
В этой статье я хочу поговорить про интеграцию Apache Lucene и Hibernate Search. Если быть более точным, то про один из механизмов Hibernate Search, который может здорово увеличить производительность на проекте с полнотекстовым поиском.

Пользователь
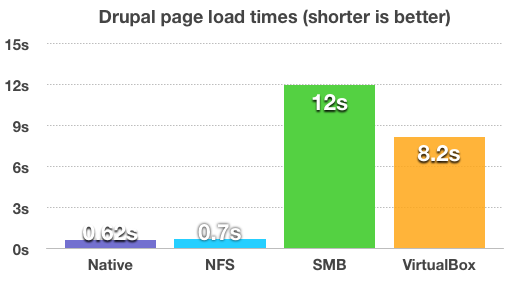
 Под катом расскажу как я усовершенствовал автоматическое создание и разворачивание окружения для веб-разработки на основе Docker, Fig, DNSMasq и nsenter. По сути, это разворачивание LAMP сервера и запись о нем в DNSMasq, но приоритетами являются незасоренность хост-машины ненужным софтом типа web-, db-серверов на хост машине и минимальное количество команд для запуска
Под катом расскажу как я усовершенствовал автоматическое создание и разворачивание окружения для веб-разработки на основе Docker, Fig, DNSMasq и nsenter. По сути, это разворачивание LAMP сервера и запись о нем в DNSMasq, но приоритетами являются незасоренность хост-машины ненужным софтом типа web-, db-серверов на хост машине и минимальное количество команд для запуска Введение
Базовый сценарий: Простой логический элемент в схеме
Цель
Стратегия №1: Произвольный локальный поиск
Стратегия №2: Числовой градиент
Стратегия №3: Аналитический градиент
Схемы с несколькими логическими элементами
Обратное распространение ошибки
Шаблоны в «обратном» потоке
Пример "Один нейрон"
Становимся мастером обратного распространения ошибки

 Play! и Lift, — эти два фреймворка являются олицетворением того, куда движется основной поток Scala веб-разработчиков. Воистину, попробуйте поискать на Stack Overflow фреймворки для Scala и вы поймете что я прав. Я верю, что процент здравомыслящих людей, которым надоели сложные комбайны, велик, поэтому расскажу про «другой» фреймворк Xitrum.
Play! и Lift, — эти два фреймворка являются олицетворением того, куда движется основной поток Scala веб-разработчиков. Воистину, попробуйте поискать на Stack Overflow фреймворки для Scala и вы поймете что я прав. Я верю, что процент здравомыслящих людей, которым надоели сложные комбайны, велик, поэтому расскажу про «другой» фреймворк Xitrum.
 Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными.
Во всех онлайн сервисах и играх самая большая доля аудитории уходит прямо на старте – в первые же минуты и часы знакомства с продуктом. Этой теме уже посвящены сотни книг и статей с самыми различными гипотезами успеха и причин лояльности аудитории – уникальность, простота, юзабилити, бесплатность, обучение или инструкция, эмоциональность, и еще множество факторов считаются крайне важными. 