Комментарии 38
там фишка в том, что бы сначала использовать выход pool5 слоя для сегментации, и по этой маске считать матрицы Грама, результат реально крутой
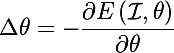
мы получим такое значение параметров, что если изменить текущие значение параметров на это полученное, то значение функции ошибки будет меньше

но тоже самое будет если считать, что параметры theta фиксированы, а изображение нет
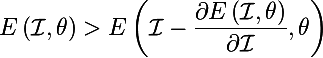
но нейросеть — это суперпозиция функций, и если вместо E взять нейрон отвечающий за некоторый класс i, а это тоже функция fi, тогда будет верно следующее
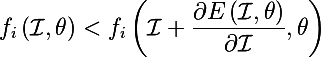
т.е. нам нужно найти такую картинку, что если ее прибавить к текущей, значение нейрона отвечающего за класс (или фичу) стало больше (т.е. класс/фича стали более ярко выраженны)
Я правильно понимаю, что коэфициенты нейросети давно посчитаны, и они в открытом доступе?
Т.е. вычисления можно засунуть в какой-нибудь шейдер, и делать это real-time 60 раз в секунду?
Обратная свертка не очень понятна, но я принял ее за догму )
вообще операцию свертки можно представить как матричное произведение развернутой по особому образу картинки Ie на ядро свертки K в результате чего получается некоторый результат F; тогда просто можно выразить исходную картинку
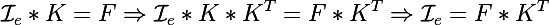
Я правильно понимаю, что коэфициенты нейросети давно посчитаны, и они в открытом доступе?
да верно, у той сети, из которой мы вычисляем фичи стиля и контента, веса фиксированны (например сеть обученная на имаджнете)
Т.е. вычисления можно засунуть в какой-нибудь шейдер, и делать это real-time 60 раз в секунду?
так фреймворки и делают
Спасибо за пост, а то у самого разобраться руки бы еще долго не дошли.
з.ы. по поводу видеоролика в конце видео: тут надо полагать использовался некий оптический поток для темпоральной регуляризации? Иначе не понятно, как между кадрами стиль так удачно и однообразно применился.
А можно ли обучить сетку на наборе изображений? Например, ваши домики в стиле ван Гога однозначно выдают всем известную картину. Можно ли будет сгенерировать на основе пары десятков картин новую картину в стиле того же ван Гога или Пикассо (относительно узнаваемые стили) но при этом не похожую однозначно на какую то конкретно картину из набора скормленных сетке?
Возможно я сейчас спросил глупость и это уже у каждого в смартфоне, просто практической стороной вопроса не увлекаюсь как-то.
Но (если честно) выглядит как попытка кинуть камень в спину Prisma и Юрия Гурского. Мол, «посмотрите, в этой вашей Prisma никакой магии нет — любой может запилить такое же приложение». Хотя это лишь субъективное впечатление основанное на вступлении и интонациях текста, а матчасть все равно отличная.
а так то моя задача — это подготовка к своему курсу по нейросетям в техносфере МГУ, там кстати будет домашка для студентоты как раз написать стилизацию; в ШАДе студенты еще с прошлого года делают такую домашку
Вот из-за таких подколов и написал, что выглядит как попытка постебаться с Призмы. Скользит раздражение, так сказать. Но, в любом случаи, спасибо за прекрасный текст!
Ну все-таки просто "гитклонить" это даже обидно звучит. Я нигде не утверждал, что мы изобрели что-то уникальное, дело в оптимизациях и тюнинге. Мы все-таки больше делаем продукт, чем исследование. Но исследованием немного занимаемся.
Статья отличная.
Prism — это стартап, который делал продукт, а не алгоритм. Весь ресерч еще до них сделали и поделились кодами.
Собственно вопрос в том, куда можно посмотреть в сторону этого другого? Если я например хочу применить стиль к картинке 10Кх10К?
в процессе генерации, вам не нужно будет вычислять лосс функцию
Но для размера 1400х1020 она отжирает 9 гиг памяти.
Поэтому вопрос 10к на 10к остается открытым.
Кстати я все еще не понимаю почему для сети есть зависимость от роста изображения. Ведь размер самой сети фиксирован.
Должна же быть возможность порезать картинку на части и скармливать по отдельности. Или сделать что-то типа страйдов, чтобы сгладить переходы.
если же говорим о loss сети, то там от картинки зависит размер выходного тензора, он то и занимает много места в памяти
если скармливать по частям, то нет гарантии что соседние патчи будут одинаково сгенерированы так, что не будет видно границы, даже если делать с наложением, но я сам это не пробовал, так что можете попробовать и скинуть картинку -)
http://timdettmers.com/2015/03/09/deep-learning-hardware-guide/
https://www.quora.com/Is-there-any-specialized-hardware-for-deep-learning-algorithms
Стилизация изображений с помощью нейронных сетей: никакой мистики, просто матан