В одном из прежних постов я рассказывал, как реализовать
«простейшую в мире lock-free хеш-таблицу» на C++. Она была настолько проста, что было невозможно удалять из нее записи или менять ее размерность. С тех пор прошло несколько лет, и не так давно я написал несколько многопоточных ассоциативных массивов без таких ограничений. Их можно найти в моем проекте
Junction на GitHub.
Junction содержит несколько многопоточных реализаций интерфейса map – даже «самая простая в мире» среди них, под названием
ConcurrentMap_Crude. Для краткости будем называть ее
Crude map. В этом посте я объясню разницу между Crude map и
Linear map из библиотеки Junction. Linear — самый простой map в Junction, поддерживающий и изменение размера, и удаление.
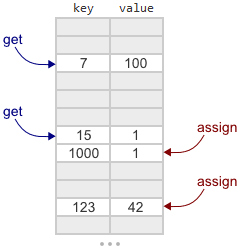
Можете ознакомиться с объяснением того, как работает Crude map,
в первоначальном посте. Если коротко, то она основана на
открытой адресации и
линейном пробировании. Это значит, что она по сути является большим массивом ключей и значений, использующим линейный поиск. Во время добавления или поиска заданного ключа мы вычисляем хеш от ключа, чтобы определить, с какого места начать поиск. Добавление и поиск данных возможны в многопоточном режиме.