Лекции Техносферы. 1 семестр. Введение в анализ данных (весна 2016)
3 мин
Слушайте и смотрите новую подборку лекций Техносферы Mail.Ru. На этот раз представляем в открытом доступе весенний курс «Введение в анализ данных», на котором слушателей знакомят со сферой анализа данных, основными инструментами, задачами и методами, с которыми сталкивается любой исследователь данных в работе. Курс преподают Евгений Завьялов (аналитик проекта Поиск Mail.Ru, занимающийся извлечением полезных бизнесу знаний из данных, генерируемых поисковым движком и десктопными приложениями), Михаил Гришин (программист-исследователь из отдела анализа данных) и Сергей Рыбалкин (старший программист из студии Allods Team).
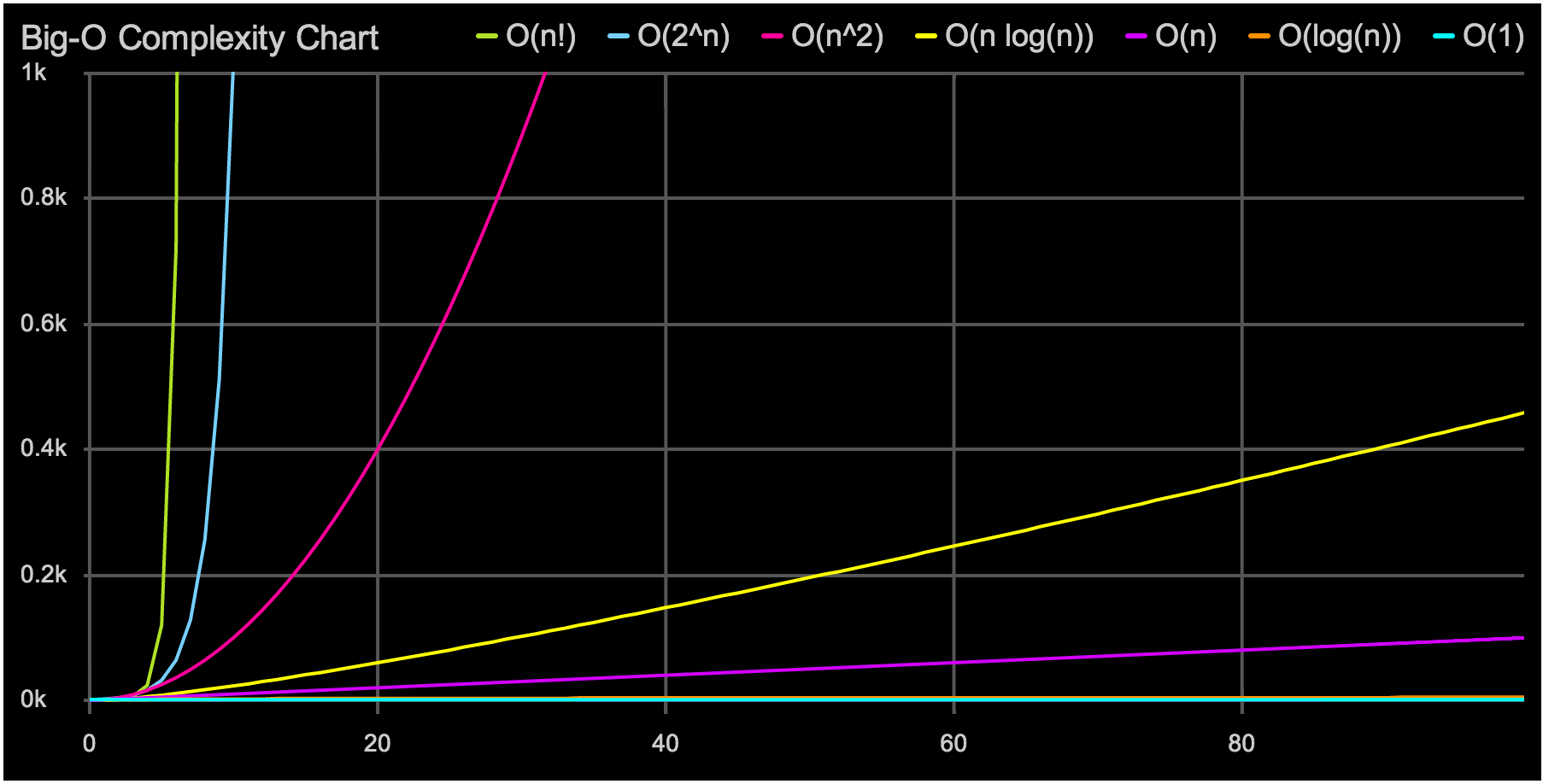
Из первой лекции вы узнаете, что такое анализ данных, какие инструменты используют для анализа данных, а также как работает Python.
Лекция 1. Введение в Python
Из первой лекции вы узнаете, что такое анализ данных, какие инструменты используют для анализа данных, а также как работает Python.





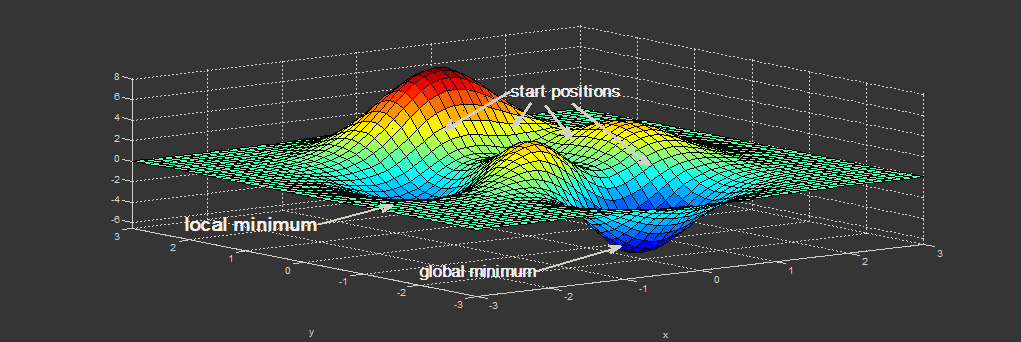
") ,
, )") — пересечение полуплоскостей,
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).