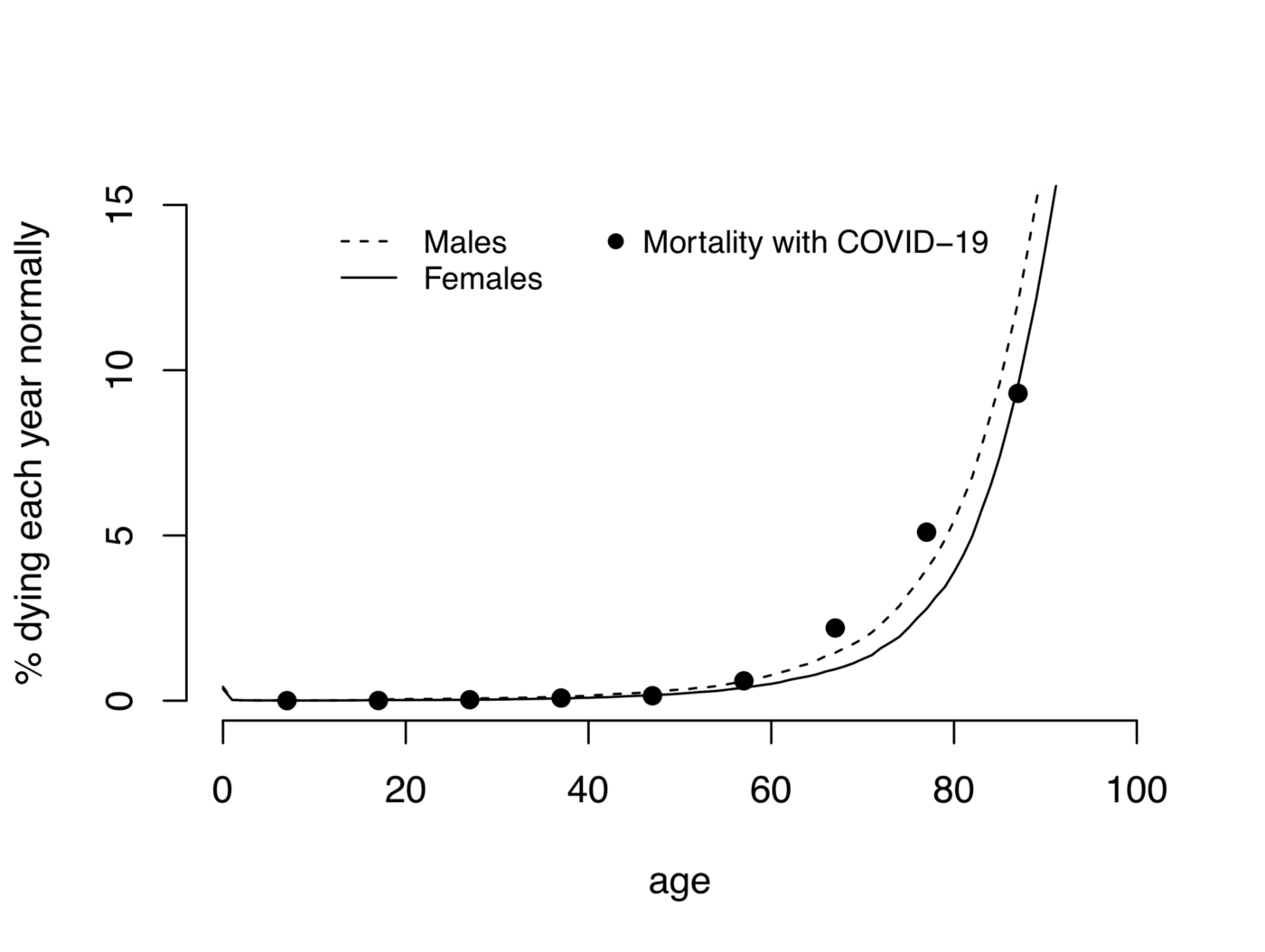
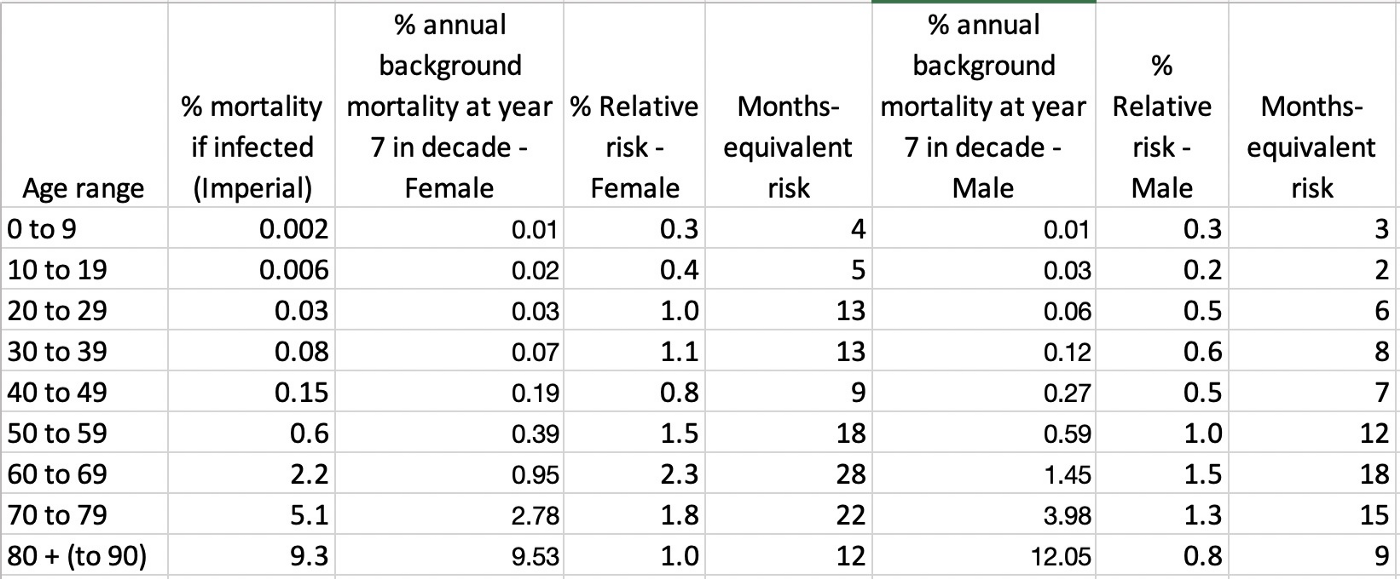
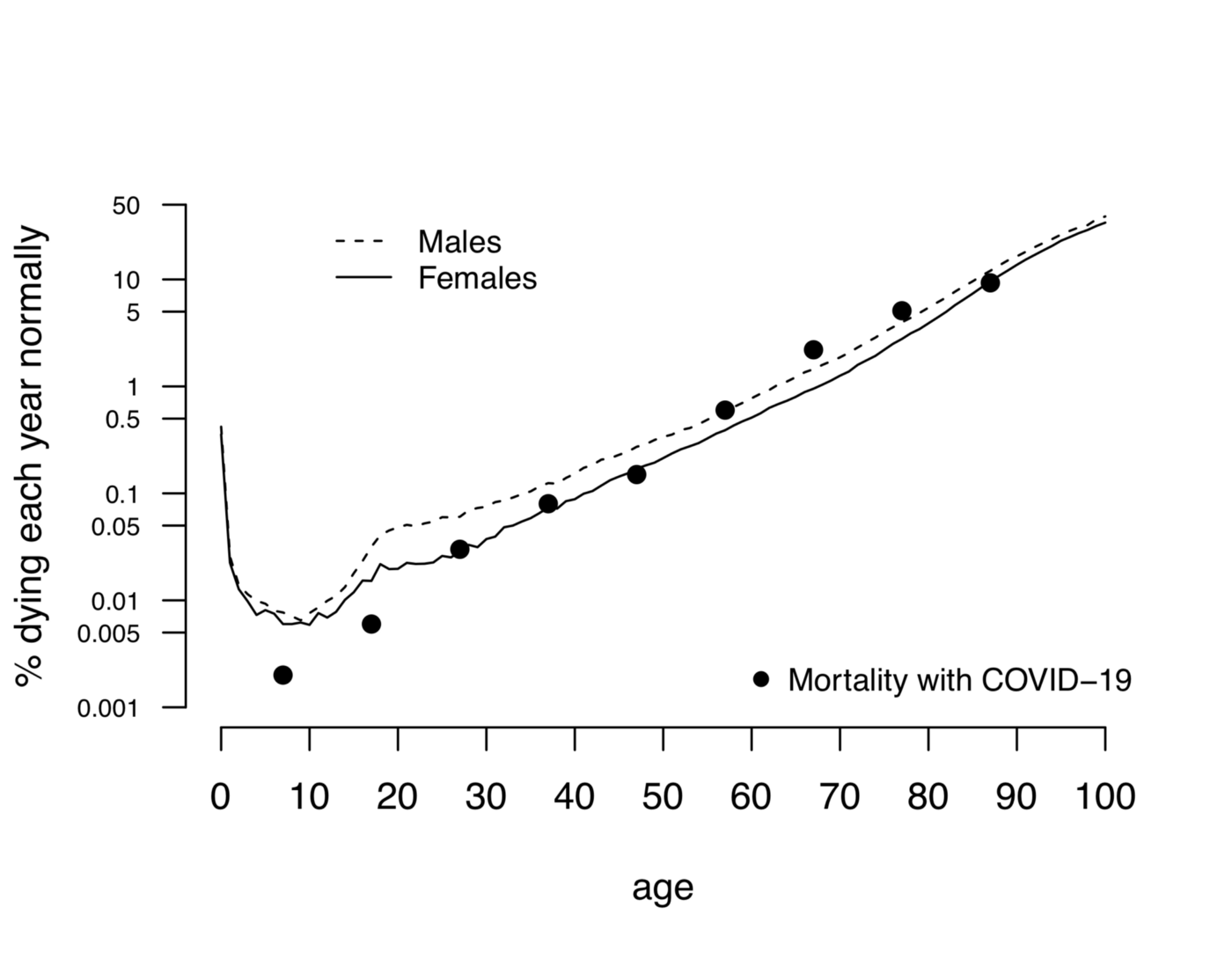
Сегодня у Поиска большое обновление. Например, ответы Нейро теперь будут появляться сразу в поисковых результатах — для тех запросов, где это полезно и экономит время. Но в рамках этой статьи нас интересует другая часть обновления: Нейро поможет найти ответы в Поиске по картинкам и в Умной камере — с помощью новой мультимодальной модели Яндекса. Пользователь может не только узнать, что изображено на картинке, но и задать вопрос по каждой её детали. Например, гуляя по музею, можно сфотографировать натюрморт голландского живописца и спросить, что символизирует тот или иной предмет на картине.
Меня зовут Роман Исаченко, я работаю в команде компьютерного зрения Яндекса. В этой статье я расскажу, что такое визуально‑текстовые мультимодальные модели (Visual Language Models или VLM), как у нас в Яндексе организован процесс их обучения и какая у них архитектура. Вы узнаете, как Нейро работал с картинками и текстами раньше, и что изменилось с появлением VLM.






 Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.
Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.