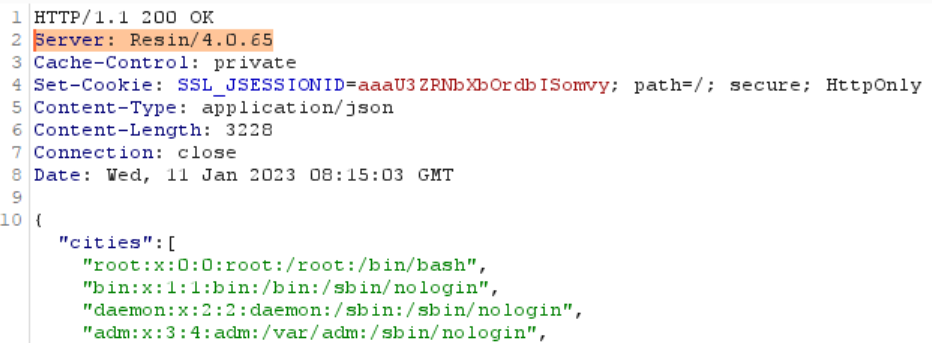
Привет, Хабр и его жители! Я, Максим Санджиев, представляю отдел, занимающийся развитием, поддержкой и безопасностью инфраструктуры в департаменте Security Services компании «Лаборатории Касперского». У нас в отделе накопилась «нестандартная» экспертиза по работе с vault, IAM (keycloak), rook-ceph, minio s3, prometheus, k8s и многими другими инструментами OPS/SecOps/SRE. Хотели бы с вами поделиться нашими ресерчами, идеями, самописными разработками и получить фидбэк на наши реализации. Начнем с кейсов по работе с IAM.

Эта статья рассчитана на людей, которые ранее были знакомы с IAM и, в частности, с keycloak-ом. Поэтому в этой части не будет «базы» по SAML2, OAuth2/OIDC и в целом по IAM (на Хабре есть хорошие статьи на эту тему).
Рассмотрим два кейса:
Эта статья рассчитана на людей, которые ранее были знакомы с IAM и, в частности, с keycloak-ом. Поэтому в этой части не будет «базы» по SAML2, OAuth2/OIDC и в целом по IAM (на Хабре есть хорошие статьи на эту тему).
Рассмотрим два кейса:
- Есть учетная запись (УЗ) в keycloak с правами админа на какой-то веб-ресурс. Как, используя keycloak, сделать так, чтобы для входа админу требовался дополнительный фактор аутентификации?
- Есть веб-ресурс (client в терминологии keycloak). Как дать доступ к этому веб-ресурсу средствами keycloak на этапе аутентификации определенной группе пользователей (в ситуации, когда это не реализовано самим приложением)?