Angular — это достаточно большой фреймворк. Задокументировать и написать примеры использования для каждого кейса просто невозможно. И механизм внедрения зависимостей не исключение. В этой статье я расскажу о возможностях Angular DI, о которых вы почти ничего не найдете в официальной документации.

Олег Клименко @olegklimenko52
IT Lead
Разработка производительной модели обработки данных для Cassandra
17 min
В DataStax работают над созданием производительной модели данных для Apache Cassandra. В чём заключается эта работа и как её делать правильно, на конференции Cassandra Day Russia 2021 рассказал Артём Чеботко, Solutions Architect в DataStax.

Речь пойдет о разработке производительной модели данных для Apache Cassandra. Над этой задачей я долгое время работаю в DataStax. Есть довольно большое количество проектов и use cases, в которых нужна была производительная модель данных. Мы поговорим о методологии и как это сделать правильно.
Начнем с более простых вещей. Обсудим, как Cassandra хранит данные, чтобы понимать, на что нужно особенно обращать внимание. Потом обсудим методологию. Здесь также есть 3 примера, о которых я хотел бы поговорить. Они разные, в них есть разные оптимизации, которые можно обсудить.
Как устроена apache cassandra
13 min

В этом топике я хотел бы рассказать о том, как устроена кассандра (cassandra) — децентрализованная, отказоустойчивая и надёжная база данных “ключ-значение”. Хранилище само позаботится о проблемах наличия единой точки отказа (single point of failure), отказа серверов и о распределении данных между узлами кластера (cluster node). При чем, как в случае размещения серверов в одном центре обработки данных (data center), так и в конфигурации со многими центрами обработки данных, разделенных расстояниями и, соответственно, сетевыми задержками. Под надёжностью понимается итоговая согласованность (eventual consistency) данных с возможностью установки уровня согласования данных (tune consistency) каждого запроса.
NoSQL базы данных требуют в целом большего понимания их внутреннего устройства чем SQL. Эта статья будет описывать базовое строение, а в следующих статьях можно будет рассмотреть: CQL и интерфейс программирования; техники проектирования и оптимизации; особенности кластеров размещённых в многих центрах обработки данных.
Индексы в PostgreSQL — 1
17 min
Предисловие
В этой серии статей речь пойдет об индексах в PostgreSQL.
Любой вопрос можно рассматривать с разных точек зрения. Мы будем говорить о том, что должно интересовать прикладного разработчика, использующего СУБД: какие индексы существуют, почему в PostgreSQL их так много разных, и как их использовать для ускорения запросов. Пожалуй, тему можно было бы раскрыть и меньшим числом слов, но мы втайне надеемся на любознательного разработчика, которому также интересны и подробности внутреннего устройства, тем более, что понимание таких подробностей позволяет не только прислушиваться к чужому мнению, но и делать собственные выводы.
За скобками обсуждения останутся вопросы разработки новых типов индексов. Это требует знания языка Си и относится скорее к компетенции системного программиста, а не прикладного разработчика. По этой же причине мы практически не будем рассматривать программные интерфейсы, а остановимся только на том, что имеет значение для использования уже готовых к употреблению индексов.
В этой части мы поговорим про разделение сфер ответственности между общим механизмом индексирования, относящимся к ядру СУБД, и отдельными методами индексного доступа, которые в PostgreSQL можно добавлять как расширения. В следующей части мы рассмотрим интерфейс метода доступа и такие важные понятия, как классы и семейства операторов. После такого длинного, но необходимого введения мы подробно рассмотрим устройство и применение различных типов индексов: Hash, B-tree, GiST, SP-GiST, GIN и RUM, BRIN и Bloom.
Ограничения (сonstraints) PostgreSQL: exclude, частичный unique, отложенные ограничения и др
4 min
 Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.
Целостность данных легко нарушить. Бывает так, что в поле price попадает значение 0 из-за ошибки в коде приложения (периодически всплывают новости, как в том или ином инет-магазине продавали товары по 0 долларов). Или бывает, что удалили юзера из таблицы, но какие-то данные о нем остались в других таблицах, и эти данные вылезли в каком-то интерфейсе.PostgreSQL, как и любая другая СУБД, умеет делать некоторые проверки при вставке/изменении данных, и этим обязательно нужно уметь пользоваться. Давайте посмотрим, что мы можем проверять:
1. Кастомный подтип через ключевое слово DOMAIN
MFS — паттерн построения UI в iOS приложениях
14 min
Логика развития мобильных приложений заключается в постепенном усложнении функциональной нагрузки на пользовательский интерфейс.
Что, в свою очередь, приводит к росту кодовой базы и затруднению ее обслуживания.
MFS - позволяет создавать современный дизайн приложений и при этом избежать такого явления как MassiveViewController.
MVVM: полное понимание (+WPF) Часть 1
8 min
В настоящей статье задействован мой опыт доведения некоторого числа студентов до полного и окончательного понимания паттерна MVVM и реализации его в WPF. Паттерн описывается на примерах возрастающей сложности. Сначала теоретическая часть, которая может использоваться безотносительно конкретного языка, затем практическая часть, в которой показано несколько вариантов реализации коммуникации между слоями с использованием WPF и, немножко, Prism.
Зачем вообще нужно использовать паттерн MVVM? Это ведь лишний код! Написать тоже самое можно гораздо понятнее и прямолинейнее.
Отвечаю: в маленьких проектах прямолинейный подход срабатывает. Но стоит ему стать чуть больше — и логика программы размазывается в интерфейсе так, что потом весь проект превращается в монолитный клубок, который проще переписать заново, чем пытаться распутать. Для наглядности можно посмотреть на две картинки:
Зачем вообще нужно использовать паттерн MVVM? Это ведь лишний код! Написать тоже самое можно гораздо понятнее и прямолинейнее.
Отвечаю: в маленьких проектах прямолинейный подход срабатывает. Но стоит ему стать чуть больше — и логика программы размазывается в интерфейсе так, что потом весь проект превращается в монолитный клубок, который проще переписать заново, чем пытаться распутать. Для наглядности можно посмотреть на две картинки:
Карманная книга по TypeScript. Часть 1. Основы
7 min
Translation
- Часть 1. Основы
- Часть 2. Типы на каждый день
- Часть 3. Сужение типов
- Часть 4. Подробнее о функциях
- Часть 5. Объектные типы
- Часть 6. Манипуляции с типами
- Часть 7. Классы
- Часть 8. Модули
Обратите внимание: для большого удобства в изучении книга была оформлена в виде прогрессивного веб-приложения.

С сегодняшнего дня мы начинаем серию публикаций адаптированного и дополненного перевода "Карманной книги по TypeScript".
Каждое значение в JavaScript при выполнении над ним каких-либо операций ведет себя определенным образом. Это может звучать несколько абстрактно, но, в качестве примера, попробуем выполнить некоторые операции над переменной message:
// Получаем доступ к свойству `toLowerCase`
// и вызываем его
message.toLowerCase()
// Вызываем `message`
message()
На первой строке мы получаем доступ к свойству toLowerCase и вызываем его. На второй строке мы пытаемся вызвать message.
Предположим, что мы не знаем, какое значение имеет message — обычное дело — поэтому мы не можем с уверенностью сказать, какой результат получим в результате выполнения этого кода.
- Является ли переменная
messageвызываемой? - Имеет ли она свойство
toLowerCase? - Если имеет, является ли
toLowerCaseвызываемым? - Если оба этих значения являются вызываемыми, то что они возвращают?
Ответы на эти вопросы, как правило, хранятся в нашей памяти, поэтому остается только надеяться, что мы все помним правильно.
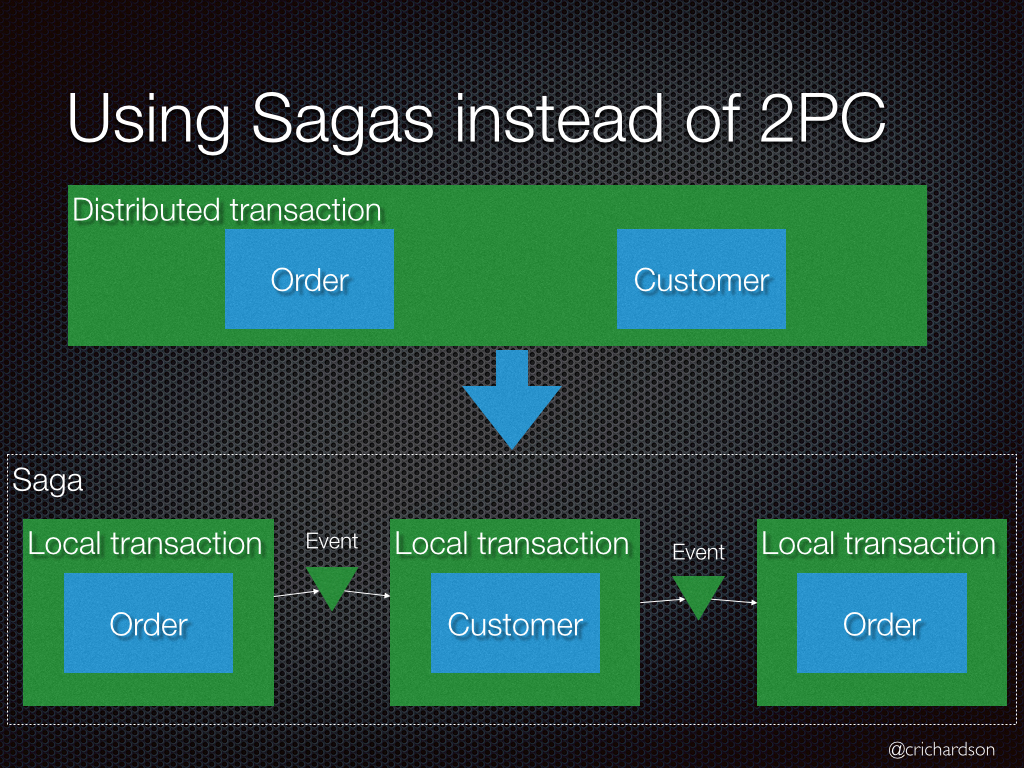
Паттерн: Сага
2 min
Привет, Хабр! Представляю вашему вниманию перевод статьи "Pattern: Saga" автора Chris Richardson.
Ситуация
Есть приложение, к которому применялся паттерн Database per Service. Теперь у каждого сервиса приложения есть своя собственная база данных. Некоторые бизнес транзакции охватывают сразу несколько сервисов, так что нужен механизм, обеспечивающий согласованность данных между этими сервисами.
Например: давайте представим, что мы разрабатываем интернет магазин, где у клиента есть кредитный лимит. Приложение должно гарантировать, что новый заказ не превышает кредитный лимит клиента. Так как Заказы и Клиенты — различные базы данных, то приложение не может использовать локальные ACID транзакции.
Проблема
Как обеспечить согласованность данных между сервисами?
Решение
Необходимо каждую бизнес транзакцию, которая охватывает несколько сервисов, реализовывать как сагу.
Сага представляет собой набор локальных транзакций. Каждая локальная транзакция обновляет базу данных и публикует сообщение или событие, инициируя следующую локальную транзакцию в саге. Если транзакция завершилась неудачей, например, из-за нарушения бизнес правил, тогда сага запускает компенсирующие транзакции, которые откатывают изменения, сделанные предшествующими локальными транзакциями.
Основы CQRS
14 min
Данная статья основана на материале из различных статей по CQRS, а также проектов, где применялся такой подход.
Системы управления предприятиями, проектами, сотрудниками давно вошли в нашу жизнь. И пользователи таких enterprise приложений все более требовательны: возрастают требования к масштабируемости, сложность бизнес-логики, требования к системам меняются быстро, да и отчетность требуется в реальном времени.
Поэтому при разработке зачастую можно наблюдать одни и те же проблемы в организации кода и архитектуры, а также в их усложнении. При неправильном подходе к проектированию рано или поздно может наступить момент, когда код становится настолько сложным и запутанным, что каждое внесение изменений требует все больше времени и ресурсов.
Системы управления предприятиями, проектами, сотрудниками давно вошли в нашу жизнь. И пользователи таких enterprise приложений все более требовательны: возрастают требования к масштабируемости, сложность бизнес-логики, требования к системам меняются быстро, да и отчетность требуется в реальном времени.
Поэтому при разработке зачастую можно наблюдать одни и те же проблемы в организации кода и архитектуры, а также в их усложнении. При неправильном подходе к проектированию рано или поздно может наступить момент, когда код становится настолько сложным и запутанным, что каждое внесение изменений требует все больше времени и ресурсов.
Введение в React
30 min
Tutorial
Оглавление
1. Getting started with React
....1.1 Методы добавления React
....1.2 Выбор метода добавления
........1.2.1 Добавление React с помощью тэга <script />
........1.2.2 Добавление React с помощью create-react-app
2. Basically React
....2.1 React object
....2.2 React element
........2.2.1 CreateElement
........2.2.2 CloneElement
........2.2.3 IsValidElement
........2.2.4 Children
....2.3 React компоненты
........2.3.1 React.Component
........2.3.2 React.Fragment
.........2.3.3 State
.........2.3.4 Events
.........2.3.5 Lifecycle
.........2.3.6 Refs
....2.4 ReactDOM
........2.4.1 Render
........2.4.2 Hydrate
........2.4.3 UnmountComponentAtNode
........2.4.4 CreatePortal
3. Other topics
....3.1 Lists and Keys
....3.2 Error Handling
........3.2.1 getDerivedStateFromError
........3.2.2 componentDidCatch
Заключение
React — JavaScript-библиотека с открытым исходным кодом для разработки пользовательских интерфейсов.
Существует 2 основных метода для добавления React на сайт:
Выбор метода зависит от потребностей. Если вы просто хотите добавить немного интерактивности на существующую страницу или хотите просто попробовать React тогда используйте первый метод подключения. Если вы собираетесь построить полноценное React приложение, то используйте create-react-app.
Шаг 1 Добавьте 3 тега в контейнер head на вашей странице:
Здесь подключаются библиотеки React и React-dom, а также компилятор babel.
Шаг 2 Добавьте пустой контейнер на вашу страницу чтобы отметить место, где вы хотите что-либо отобразить с помощью React.
1. Getting started with React
....1.1 Методы добавления React
....1.2 Выбор метода добавления
........1.2.1 Добавление React с помощью тэга <script />
........1.2.2 Добавление React с помощью create-react-app
2. Basically React
....2.1 React object
....2.2 React element
........2.2.1 CreateElement
........2.2.2 CloneElement
........2.2.3 IsValidElement
........2.2.4 Children
....2.3 React компоненты
........2.3.1 React.Component
........2.3.2 React.Fragment
.........2.3.3 State
.........2.3.4 Events
.........2.3.5 Lifecycle
.........2.3.6 Refs
....2.4 ReactDOM
........2.4.1 Render
........2.4.2 Hydrate
........2.4.3 UnmountComponentAtNode
........2.4.4 CreatePortal
3. Other topics
....3.1 Lists and Keys
....3.2 Error Handling
........3.2.1 getDerivedStateFromError
........3.2.2 componentDidCatch
Заключение
React — JavaScript-библиотека с открытым исходным кодом для разработки пользовательских интерфейсов.
1. Getting started with React
1.1 Методы добавления React
Существует 2 основных метода для добавления React на сайт:
- С помощью тэга <script />
- С помощью create-react-app
1.2 Выбор метода добавления
Выбор метода зависит от потребностей. Если вы просто хотите добавить немного интерактивности на существующую страницу или хотите просто попробовать React тогда используйте первый метод подключения. Если вы собираетесь построить полноценное React приложение, то используйте create-react-app.
1.2.1 Добавление React с помощью тэга <script />
Шаг 1 Добавьте 3 тега в контейнер head на вашей странице:
<script src="https://unpkg.com/react@16/umd/react.development.js"></script>
<script src="https://unpkg.com/react-dom@16/umd/react-dom.development.js"></script>
<script src="https://unpkg.com/babel-standalone@6.15.0/babel.min.js"></script>Здесь подключаются библиотеки React и React-dom, а также компилятор babel.
Babel не является обязательным для использования React, но полезным для написания кода UI, с помощью JSX.
Шаг 2 Добавьте пустой контейнер на вашу страницу чтобы отметить место, где вы хотите что-либо отобразить с помощью React.
Введение в Redux & React-redux
11 min
Tutorial

Оглавление
Введение
1. Установка и начало работы
2. Redux
....2.1 createStore
....2.2 reducer()
....2.3 dispatch()
....2.4 actionCreator()
....2.5 Actions
....2.6 getState()
....2.7 subscribe()
....2.8 combineReducers()
....2.9 initialState
3. React-redux
....3.1 Provider
....3.2 mapStateToProps()
....3.3 mapDispatchToProps()
....3.4 connect()
Введение
Вот вы прочитали мою статью про React (если нет, то настоятельно рекомендую вам сделать это) и начали разрабатывать приложения на нём. Но что это? Вы замечаете, как с расширением вашего приложения становится всё сложнее следить за текущим состоянием, сложно следить за тем, когда и какие компоненты рендарятся, когда они не рендарятся и почему они не рендарятся, сложно следить за потоком изменяющихся данных. Для этого и есть библиотека Redux. Сам React хоть и лёгкий, но для комфортной разработки на нем нужно много чего изучить.
React Hooks простыми словами
10 min

О хуках в фронтенд-разработке на Хабре писали уже не раз, и в этой статье мы не сделаем великого открытия. Наша цель другая – рассказать про React Hooks настолько подробно и просто без трудной терминологии, насколько это возможно. Чтобы после прочтения статьи каждый понял про хуки всё. Эта статья будет полезна как начинающим React-разработчикам, так и тем, кто хочет, не уходя в глубины документации, получить практическую информацию в сжатом виде.
Как Kafka стала былью
5 min
Привет, Хабр!
Я работаю в команде Tinkoff, которая занимается разработкой собственного центра нотификаций. По большей части я разрабатываю на Java с использованием Spring boot и решаю разные технические проблемы, возникающие в проекте.
Большинство наших микросервисов асинхронно взаимодействуют друг с другом через брокер сообщений. Ранее в качестве брокера мы использовали IBM MQ, который перестал справляться с нагрузкой, но при этом обладал высокими гарантиями доставки.
В качестве замены нам предложили Apache Kafka, которая обладает высоким потенциалом масштабирования, но, к сожалению, требует практически индивидуального подхода к конфигурированию для разных сценариев. Кроме того, механизм at least once delivery, работающий в Kafka по умолчанию, не позволял поддерживать необходимый уровень консистентности из коробки. Далее я поделюсь нашим опытом конфигурации Kafka, в частности расскажу, как настроить и жить с exactly once delivery.
Повторная обработка событий, полученных из Kafka
7 min

Привет, Хабр.
Недавно я поделился опытом о том, какие параметры мы в команде чаще всего используем для Kafka Producer и Consumer, чтобы приблизиться к гарантированной доставке. В этой статье хочу рассказать, как мы организовали повторную обработку события, полученного из Kafka, в результате временной недоступности внешней системы.
Современные приложения работают в очень сложной среде. Бизнес-логика, обернутая в современный технологический стек, работающая в Docker-образе, который управляется оркестратором вроде Kubernetes или OpenShift, и коммуницирующая с другими приложениями или enterprise-решениями через цепочку физических и виртуальных маршрутизаторов. В таком окружении всегда что-то может сломаться, поэтому повторная обработка событий в случае недоступности одной из внешних систем — важная часть наших бизнес-процессов.
Архитектура приложения Angular. Используем NgModules
8 min
Tutorial
Translation
Прим. перев.: для понимания данной статьи необходимо обладать начальными знаниями Angular: что такое компоненты, как создать простейшее SPA приложение и т.д. Если Вы не знакомы с данной темой, то рекомендую для начала ознакомиться с примером создания SPA приложения из оф. документации.
Об NgModules можно прочитать здесь.

Один год назад я уже публиковал статью об NgModules, где рассматриваются технические тонкости, когда импортировать модули, пространство имен и т.д. Рекомендуется для ознакомления (прим. перев.: статья по содержанию аналогична той, на которую я ссылаюсь вначале).
Пришло время избавиться от Angular и сэкономить миллиарды долларов
6 min
Translation
Я знаю, что эта статья вызовет поток гневных комментариев, но… так тому и быть. Кто-то должен наконец озвучить то, о чём уже некоторое время размышляют программисты, обладающие некоторым опытом.
Я занимаюсь программированием более 20 лет, работал в некоторых из самых приличных североамериканских компаний. Вот уже несколько лет я наблюдаю за тем, что происходит в сфере разработки интерфейсов. Ситуация здесь постоянно ухудшается. В частности, я говорю о «модных технологиях», о довольно крупных фрагментах JS- и CSS-кода, претендующих на остроумное исполнение, которые вроде как должны пользоваться неистовой популярностью у толп новичков. Теперь в эти толпы включают даже и опытных разработчиков, которым полагается что-то понимать в том, чем они пользуются.

Количество случаев практического применения фреймворков, выдающих подобный код, наподобие Angular, растёт как снежный ком. В результате разработчиков подхватила лавина, ввергнувшая их в настоящий «ад программного кода». При этом события развиваются по нарастающей. Сейчас нельзя заметить даже признаков того, что всё это безумие хотя бы выходит на какой-то постоянный уровень.
Каждый день мне на почту приходят вакансии. Компании всех размеров и мастей рыщут в поисках ОПЫТНЫХ Angular 4, 5, 6, 7, 8, 10, 12-разработчиков, которые как минимум 5 лет занимались разработкой и поддержкой того дурдома, который все называют «современнейшими пользовательскими интерфейсами».
Это — не нечто «современнейшее». Это — дурдом.
Несколько лет назад я был на собеседовании в EA (Electronic Arts). Там мне сказали, что компания избавляется от всех своих UI-фреймворков и возвращается к написанию кода на чистом JavaScript (речь идёт о модулях, или о том, что тот, кто работает с jQuery, назвал бы JS-плагинами). Я был удивлён и заинтригован.
Теперь о причинах подобного хода знают не только в EA, но и во всех остальных компаниях.
Я занимаюсь программированием более 20 лет, работал в некоторых из самых приличных североамериканских компаний. Вот уже несколько лет я наблюдаю за тем, что происходит в сфере разработки интерфейсов. Ситуация здесь постоянно ухудшается. В частности, я говорю о «модных технологиях», о довольно крупных фрагментах JS- и CSS-кода, претендующих на остроумное исполнение, которые вроде как должны пользоваться неистовой популярностью у толп новичков. Теперь в эти толпы включают даже и опытных разработчиков, которым полагается что-то понимать в том, чем они пользуются.
Количество случаев практического применения фреймворков, выдающих подобный код, наподобие Angular, растёт как снежный ком. В результате разработчиков подхватила лавина, ввергнувшая их в настоящий «ад программного кода». При этом события развиваются по нарастающей. Сейчас нельзя заметить даже признаков того, что всё это безумие хотя бы выходит на какой-то постоянный уровень.
Каждый день мне на почту приходят вакансии. Компании всех размеров и мастей рыщут в поисках ОПЫТНЫХ Angular 4, 5, 6, 7, 8, 10, 12-разработчиков, которые как минимум 5 лет занимались разработкой и поддержкой того дурдома, который все называют «современнейшими пользовательскими интерфейсами».
Это — не нечто «современнейшее». Это — дурдом.
Несколько лет назад я был на собеседовании в EA (Electronic Arts). Там мне сказали, что компания избавляется от всех своих UI-фреймворков и возвращается к написанию кода на чистом JavaScript (речь идёт о модулях, или о том, что тот, кто работает с jQuery, назвал бы JS-плагинами). Я был удивлён и заинтригован.
Теперь о причинах подобного хода знают не только в EA, но и во всех остальных компаниях.
Компоненты-конструкторы: мощь ng-content в Angular
9 min

Проекция контента — одна из базовых возможностей Angular, о которой слышали почти все. А с недавних пор по ней появилась и хорошая официальная документация. Тем не менее в реальных задачах разработчики часто обходят ng-content стороной, прибегая к более сложным и перегруженным решениям и усложняя дальнейшее использование и поддержку компонента.
В этой статье я хотел бы показать несколько типовых кейсов для ng-content при разработке многократно используемых компонентов. А еще — рассказать о преимуществах, которые они могут нам дать.
Присматриваемся к инструментам для мониторинга распределенных приложений
4 min
Когда приложение было монолитным и вдруг, раз, стало распределённым, в формулу вычисления доступности добавляется ещё одна неизвестная — сетевая. Из-за проблем с вызовами между компонентами, приложения часто валятся и начинают дрыгать ножками. А выяснение причин нестабильной работы распределённого приложения — та ещё задачка. Дополнительную неразбериху в структуру приложения вносит условный kubernetes, который по своему внутреннему усмотрению может произвольно распределять условные поды по условным нодам. Пишу «условный», потому что на месте kubernetes может быть и Swarm и Openshift и прочие и прочие.
Я к тому, что без нормальной визуализации разобраться где температурит, может быть очень непросто. Под катом моё представление о потенциальных возможностях инструментов, которые умеют рисовать карту приложения и подсвечивать места для прикладывания подорожника, а также список этих самых инструментов со скриншотами.
Быть тимлидом, ч2: Технологии
6 min
Всем привет, меня зовут Семён и я руковожу разработкой витрины объектов недвижимости в ДомКлик. В прошлой части этой серии статей мы поговорили про самую трудоёмкую область работы тимлида — работу с людьми. Сегодня я расскажу про не менее важную тему для любого тимлида — технологии. Насколько «крут» должен быть тимлид технически? Должен ли он писать код? Отвечает ли тимлид за техническое состояние своего «хозяйства»? Кого заинтересовал, прошу под кат.