Привет, Хабр!
Думаю, все заметили, что технологии компьютерного зрения и искусственного интеллекта появились во многих сферах нашей жизни. Аналитика изображений применяется на производстве, в медицине, в системах управления, в географии.
В сфере спорта также не обошлось без компьютерного зрения. Современные технологии используются для анализа игр и стратегий, предоставляя тренерам и спортсменам ценную информацию, которую сложно или невозможно получить вручную. В частности, в футболе компьютерное зрение используется для трекинга, детектирования действий игроков, вычисления их скоростей и решения многих других задач. Аналитика матча вручную может занимать много времени и требует внимания квалифицированных специалистов, а технологии компьютерного зрения позволяют значительно автоматизировать и оптимизировать процессы.
Одна из задач, которая была поставлена в рамках нашего проекта по футбольной аналитике, заключается в определении команды, к которой принадлежит конкретный игрок. Для человеческого глаза эта задача — проще некуда. Достаточно посмотреть на цвет формы игрока, чтобы понять, в какой он команде. Однако как научить компьютер автоматически понимать цвет? Оказалось, что в общем случае эта задача совсем не тривиальна.
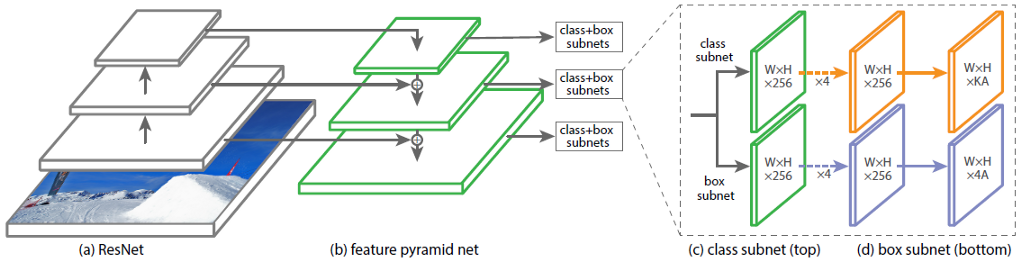
Изначально были попытки обучить на размеченных данных классические детекторы объектов, например, YOLO. Однако оказалось, что модель сильно усложняет задачу — начинает ориентироваться на расстановку игроков, и из-за этого точность становится невысокой. Поэтому возникла идея попробовать более классические и, соответственно, более простые алгоритмы.