многомерные массивы в линейных по памяти структурах? Что дает обучение нейронных сетей из триллионов триллионов нейронов и как можно осуществить его без переобучения? Можно ли обрабатывать информацию «на лету», не сохраняя поступающие последовательно данные? Как оптимизировать функцию за время меньшее чем уходит на ее вычисление в одной точке? Что дает обучение по слаборазмеченным данным? И почему для решения всех перечисленных выше задач надо хорошо знать математику? И другое дальше.
Люди и их устройства стали генерировать такое количество данных, что за их ростом не успевают даже вычислительные мощности крупных компаний. И хотя без таких ресурсов работа с данными невозможна, полезными их делают люди. Сейчас мы находимся на этапе, когда информации так много, что традиционные математические методы и модели становятся неприменимы. Из лекции Дмитрия Петровича вы узнаете, почему вам надо хорошо знать математику для работы с машинным обучением и обработкой данных. И какая «новая математика» понадобится вам для этого. Слайды презентации — под катом.
Как можно хранить и обрабатывать многомерные массивы в линейных по памяти структурах? Что дает обучение нейронных сетей из триллионов триллионов нейронов и как можно осуществить его без переобучения? Можно ли обрабатывать информацию «на лету», не сохраняя поступающие последовательно данные? Как оптимизировать функцию за время меньшее чем уходит на ее вычисление в одной точке? Что дает обучение по слаборазмеченным данным? И почему для решения всех перечисленных выше задач надо хорошо знать математику? И другое дальше.
Люди и их устройства стали генерировать такое количество данных, что за их ростом не успевают даже вычислительные мощности крупных компаний. И хотя без таких ресурсов работа с данными невозможна, полезными их делают люди. Сейчас мы находимся на этапе, когда информации так много, что традиционные математические методы и модели становятся неприменимы. Из лекции Дмитрия Петровича вы узнаете, почему вам надо хорошо знать математику для работы с машинным обучением и обработкой данных. И какая «новая математика» понадобится вам для этого. Слайды презентации — под катом.
Гибридная реализация алгоритма MST с использованием CPU и GPU
18 min
Введение
Решение задачи поиска минимальных остовных деревьев ( MST — minimum spanning tree) является распространенной задачей в различных областях исследований: распознавание различных объектов, компьютерное зрение, анализ и построение сетей (например, телефонных, электрических, компьютерных, дорожных и т.д.), химия и биология и многие другие. Существует по крайней мере три известных алгоритма, решающих данную задачу: Борувки, Крускала и Прима. Обработка больших графов (занимающих несколько ГБ) является достаточно трудоемкой задачей для центрального процессора (CPU) и является востребованной в данное время. Все более широкое распространение получают графические ускорители (GPU), способные показывать намного большую производительность, чем CPU. Но задача MST, как и многие задачи по обработке графов, плохо ложатся на архитектуру GPU. В данной статье будет рассмотрена реализация данного алгоритма на GPU. Также будет показано, как можно использовать CPU для построения гибридной реализации данного алгоритма на общей памяти одного узла (состоящего из GPU и нескольких CPU).
NGINX изнутри: рожден для производительности и масштабирования
8 min
Translation
 NGINX вполне заслуженно является одним из лучших по производительности серверов, и всё это благодаря его внутреннему устройству. В то время, как многие веб-серверы и серверы приложений используют простую многопоточную модель, NGINX выделяется из общей массы своей нетривиальной событийной архитектурой, которая позволяет ему с легкостью масштабироваться до сотен тысяч параллельных соединений.
NGINX вполне заслуженно является одним из лучших по производительности серверов, и всё это благодаря его внутреннему устройству. В то время, как многие веб-серверы и серверы приложений используют простую многопоточную модель, NGINX выделяется из общей массы своей нетривиальной событийной архитектурой, которая позволяет ему с легкостью масштабироваться до сотен тысяч параллельных соединений. Инфографика Inside NGINX сверху вниз проведет вас по азам устройства процессов к иллюстрации того, как NGINX обрабатывает множество соединений в одном процессе. Данная статья рассмотрит всё это чуть более детально.
Как связать Docker-контейнеры, не заставляя приложение читать переменные окружения
5 min
Docker, если кто умудрился об этом ещё не слышать — фреймворк с открытым исходным кодом для управления контейнерной виртуализацией. Он быстрый, удобный, продуманный и модный. По сути он меняет правила игры в благородном деле управления конфигурацией серверов, сборки приложений, выполнения серверного кода, управления зависимостями и много ещё где.
Архитектура, которую поощряет Docker — это изолированные контейнеры, каждый из которых выполняет одну команду. Эти контейнеры должны знать только как друг друга найти — другими словами, о контейнере нужно знать его fqdn и порт, или ip и порт, то есть, не более, чем о любой внешней службе.
Рекомендованный способ сообщить такие координаты внутрь процесса, выполняемого в Docker — переменные окружения. Типичный пример этого подхода, не применительно к докеру —
И вот переменные окружения позволяют приложению внутри контейнера удобно и непринуждённо найти базу данных. Но для этого, человек, который пишет приложение, должен об этом знать. И хотя конфигурация приложения с помощью переменных окружения — это хорошо и правильно, иногда приложения написаны плохо, а запускать их как-то надо.
Архитектура, которую поощряет Docker — это изолированные контейнеры, каждый из которых выполняет одну команду. Эти контейнеры должны знать только как друг друга найти — другими словами, о контейнере нужно знать его fqdn и порт, или ip и порт, то есть, не более, чем о любой внешней службе.
Рекомендованный способ сообщить такие координаты внутрь процесса, выполняемого в Docker — переменные окружения. Типичный пример этого подхода, не применительно к докеру —
DATABASE_URL, принятый во фреймворке Rails или NODE_ENV принятый в фрейворке Nodejs.И вот переменные окружения позволяют приложению внутри контейнера удобно и непринуждённо найти базу данных. Но для этого, человек, который пишет приложение, должен об этом знать. И хотя конфигурация приложения с помощью переменных окружения — это хорошо и правильно, иногда приложения написаны плохо, а запускать их как-то надо.
SaaS, PaaS, IaaS или своё «железо»: Что используют отечественные ИТ-компании
2 min
Ранее мы рассказывали об одном из наших кейсов, в рамках которого проект Hotels.ru воспользовался IaaS-инфраструктурой для масштабирования нагруженного веб-проекта.
Сегодня мы решили продолжить рассмотрение вопросов практического применения виртуальной инфраструктуры на примере мнений представителей российского ИТ-сектора.

Сегодня мы решили продолжить рассмотрение вопросов практического применения виртуальной инфраструктуры на примере мнений представителей российского ИТ-сектора.
Микросервисы (Microservices)
22 min
От переводчика: некоторые скорее всего уже читали этот титанический труд от Мартина Фаулера и его коллеги Джеймса Льюиса, но я все же решил сделать перевод этой статьи. Тренд микросервисов набирает обороты в мире enterprise разработки, и эта статья является ценнейшим источником знаний, по сути выжимкой существующего опыта работы с ними.
Термин «Microservice Architecture» получил распространение в последние несколько лет как описание способа дизайна приложений в виде набора независимо развертываемых сервисов. В то время как нет точного описания этого архитектурного стиля, существует некий общий набор характеристик: организация сервисов вокруг бизнес-потребностей, автоматическое развертывание, перенос логики от шины сообщений к приемникам (endpoints) и децентрализованный контроль над языками и данными.
Термин «Microservice Architecture» получил распространение в последние несколько лет как описание способа дизайна приложений в виде набора независимо развертываемых сервисов. В то время как нет точного описания этого архитектурного стиля, существует некий общий набор характеристик: организация сервисов вокруг бизнес-потребностей, автоматическое развертывание, перенос логики от шины сообщений к приемникам (endpoints) и децентрализованный контроль над языками и данными.
Предсказание курса акций с использованием больших данных и машинного обучения
9 min
Translation
Примечание переводчика: В нашем блоге мы уже рассказывали об инструментах для создания торговых роботов и даже анализировали зависимости между названием биржевого тикера компании и успешностью ее акций. Сегодня мы представляем вашему вниманию перевод интересной статьи, авторой которой разрабатывал систему, которая анализирует изменения цен на акций в прошлом и с помощью машинного обучения пытается предсказать будущий курс акций.
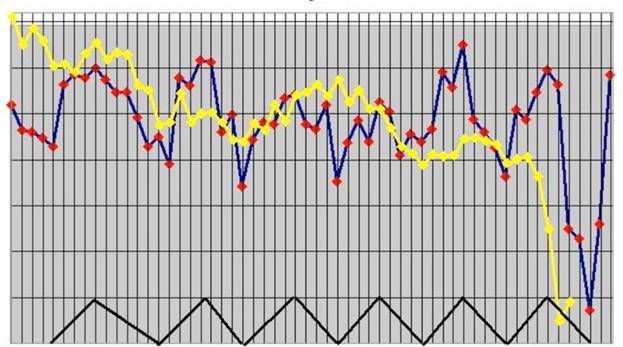
Этот пост основан на статье, носящей название «Моделирование динамики высокочастотного портфеля лимитных ордеров методом опорных векторов». Грубо говоря, я ступенька за ступенькой реализую идеи, представленные в этой статье, используя Spark и Spark MLLib. Авторы используют сокращенные примеры, я же буду использовать полный журнал ордеров из Нью-Йоркской фондовой биржи (NYSE) (выборочные данные доступны на NYSE FTP), поскольку, работая со Spark, я могу легко это сделать. Вместо того, чтобы использовать метод опорных векторов, я воспользуюсь алгоритмом дерева решений для классификации, поскольку Spark MLLib изначально поддерживает мультиклассовую классификацию.
Если вы хотите глубже понять проблему и предложенное решение, вам нужно прочитать ту статью. Я же проведу полный обзор проблемы в одном или двух разделах, но менее научным языком.
Предсказательное моделирование – это процесс выбора или создания модели, целью которой является наиболее точное предсказание возможного исхода.
Краткий обзор
Этот пост основан на статье, носящей название «Моделирование динамики высокочастотного портфеля лимитных ордеров методом опорных векторов». Грубо говоря, я ступенька за ступенькой реализую идеи, представленные в этой статье, используя Spark и Spark MLLib. Авторы используют сокращенные примеры, я же буду использовать полный журнал ордеров из Нью-Йоркской фондовой биржи (NYSE) (выборочные данные доступны на NYSE FTP), поскольку, работая со Spark, я могу легко это сделать. Вместо того, чтобы использовать метод опорных векторов, я воспользуюсь алгоритмом дерева решений для классификации, поскольку Spark MLLib изначально поддерживает мультиклассовую классификацию.
Если вы хотите глубже понять проблему и предложенное решение, вам нужно прочитать ту статью. Я же проведу полный обзор проблемы в одном или двух разделах, но менее научным языком.
Предсказательное моделирование – это процесс выбора или создания модели, целью которой является наиболее точное предсказание возможного исхода.
Как я повышал конверсию машинным обучением
8 min
В этой статье я попробую ответить на такие вопросы:
Ответ на первый вопрос будет самым лаконичным — «да». Услышав это выступление bobuk на YaC/M, я восхитился элегантностью подхода и задумался о том, как бы внедрить похожее решение. Я тогда работал продуктовым менеджером в компании Wargaming и как раз занимался т.н. user acquisition services – технологическими решениями для привлечения пользователей, в число которых входила и система для A/B тестирования лендингов. Так что зерна легли на благодатную почву.
К сожалению, по всяким причинам я не мог плотно заняться этим проектом в обычном рабочем режиме. Зато когда я слегка перегорел на работе и решил устроить себе длинный творческий отпуск, одержимость превратилась в желание сделать такой сервис умной ротации лендингов самостоятельно.
- может ли один доклад умного человека сделать другого человека одержимым?
- как окунуться в машинное обучение (почти) с нуля?
- почему не стоит недооценивать многоруких бандитов?
- существует ли серебряная пуля для a/b тестов?
Ответ на первый вопрос будет самым лаконичным — «да». Услышав это выступление bobuk на YaC/M, я восхитился элегантностью подхода и задумался о том, как бы внедрить похожее решение. Я тогда работал продуктовым менеджером в компании Wargaming и как раз занимался т.н. user acquisition services – технологическими решениями для привлечения пользователей, в число которых входила и система для A/B тестирования лендингов. Так что зерна легли на благодатную почву.
К сожалению, по всяким причинам я не мог плотно заняться этим проектом в обычном рабочем режиме. Зато когда я слегка перегорел на работе и решил устроить себе длинный творческий отпуск, одержимость превратилась в желание сделать такой сервис умной ротации лендингов самостоятельно.