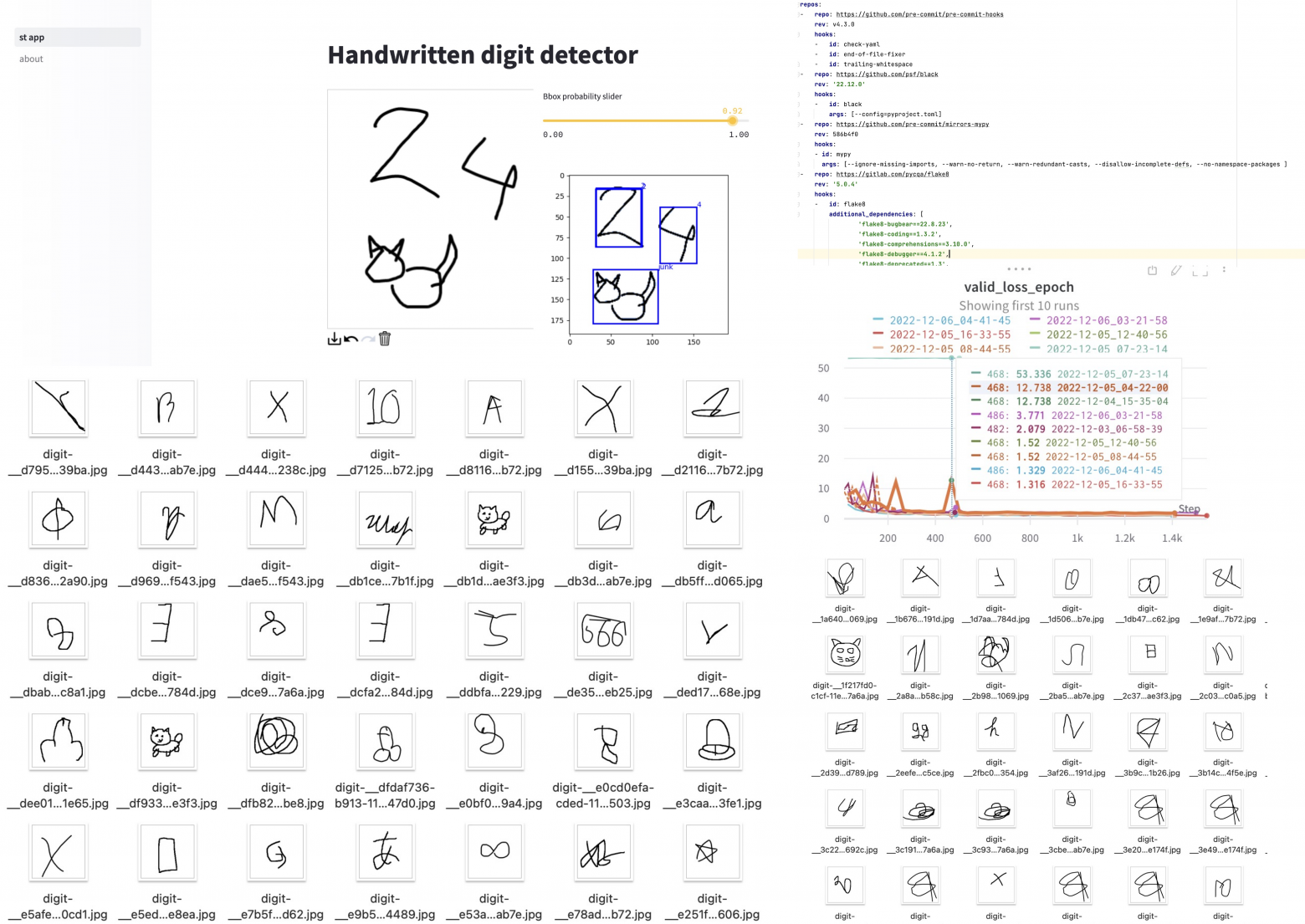
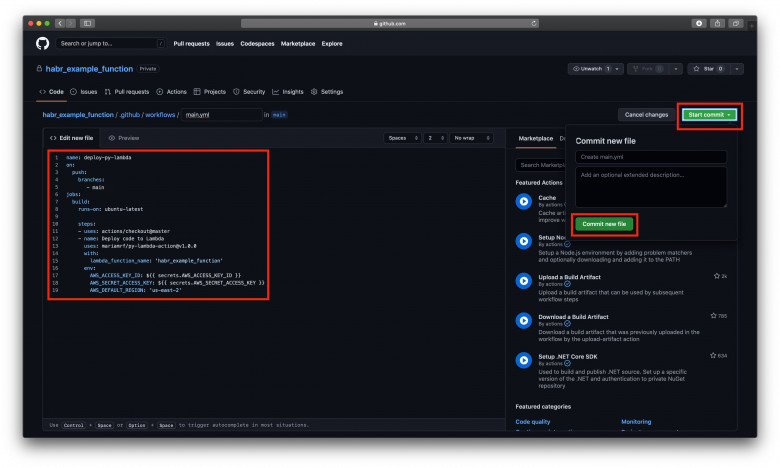
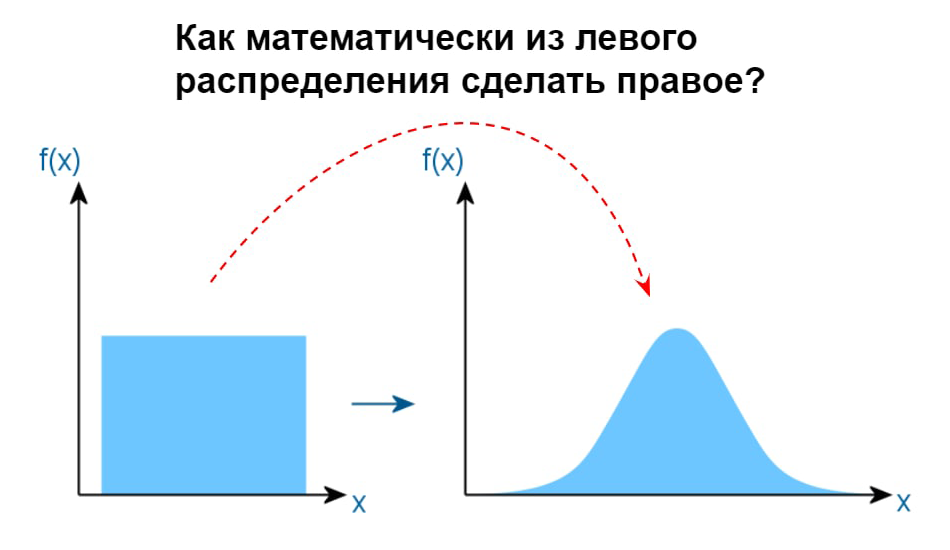
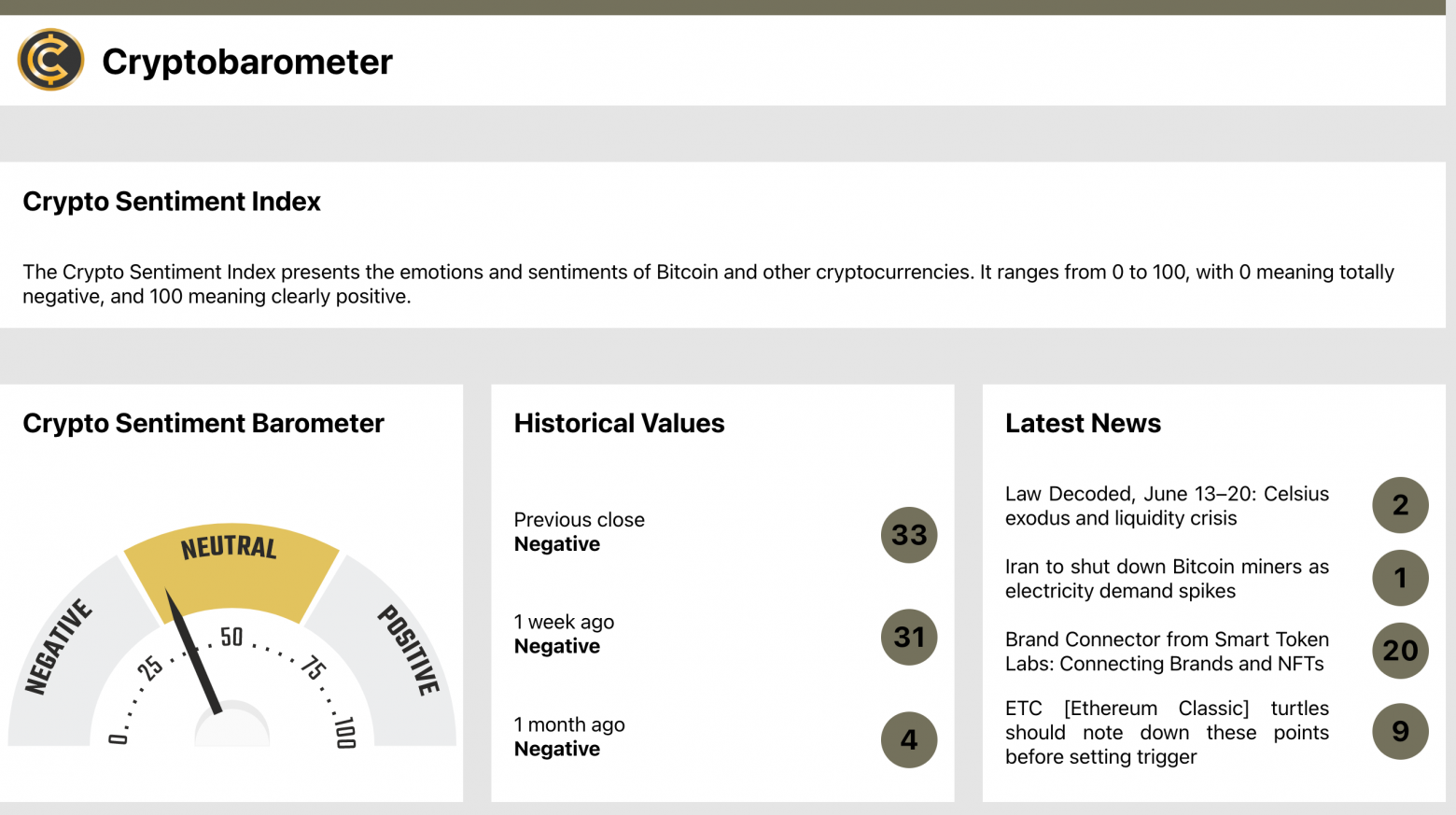
В 2010 году одно из крупных издательств объявило конкурс на лучшее произведение в стиле офисного романа. Мне об этом рассказала моя уже бывшая коллега за обедом. Она собралась писать и подавать рукопись. На моё удивление она ответила: «А что здесь сочинять? Бери и описывай наш коллектив, тот ещё офисный детектив с элементами хоррора». И то правда: офис из полтысячи сотрудников был богат на интриги, конфликты, локальные серпентарии и уничтожение самооценки человека. Самое интересное, что речь шла об IT-компании, одной из лучших на тот момент. В этой компании было немало ребят, которые задавались вопросом, а можно ли просто спокойно поработать, не ввязываясь в баталии и битвы с местными сколопендрами. Как показал дальнейший опыт, этот вопрос звучит почти везде. Так что же мешает работать, кроме устаревшей техники и медленного интернета, которые почти повсеместно удаётся извести?
 Добро пожаловать в молодую, успешную, позитивную, динамично развивающуюся команду!
Добро пожаловать в молодую, успешную, позитивную, динамично развивающуюся команду!