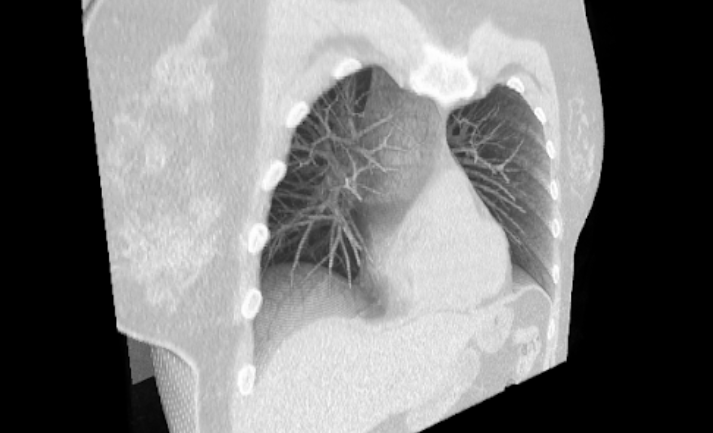
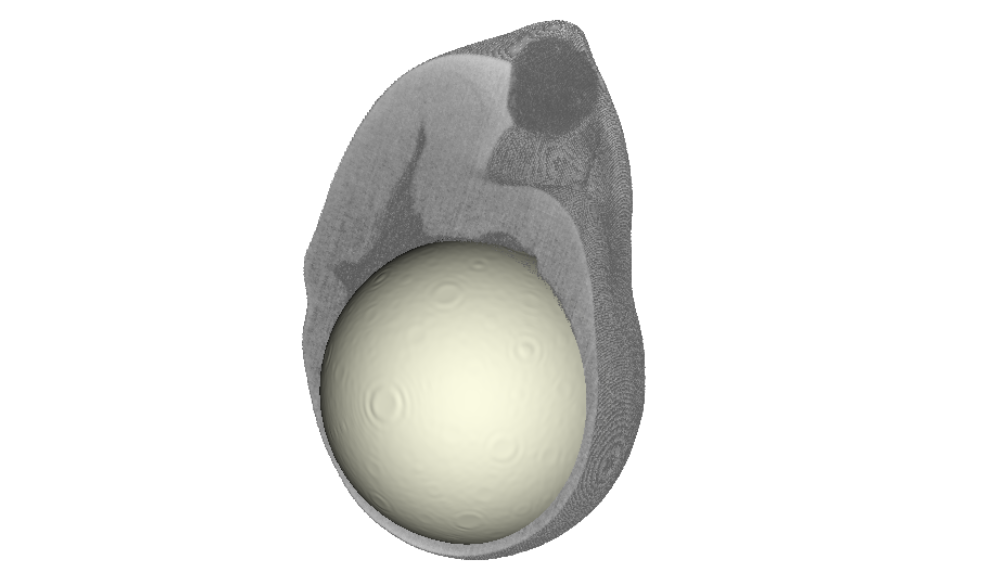
Привет, Хабр! Еа связи Smart Engines. Вы же помните, что кроме распознавания документов мы занимаемся и томографией.
Сегодня мы продолжаем нашу серию статей про фантомы для томографии. Мы уже рассмотрели медицинские тестово‑калибровочные фантомы, антропоморфные фантомы и ответили на вопрос: "Что такое пространственное разрешение в томографии и как его измерить?"
Дальнейшее продолжение предполагает рассказ о фантомах, полученных с помощью математических формул. Сегодня мы расскажем о самых первых математических фантомах, которые моделируют голову человека и его мозг, в частности. Такие фантомы нужны для различных рассчетов, а для каких именно - рассказываем под катом.