
27 мая в главном зале конференции DevOpsConf 2019, проходящей в рамках фестиваля РИТ++ 2019, в рамках секции «Непрерывная поставка», прозвучал доклад «werf — наш инструмент для CI/CD в Kubernetes». В нём рассказывается о тех проблемах и вызовах, с которыми сталкивается каждый при деплое в Kubernetes, а также о нюансах, которые могут быть заметны не сразу. Разбирая возможные пути решения, мы показываем, как это реализовано в Open Source-инструменте werf.
С момента выступления наша утилита (ранее известная как dapp) преодолела исторический рубеж в 1000 звёзд на GitHub — мы надеемся, что растущее сообщество её пользователей упростит жизнь многим DevOps-инженерам.

Итак, представляем видео с докладом (~47 минут, гораздо информативнее статьи) и основную выжимку из него в текстовом виде. Поехали!
С момента выступления наша утилита (ранее известная как dapp) преодолела исторический рубеж в 1000 звёзд на GitHub — мы надеемся, что растущее сообщество её пользователей упростит жизнь многим DevOps-инженерам.
Итак, представляем видео с докладом (~47 минут, гораздо информативнее статьи) и основную выжимку из него в текстовом виде. Поехали!
 Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.
Настройка производительности базы данных — разработчики обычно либо любят это, либо ненавидят. Я получаю удовольствие от этого и хочу поделиться некоторыми методами, которые я использовал в последнее время для настройки плохо выполняющихся запросов в PostgreSQL. Мои методы не является исчерпывающими, скорее учебником для тех, кто просто тащится от тюнинга.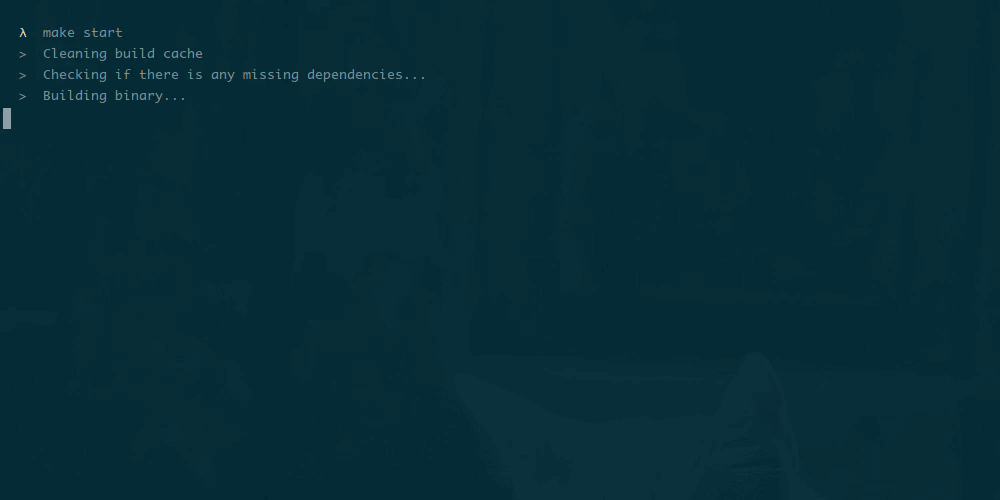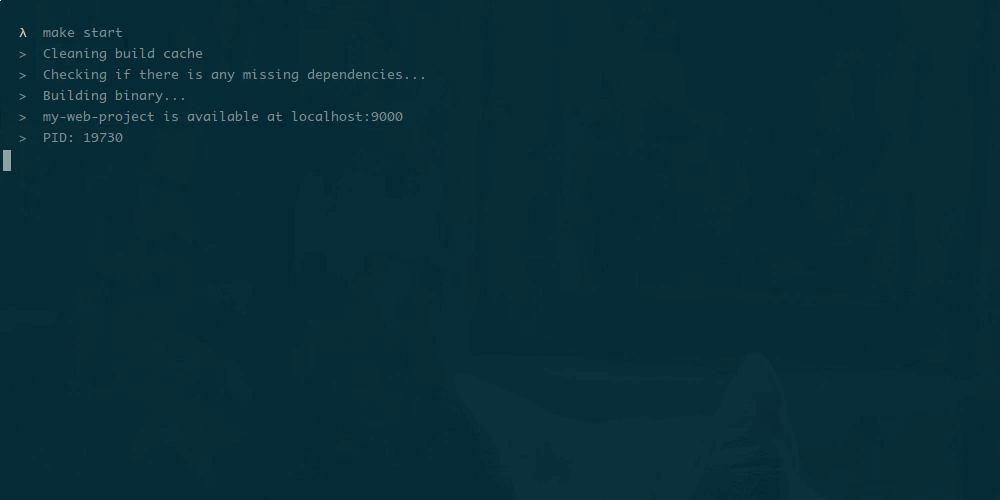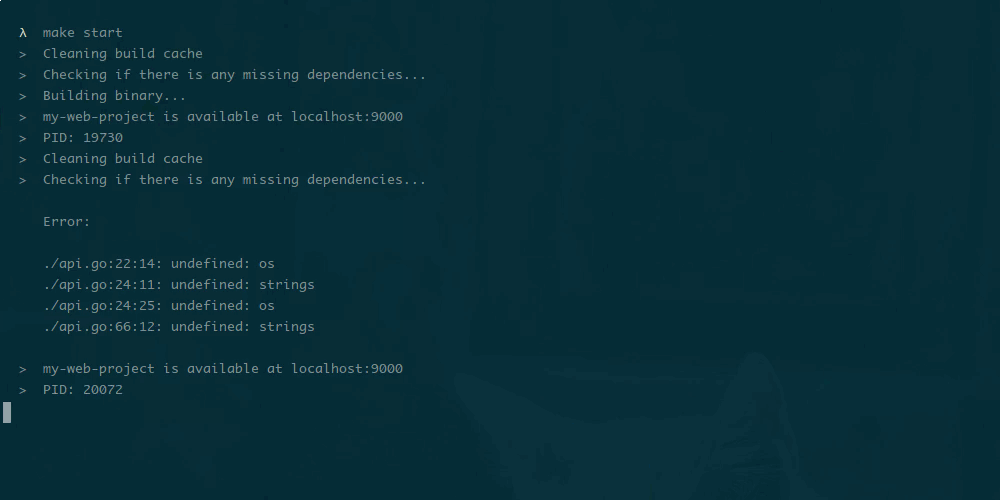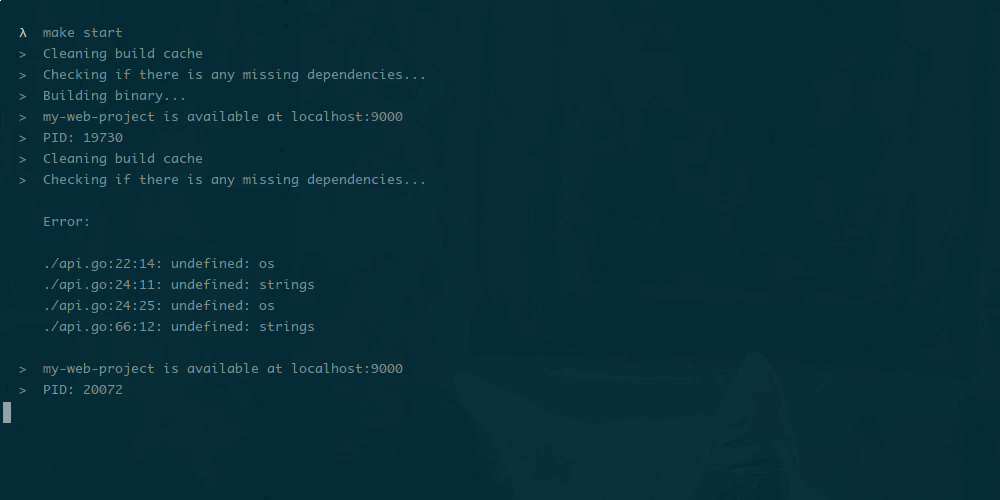



 Практически все нетривиальные программы выделяют и используют динамическую память. Делать это корректно становится все более важным, поскольку программы становятся все более сложными, а ошибки еще более дорогостоящими.
Практически все нетривиальные программы выделяют и используют динамическую память. Делать это корректно становится все более важным, поскольку программы становятся все более сложными, а ошибки еще более дорогостоящими.
 По умолчанию конфигурация PostgreSQL не настроена для рабочей нагрузки. Значения по умолчанию установлены для обеспечения работоспособности PostgreSQL везде с наименьшим количеством ресурсов. Имеются настройки по умолчанию для всех параметров базы данных. Главной обязанностью администратора базы данных или разработчика является настройка PostgreSQL в соответствии с нагрузкой их системы. В этом блоге мы изложим основные рекомендации по настройке параметров базы данных PostgreSQL для повышения производительности базы данных в соответствии с рабочей нагрузкой.
По умолчанию конфигурация PostgreSQL не настроена для рабочей нагрузки. Значения по умолчанию установлены для обеспечения работоспособности PostgreSQL везде с наименьшим количеством ресурсов. Имеются настройки по умолчанию для всех параметров базы данных. Главной обязанностью администратора базы данных или разработчика является настройка PostgreSQL в соответствии с нагрузкой их системы. В этом блоге мы изложим основные рекомендации по настройке параметров базы данных PostgreSQL для повышения производительности базы данных в соответствии с рабочей нагрузкой.
 Оптимальная производительность PostgreSQL зависит от правильно определенных параметров операционной системы. Плохо настроенные параметры ядра ОС могут привести к снижению производительности сервера базы данных. Поэтому обязательно, чтобы эти параметры были настроены в соответствии с сервером базы данных и его рабочей нагрузкой. В этом посте мы обсудим некоторые важные параметры ядра Linux, которые могут повлиять на производительность сервера базы данных и способы их настройки.
Оптимальная производительность PostgreSQL зависит от правильно определенных параметров операционной системы. Плохо настроенные параметры ядра ОС могут привести к снижению производительности сервера базы данных. Поэтому обязательно, чтобы эти параметры были настроены в соответствии с сервером базы данных и его рабочей нагрузкой. В этом посте мы обсудим некоторые важные параметры ядра Linux, которые могут повлиять на производительность сервера базы данных и способы их настройки.


