
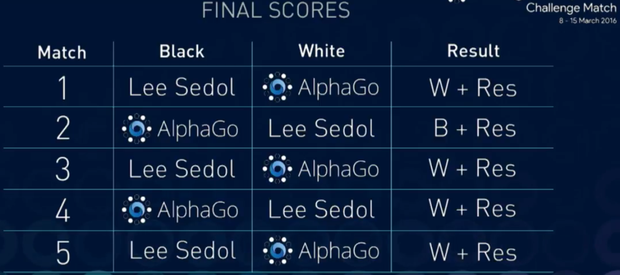
ИИ Google AlphaGo одержал победу и в пятой, заключительной партии в го, одолев одного из лучших игроков среди людей — Ли Седоля. На этот раз чемпион играл черными камнями, а программа — белыми. Корейский игрок в го старался постоянно атаковать противника, как и в четвертой, победной для себя партии. Тогда Седоль старался не давать инициативу своему виртуальному сопернику.
Как и в прошлый раз, время у игрока-человека закончилось быстрее, чем у машины, поэтому Седоль стал использовать дополнительное время, бёёми. Ему все же удалось несколько потревожить систему защиты AlphaGo, но ИИ решил эту проблему и вернул отвоеванные территории. Практически до самого конца игроки шли на равных, но Седолю все же пришлось признать поражение. Случилось это после пяти часов напряженной игры.
По словам представителей Google, организовавших эту игру, если бы Седоль выиграл у компьютера в большинстве партий, то он бы получил $1000000. Но поскольку победа осталась за AlphaGo, то миллион ушел на благотворительность.
#AlphaGo wins game 5 taking the historic match 4-1. Congrats DM team and Lee Sedol. Awesome displays of human ingenuity all round!
— Mustafa Suleyman (@mustafasuleymn) 15 марта 2016 г.
Сама программа для игры в Го была создана компанией DeepMind, купленной Google некоторое время назад. По мнению создателей программы, только за время обучения она обработала около 30 млн различных комбинаций, постепенно обучаясь различным методам и схемам игры. Используется и вычисление оптимальных комбинаций, но не для всей игры в целом, а только для решения часто возникающих локальных моментов.
Если вы вдруг пропустили трансляцию, вот видео с разбором «полетов»:
Ну и ссылочка на файл с ходами, если хотите разобраться детально.
Напомню, что Ли Седоль проиграл первую, вторую, третью и пятую партии машине. Четвертую партию он выиграл, о чем уже упоминалось выше.
