
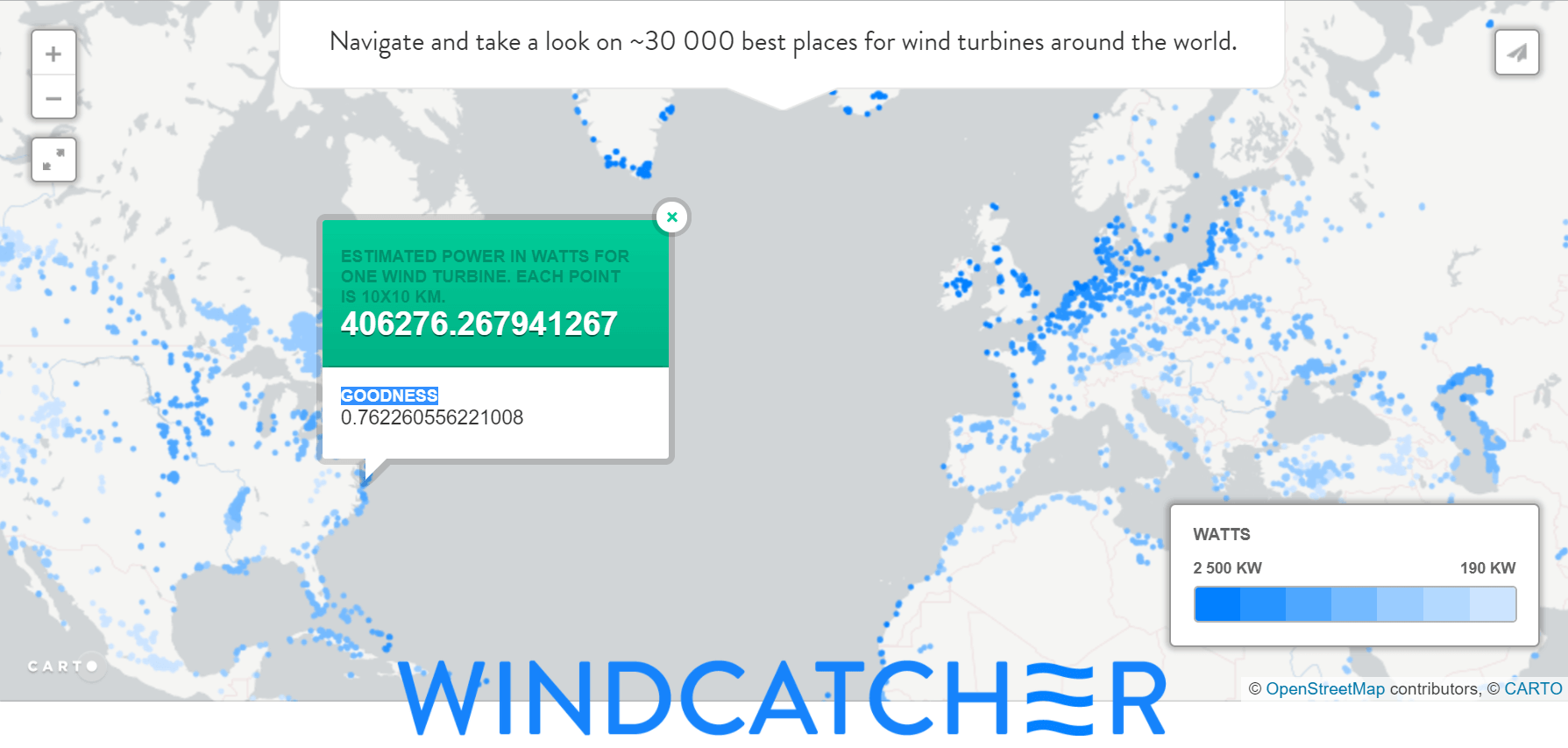
История о том, как NASA, ESA, Датский Технологический Университет, нейронные сети, деревья решений и прочие хорошие люди помогли найти мне лучший бесплатный гектар на Дальнем Востоке, а также в Африке, Южной Америке и других “так себе” местах.
Сделайте для нас еще одну программу, где мы бы могли научиться работать с Kafka, Elasticsearch и разными инструментами экосистемы Hadoop, чтобы собирать пайплайны данных.
Data Engineer'ы – это очень горячие вакансии!
Реально их уже на протяжении полугода никак не можем закрыть.
Очень здорово, что вы обратили внимание именно на эту специальность. Сейчас на рынке очень большой перекос в сторону Data Scientist'ов, а больше половины работы по проектам – это именно инженерия.

replyr — сокращение от REmote PLYing of big data for R (удаленная обработка больших данных в R). replyr? Потому что он позволяет применять стандартные рабочие подходы к удаленным данным (базы данных или Spark).data.frame. replyr предоставляет такие возможности:replyr_summary().replyr_union_all().replyr_bind_rows().dplyr::do()): replyr_split(), replyr::gapply().replyr_moveValuesToRows() / replyr_moveValuesToColumns().Spark и sparklyr гораздо легче.replyr — продукт коллективного опыта использования R в прикладных решениях для многих клиентов, сбора обратной связи и исправления недостатков.
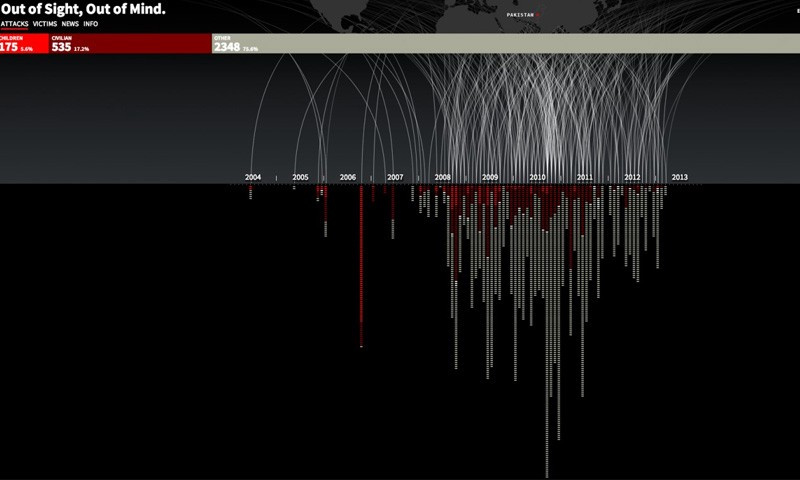


7 июля Science Slam Digital собрал в нашем офисе более 600 зрителей, а число просмотров трансляции в соцсетях Одноклассники и ВКонтакте превысило 420 тысяч. Формат Science Slam зародился в Германии семь лет назад для популяризации научных достижений среди простых обывателей. Он состоит из серии научных лекций, которые читают молодые ученые. Доклад участника должен быть коротким (10 минут), доступным и информативным. Победителя слема определяют с помощью определения громкости аплодисментов зрителей шумометром.
Нам очень понравился этот формат, и мы захотели провести свой Science Slam, только цифровой, чтобы рассказать о технологиях просто и понятно. О том, что происходит внутри компании и чем занимаются сотрудники. Шесть разработчиков рассказали гостям и зрителям трансляции, что можно определить по почте, не открывая самих писем; как выяснить возраст человека в социальных сетях, даже если он не указан; какие тренды в медиапотреблении можно выделить уже сейчас и как они влияют на восприятие информации; как модифицировать социальную сеть, которой пользуются 100 миллионов человек, чтобы у них ничего не сломалось. Как это у нас получилось, вы можете посмотреть по нашим докладам.

Яндекс уже несколько лет сотрудничает с ЦЕРНом. Он сделал для учёных-физиков поиск по событиям в БАК, предоставил свои вычислительные ресурсы и технологии обработки данных — в том числе Матрикснет и ClickHouse. В 2014 году Яндекс стал ассоциированным членом CERN openlab.
Школа анализа данных Яндекса принимает участие в двух экспериментах ЦЕРНа — SHiP и LHCb. Машинное обучение в наши дни становится «микроскопом» для современных учёных, которым необходимо изучать большие объемы данных и находить в них различные закономерности. В этом году ШАД совместно с лабораторией Методов анализа больших данных Вышки и Имперским колледжем Лондона организует в Великобритании международную школу, которая посвящена способам применения современных технологий в научных исследованиях.
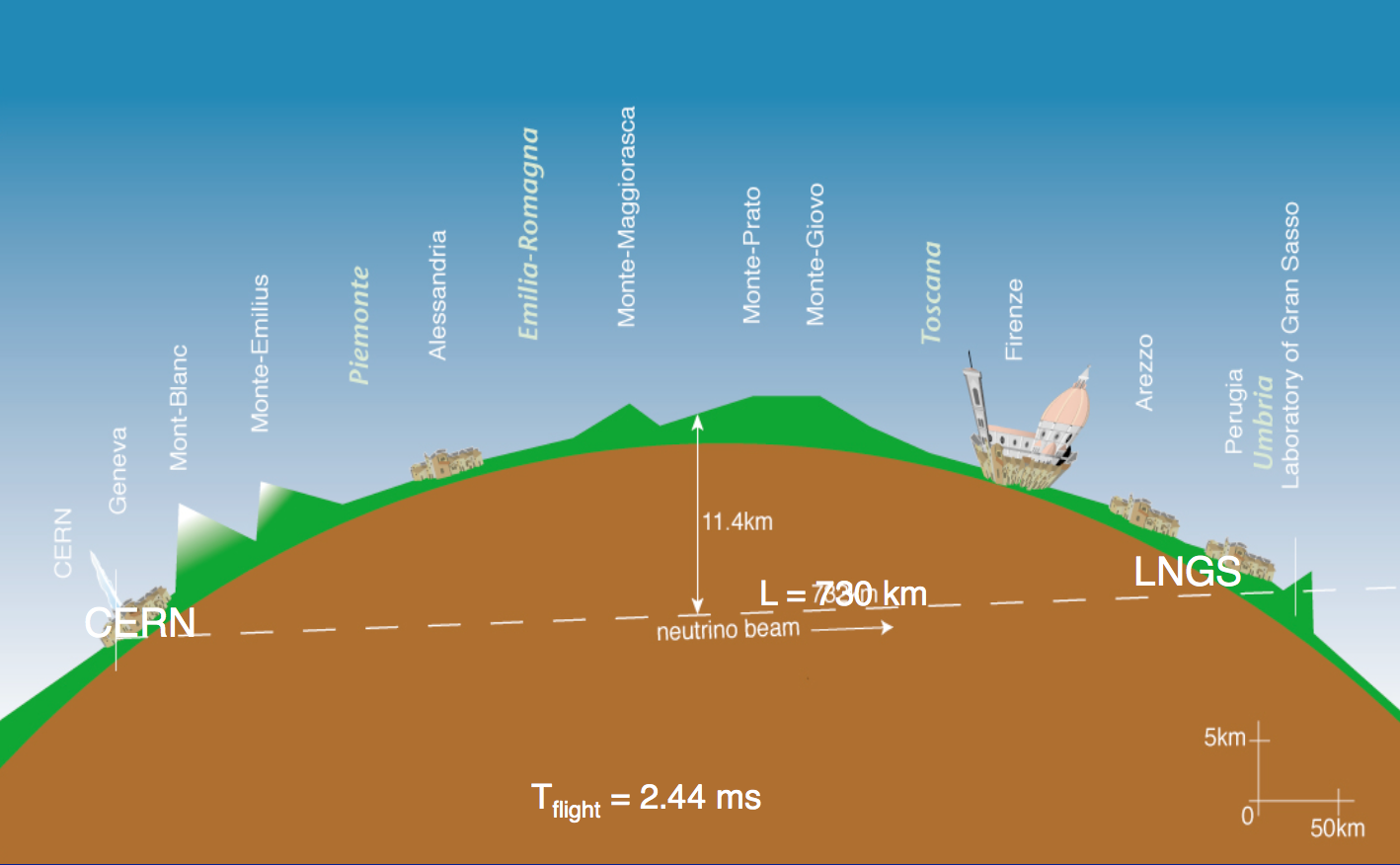
Эксперимент OPERA — из Швейцарии в Италию (картинка взята с сайта коллаборации OPERA)
Сегодня в рамках школы начинается открытое соревнование, участники которого будут ни много ни мало искать нейтрино. Принять участие в поисках мы приглашаем всех желающих. Им предстоит обрабатывать данные с международного эксперимента OPERA. Для этого будут предоставлены исходные данные — результаты сканирования слоев фотопленок одного «кирпича» эксперимента OPERA. Соревнование состоит из двух этапов. На первом этапе участники будут искать отдельный ливень в «кирпиче», первая вершина которого известна, на втором — несколько ливней, рассредоточенных по объему «кирпича» без дополнительной информации. Победители смогут рассказать о своих решениях ученым, работающим в ЦЕРНе.


По роду своей деятельности мне достаточно часто приходится участвовать в проектах, в которых создаются высокодоступные, высокопроизводительные системы для различных рынков — реклама, финтех, сервисы классов SaaS, PaaS. В таких системах применяется вполне устоявшийся набор архитектур и компонентов, которые позволяют эффективно обеспечить соответствие продукта требованиям, например, lambda-архитектура для поточной обработки данных, масштабируемый микросервисный дизайн программного обеспечения, ориентированный на горизонтальное масштабирование, noSQL СУБД (Redis, Aerospike, Cassandra, MongoDB), брокеры сообщений (Kafka, RabbitMQ), распределенные серверы координации и обнаружения (Apache Zookeeper, Consul). Такие базовые инфраструктурные блоки чаще всего позволяют успешно решить большую часть задач и команда разработки не сталкивается с задачами разработки компонентов среднего уровня (middleware), которые, в свою очередь, будут использованы бизнес-ориентированной частью разрабатываемой системы.


Всем привет! Меня зовут Александр, я руковожу отделом Data Team в Badoo. Сегодня я расскажу вам о том, как мы выбирали оптимальный алгоритм для вычисления квантилей в нашей распределённой системе обработки событий.


