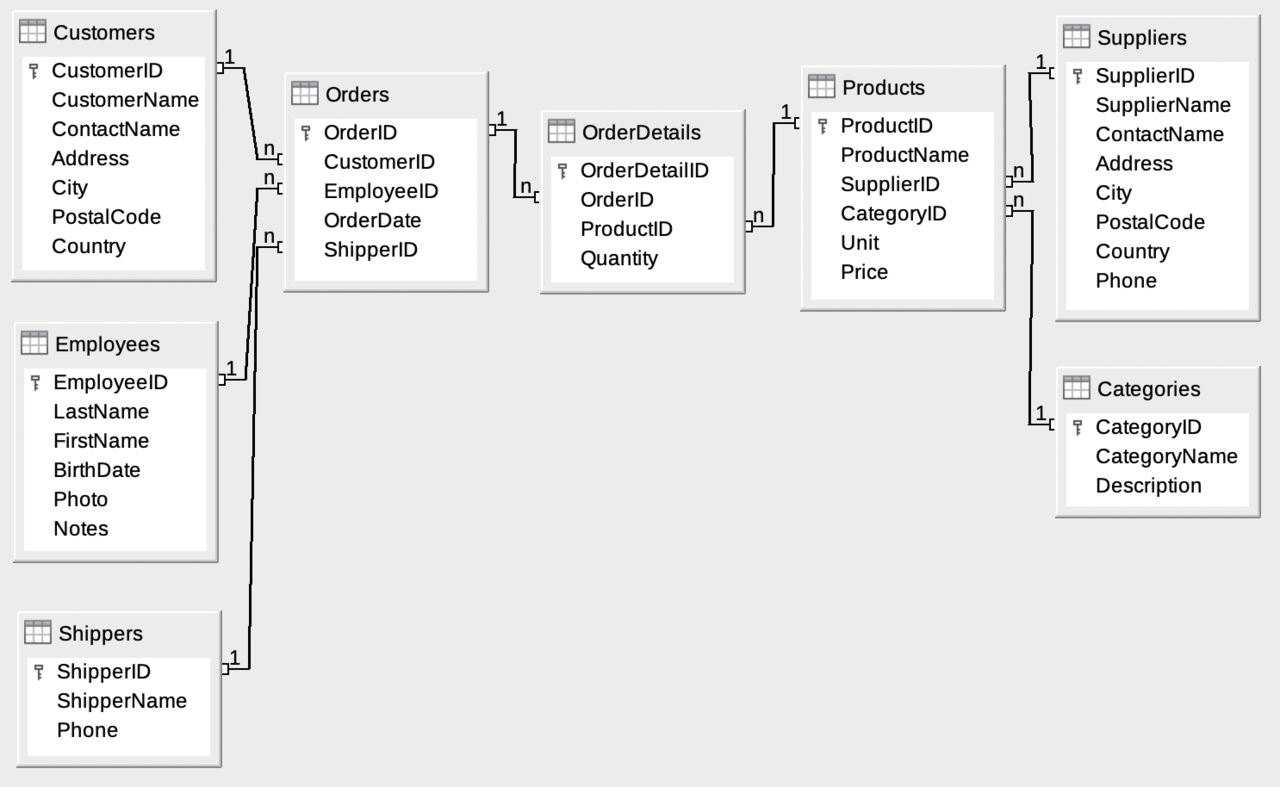
Как следует из названия, данная статья для тех, у кого есть сложности с пониманием SQL запросов, в составе которых, используется EXISTS, т.к., исходя из опыта, его использование частенько вызывает вопросы у начинающих, а иногда даже у продолжающих.
Стандартное описание работы оператора EXISTS, для SQL, выглядит примерно так: “Оператор EXISTS возвращает true, если подзапрос возвращает одну, или более записей, в противном случае, возвращает false”.
И еще: “Поскольку возвращения набора строк не происходит, то подзапросы с подобным оператором выполняются довольно быстро.”
Непонимание, обычно, как раз кроется, где-то здесь: Если EXISTS возвращает true/false, но не возвращает набор записей, то каким образом, основной запрос, в ходе выполнения, отбирает записи, соответствующие условиям описанным во вложенном запросе.