Недавно мы рассказывали здесь о том,
как делался проект «Весь Толстой в один клик». С помощью 3249 (трех тысяч двухсот сорока девяти) волонтеров и 1 (одной) хорошей
OCR-технологии мы оцифровали 46820 страниц 90-томного собрания сочинений писателя, тщательно вычитали их и
выложили во всеобщий доступ.
Но если вы думали, что наш «роман с Толстым» на этом закончился, то вы ошибались – оцифровав тексты писателя, мы начали исследовать их при помощи технологии извлечения информации ABBYY Compreno – не пропадать же такому богатому материалу. О том, что дал нам «text mining Толстого» и где теперь используются полученные результаты, читайте дальше.
Введение
Главной целью проекта «Весь Толстой в один клик» было сделать творчество Толстого по-настоящему всеобщим достоянием, чтобы все вышедшие из-под его пера тексты были доступны в один клик в любой точке Земли. Как, кстати, и завещал сам автор, еще при жизни отказавшийся от всех прав на свои тексты (да-да, анонимус, Лев Толстой
знал про копилефт и опендату задолго до этих ваших интернетов и Ричарда Столлмана).
Однако возможность загрузить книжку в удобном формате в ридер или планшет – не единственный плюс оцифровки. Теперь тексты Толстого можно не только читать, но и «измерять», то есть исследовать разными количественными методами, используя весь арсенал средств автоматической обработки текста (АОТ, она же NLP). Ведь если у вас есть все тексты писателя в электронном виде, даже с помощью одного-двух грамотных поисковых запросов вы можете получить любопытные данные, на добычу которых в иные времена мог потратить недели и месяцы упорного труда какой-нибудь литературовед. А уж если у вас к тому же имеется
продвинутая технология анализа естественного языка, то есть шансы сделать серьезное филологическое открытие (даже не будучи филологом). Ниже я расскажу, что удалось намерить и узнать нам, но перед этим – пара слов о том, кто, как и зачем занимается автоматической обработкой художественных текстов и что интересного может при этом получиться.

 В чем разница между двумя этими определениями инициализированных локальных переменных С/С++?
В чем разница между двумя этими определениями инициализированных локальных переменных С/С++? Но для начала – маленькое отступление. Систему распознавания текста в наших продуктах можно описать очень просто. У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы. Задача сегментации ставится примерно так: есть страница, надо её декомпозировать на текстовые и нетекстовые элементы.
Но для начала – маленькое отступление. Систему распознавания текста в наших продуктах можно описать очень просто. У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы. Задача сегментации ставится примерно так: есть страница, надо её декомпозировать на текстовые и нетекстовые элементы. 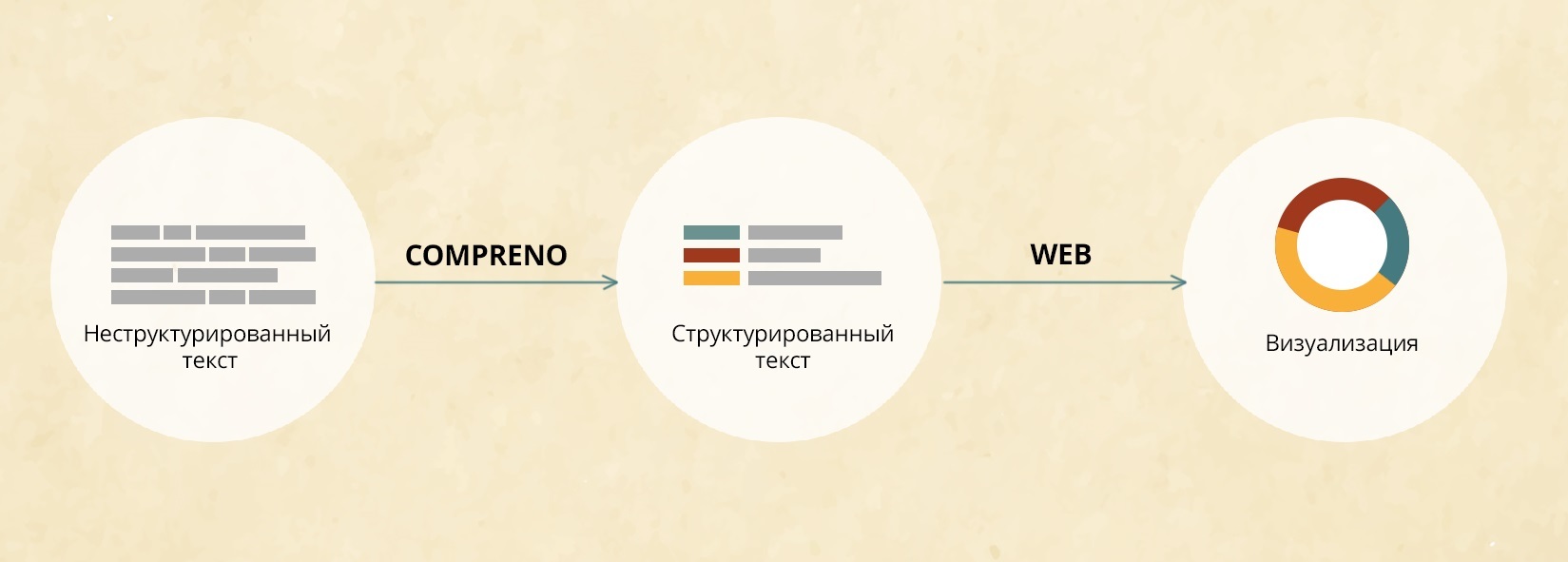
 Новейшая история денежного обращения в Бразилии – это череда деноминаций, первая из которых была проведена в 1942 году, а последняя – в 1994 году. К 1994 году национальная валюта Бразилии – крузейро – была настолько слабой, что в магазинах цены назначались в условных единицах, рядом с цифрами писали слово “real” – «настоящая» цена. В 1994 от лишних нулей решили избавиться, а слово “real”, к которому все привыкли, стало названием новой валюты – реал (впрочем, точно так же называлась денежная единица Бразилии до 1942 года).
Новейшая история денежного обращения в Бразилии – это череда деноминаций, первая из которых была проведена в 1942 году, а последняя – в 1994 году. К 1994 году национальная валюта Бразилии – крузейро – была настолько слабой, что в магазинах цены назначались в условных единицах, рядом с цифрами писали слово “real” – «настоящая» цена. В 1994 от лишних нулей решили избавиться, а слово “real”, к которому все привыкли, стало названием новой валюты – реал (впрочем, точно так же называлась денежная единица Бразилии до 1942 года). 


 При съемке книжного разворота с помощью камеры мобильного устройства неизбежно возникают некоторые из нижеперечисленных дефектов (а возможно, что и все сразу):
При съемке книжного разворота с помощью камеры мобильного устройства неизбежно возникают некоторые из нижеперечисленных дефектов (а возможно, что и все сразу): В последнее время мы довольно часто рассказываем в блоге о наших технологиях распознавания, которые работают на мобильных устройствах и распознают фотографии, сделанные камерами этих устройств. Сейчас мы движемся дальше и учимся работать не с фотографиями, а с видеопотоком. И сегодня мы хотим рассказать вам чуть подробней, что это означает и где в повседневной жизни может пригодиться распознавание текста из видеопотока.
В последнее время мы довольно часто рассказываем в блоге о наших технологиях распознавания, которые работают на мобильных устройствах и распознают фотографии, сделанные камерами этих устройств. Сейчас мы движемся дальше и учимся работать не с фотографиями, а с видеопотоком. И сегодня мы хотим рассказать вам чуть подробней, что это означает и где в повседневной жизни может пригодиться распознавание текста из видеопотока. Очень удобно, когда благодаря правильно выбранным умолчаниям все работает само и «из коробки» и не нужно ничего настраивать. Эта история о том, что выбранные умолчания должны быть работоспособными всегда, в противном случае есть риск непредвиденного отказа после многих лет беспроблемной работы.
Очень удобно, когда благодаря правильно выбранным умолчаниям все работает само и «из коробки» и не нужно ничего настраивать. Эта история о том, что выбранные умолчания должны быть работоспособными всегда, в противном случае есть риск непредвиденного отказа после многих лет беспроблемной работы. Перенос OCR-технологий (технологий оптического распознавания) с ПК на мобильные устройства обсуждался, пожалуй, с момента их появления. Ещё в конце 90-х, когда «умные» устройства можно было пересчитать по пальцам, мы задумывались о создании программы, извлекающей данные из визитной карточки, – Business Card Reader, или сокращённо BCR. Эта идея, что называется, витала в воздухе, но ни возможности камер, ни вычислительная мощность устройств не позволяли тогда реализовать её. Выбирать особо не приходилось: либо обычный телефон с хорошей камерой «для обычных людей», либо продвинутый бизнес-наладонник «для профессионалов» (а зачем вообще бизнесменам нужны камеры на устройстве — себя, что ли, фотографировать?)
Перенос OCR-технологий (технологий оптического распознавания) с ПК на мобильные устройства обсуждался, пожалуй, с момента их появления. Ещё в конце 90-х, когда «умные» устройства можно было пересчитать по пальцам, мы задумывались о создании программы, извлекающей данные из визитной карточки, – Business Card Reader, или сокращённо BCR. Эта идея, что называется, витала в воздухе, но ни возможности камер, ни вычислительная мощность устройств не позволяли тогда реализовать её. Выбирать особо не приходилось: либо обычный телефон с хорошей камерой «для обычных людей», либо продвинутый бизнес-наладонник «для профессионалов» (а зачем вообще бизнесменам нужны камеры на устройстве — себя, что ли, фотографировать?)  Несколько лет назад в нашем блоге был
Несколько лет назад в нашем блоге был  В этой статье мы бы хотели обратить внимание разработчиков приложений на такой неоднозначный механизм продвижения, как фичеринг в магазинах мобильных приложений (AppStore и Google Play). Да, нашему редактору тоже не нравится слово «фичеринг» (featuring), но адекватного русского аналога нет, поэтому будем использовать кальку с английского.
В этой статье мы бы хотели обратить внимание разработчиков приложений на такой неоднозначный механизм продвижения, как фичеринг в магазинах мобильных приложений (AppStore и Google Play). Да, нашему редактору тоже не нравится слово «фичеринг» (featuring), но адекватного русского аналога нет, поэтому будем использовать кальку с английского. Это пост о сложностях взаимодействия искусственного и естественного интеллекта. Современные компиляторы имеют довольно развитые средства статического анализа, которые умеют выдавать предупреждения на разные подозрительные конструкции в коде. В теории эти предупреждения должны помочь разработчикам делать меньше ошибок в коде.
Это пост о сложностях взаимодействия искусственного и естественного интеллекта. Современные компиляторы имеют довольно развитые средства статического анализа, которые умеют выдавать предупреждения на разные подозрительные конструкции в коде. В теории эти предупреждения должны помочь разработчикам делать меньше ошибок в коде.
 Количество программ — мобильных клиентов, привязанных к различным системам автоматизации деятельности предприятий, постоянно растёт. Согласно
Количество программ — мобильных клиентов, привязанных к различным системам автоматизации деятельности предприятий, постоянно растёт. Согласно  Соревнования по различным аспектам анализа текста проводятся на международной конференции по компьютерной лингвистике «Диалог» каждый год. Обычно сами соревнования проходят в течение нескольких месяцев до мероприятия, а на самой конференции объявляют результаты. В этом году планируются три соревнования:
Соревнования по различным аспектам анализа текста проводятся на международной конференции по компьютерной лингвистике «Диалог» каждый год. Обычно сами соревнования проходят в течение нескольких месяцев до мероприятия, а на самой конференции объявляют результаты. В этом году планируются три соревнования: