Метод конечных элементов своими руками
Метод конечных элементов (МКЭ) применяют в задачах упругости, теплопередачи, гидродинамики — всюду, где нужно как-то дискретизировать и решить уравнения сплошной среды или поля. На Хабре было множество статей с красивыми картинками о том, в каких отраслях и с помощью каких программ этот метод приносит пользу. Однако мало кто пытался объяснить МКЭ от самых основ, с простенькой учебной реализацией, желательно без упоминания частных производных через каждое слово.
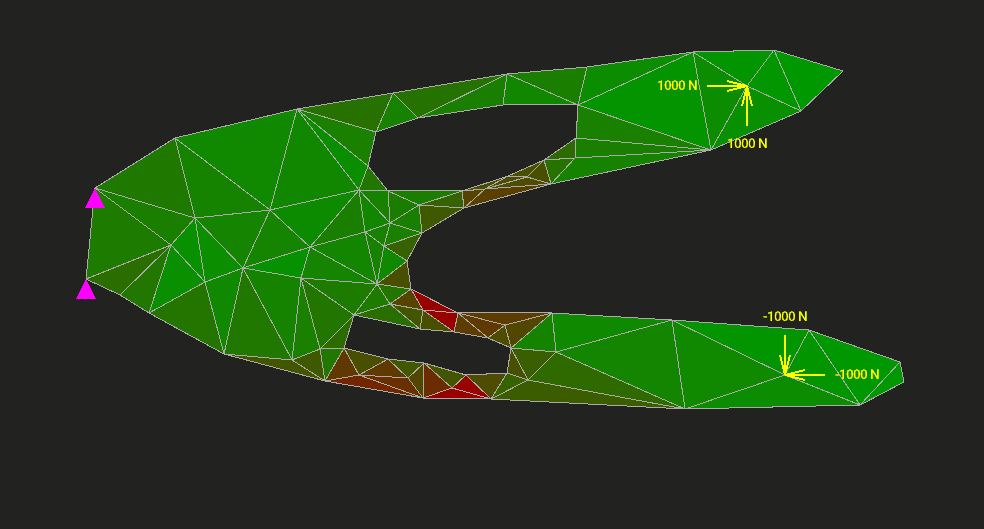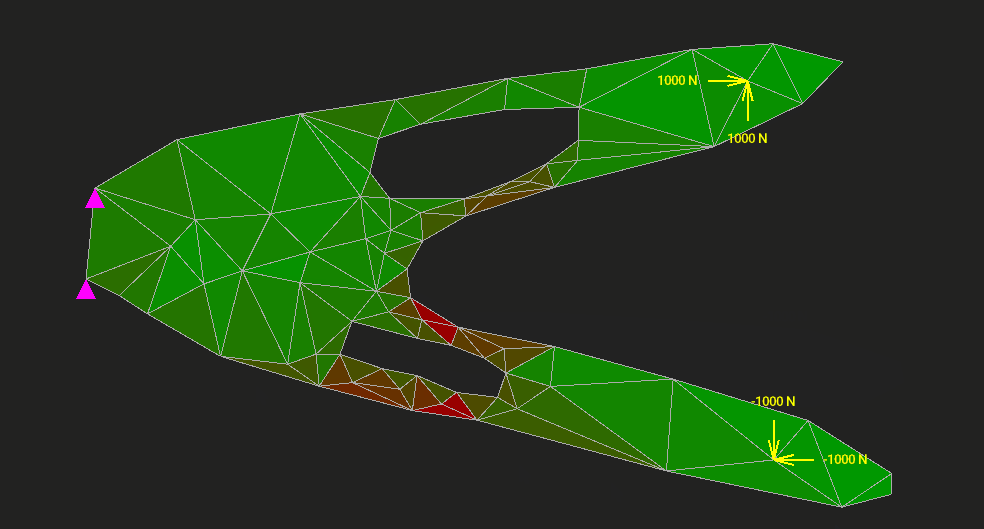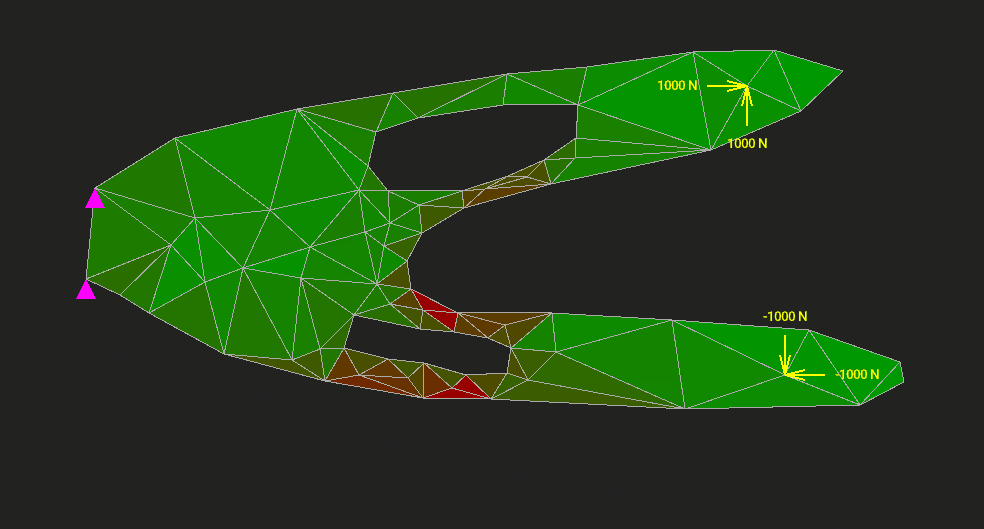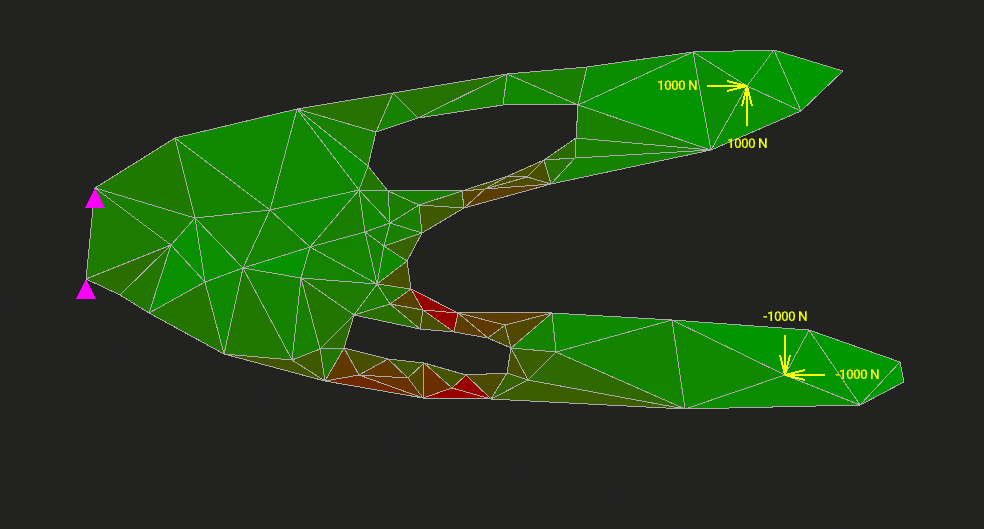
Мы напишем МКЭ для расчёта упругой двумерной пластины на прочность и жёсткость. Код займёт 1200 строк. Туда войдёт всё: интерактивный редактор, разбиение модели на треугольные элементы, вычисление напряжений и деформаций, визуализация результата. Ни одна часть алгоритма не спрячется от нас в недрах MATLAB или NumPy. Код будет ужасно неоптимальным, но максимально ясным.
Размышление над задачей и написание кода заняли у меня неделю. Будь у меня перед глазами такая статья, как эта, — справился бы быстрее. У меня её не было. Зато теперь она есть у вас.