
Применение нелинейной динамики и теории Хаоса к задаче разработки нового алгоритма сжатия аудио данных
12 мин
В данной публикации я хотел бы представить ряд идей и опыт практического воплощения элемента теории Хаоса — фрактального преобразования в проекте разработке нового алгоритма сжатия аудио данных.
Чего вы не найдёте здесь:
Что вы найдёте здесь:
Чего вы не найдёте здесь:
- Сложных уравнений. Цель данной публикации является представление идей и видение задачи. И как любое видение оно во многом абстрактно;
- Каких либо генераторов фрактальных изображений. Такие изображения выглядят интересно, но мня интересуют реальные задачи.
Что вы найдёте здесь:
- Краткий обзор применения фрактальных преобразований к задаче сжатия данных с потерями;
- Необычная интерпретация фрактальных преобразований;
- Ссылки на реальный код компрессора и декомпрессора аудио данных посредством фрактальных преобразований (декомпрессор представлен в форме плагина для аудио плейера Winamp);
- Описание нового формата для хранения сжатых аудио данных с пятью уникальными свойствами, отличающими новый формат от многих хорошо известных индустриальных аудио форматов.






 Привет, Хабражитель!
Привет, Хабражитель!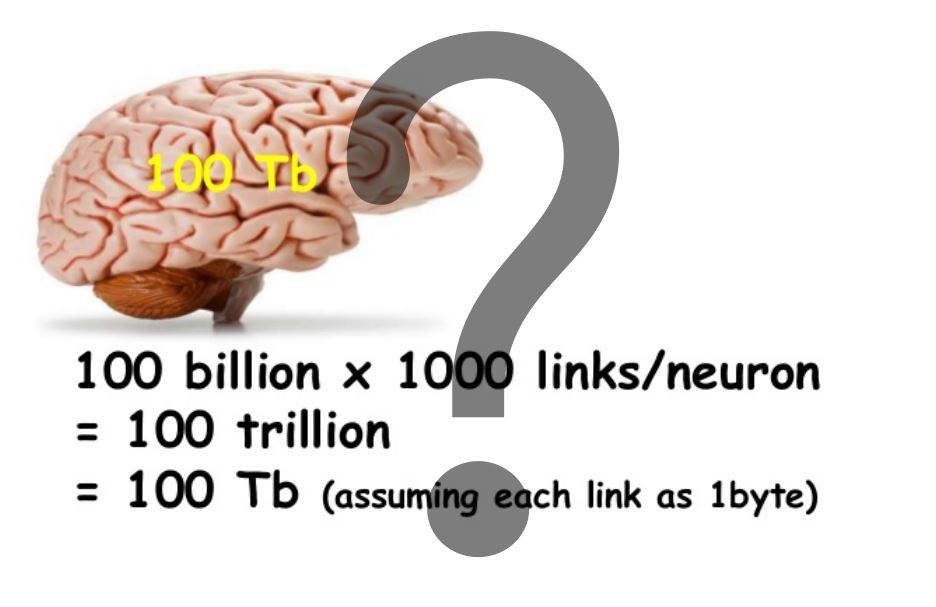 Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
") ,
, )") — пересечение полуплоскостей,
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).

 Ранее мы описали клеточный автомат, в котором могут возникать волны, имеющие хитрый внутренний узор. Мы показали, что такие волны способны распространять информацию по поверхности автомата. Оказалось, что любое место автомата может быть, как приемником, так и источником волн. Чтобы принять волну в каком-либо месте, достаточно посмотреть, какой узор получается в нем в момент прохождения волны. Если этот узор запомнить и впоследствии воспроизвести в том же месте, то от этого узора распространится волна, повторяющая на своем пути узор исходной волны.
Ранее мы описали клеточный автомат, в котором могут возникать волны, имеющие хитрый внутренний узор. Мы показали, что такие волны способны распространять информацию по поверхности автомата. Оказалось, что любое место автомата может быть, как приемником, так и источником волн. Чтобы принять волну в каком-либо месте, достаточно посмотреть, какой узор получается в нем в момент прохождения волны. Если этот узор запомнить и впоследствии воспроизвести в том же месте, то от этого узора распространится волна, повторяющая на своем пути узор исходной волны.
