Статья написана совместно с ananaskelly.
Введение
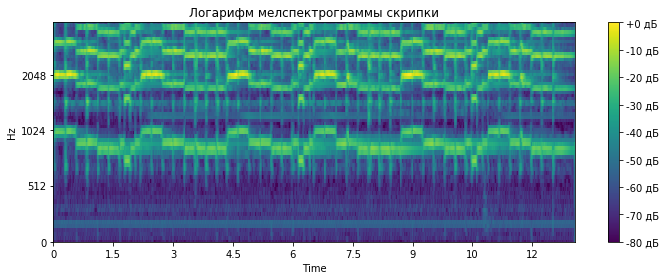
Всем привет, хабр! Работая в Центре Речевых Технологий в Санкт-Петербурге, мы накопили немного опыта в решении задач классификации и детектирования акустических событий и решили, что готовы им с вами поделиться. Цель этой статьи — познакомить вас с некоторыми задачами и рассказать о соревновании по автоматической обработке звука “DCASE 2018”. Рассказывая вам о конкурсе, мы обойдемся без сложных формул и определений, связанных с машинным обучением, таким образом общий смысл статьи будет понятен широкой аудитории.
Для тех, кого в названии привлекла именно сборка классификатора, мы подготовили небольшой код на python, и по ссылке на гитхабе вы можете найти notebook, где мы на примере второго трека конкурса DCASE создаем простую сверточную сеть на keras для классификации аудиофайлов. Там мы немного рассказываем о сети и признаках, используемых для обучения, и как с помощью простой архитектуры получить близкий к baseline результат (MAP@3 = 0.6).
Дополнительно здесь будут описаны базовые подходы для решения задач (baseline), предложенные организаторами. Также в будущем появится несколько статей, где мы будем более подробно и в деталях рассказывать как о нашем опыте участия в соревновании, так и о решениях, предложенных другими участниками конкурса. Ссылки на эти статьи будут постепенно появляться здесь.