
Привет Хабр! Не так давно я имел удовольствие посетить встречу PyData Moscow на площадке Яндекса. Я не могу назвать себя python разрабочиком, но имею интересы в области аналитики и анализа данных. Посетив данное мероприятие, я узнал о существовании СУБД ClickHouse, разработанной в Яндексе и выложенной на GitHub под открытой лицензией. Колоночная SQL СУБД с отечественными корнями пробудила во мне интерес. В этой статье я поделюсь опытом установки и настройки ClickHouse, а также попыткой доступа к ней из Spring приложения с помощью Hibernate.
Apache Spark: из open source в индустрию
4 мин
Recovery Mode
Алёна Лазарева, редактор-фрилансер, специально для блога Нетологии написала обзорную статью об одном из популярных инструментов специалиста по Big Data — фреймворке Apache Spark.
Люди часто не догадываются о том, как Big Data влияет на их жизнь. Но каждый человек — источник больших данных. Специалисты по Big Data собирают и анализируют цифровые следы: лайки, комментарии, просмотры видео на Youtube, данные GPS с наших смартфонов, финансовые транзакции, поведение на сайтах и многое другое. Их не интересует каждый человек, их интересуют закономерности.

Люди часто не догадываются о том, как Big Data влияет на их жизнь. Но каждый человек — источник больших данных. Специалисты по Big Data собирают и анализируют цифровые следы: лайки, комментарии, просмотры видео на Youtube, данные GPS с наших смартфонов, финансовые транзакции, поведение на сайтах и многое другое. Их не интересует каждый человек, их интересуют закономерности.
SmartData — новая конференция по большим и умным данным от JUG.ru Group
5 мин

21 октября в Петербурге мы проводим новую конференцию по большим и умным данным SmartData 2017 Piter.
О Big Data в последнее время говорят все: от школьников до Германа Грефа. И вот тут возникает некоторый диалектический дуализм: о проблемах работы с большими данными говорят много, вот только все разговоры — это переливание из пустого в порожнее или какой-нибудь махровый маркетинговый вздор. Больше всего пугает, что люди начинают верить в то, что где-то лежит несколько петабайт «больших данных», и их можно взять и «отбольшеданнить». За советом я обратился к Виталию Худобахшову из «Одноклассников», и я придерживаюсь схожей точки зрения, судите сами:
Большие данные – это не свойства объема или времени. То, что считается «много данных» сейчас, влезет на флешку через 10 лет. То, для чего сейчас нужен Hadoop-кластер в десятки или даже сотни узлов, можно будет решить на телефоне через те же самые 10 лет. Большие данные – это прежде всего новое качество, т.е. что-то, что нельзя получить с помощью меньшего набора данных. На самом деле таких примеров не так уж много, но их количество с нарастанием объема данных и улучшением их качества непрерывно увеличивается.
Иногда большие данные настолько облегчают жизнь, что для решения конкретной проблемы отпадает необходимость использовать продвинутую технику машинного обучения. Рассмотрим пример: пользователь вводит свой пол в социальной сети неправильно, и получается, либо мы имеем неизвестный пол или какой-нибудь пол по умолчанию, что тоже плохо. Здесь кат.
Apache Cassandra + Apache Ignite — как совместить лучшее
14 мин
Apache Cassandra — это одна из популярных распределенных дисковых NoSQL баз данных с открытым исходным кодом. Она применяется в ключевых частях инфраструктуры такими гигантами как Netflix, eBay, Expedia, и снискала популярность за свою скорость, способность линейно масштабироваться на тысячи узлов и “best-in-class” репликацию между различными центрами обработки данных.
Apache Ignite — это In-Memory Computing Platform, платформа для распределенного хранения данных в оперативной памяти и распределенных вычислений по ним в реальном времени с поддержкой JCache, SQL99, ACID-транзакциями и базовой алгеброй машинного обучения.
Apache Cassandra является классическим решением в своей области. Как и в случае с любым специализированным решением, её преимущества достигнуты благодаря ряду компромиссов, значительная часть которых вызвана ограничениями дисковых хранилищ данных. Cassandra оптимизирована под максимально быструю работу с ними в ущерб остальному. Примеры компромиссов: отсутствие ACID-транзакций и поддержки SQL, невозможность произвольных транзакционных и аналитических транзакций, если под них заранее не адаптированы данные. Эти компромиссы, в свою очередь, вызывают закономерные затруднения у пользователей, приводя к некорректному использованию продукта и негативному опыту, либо вынуждая разделять данные между различными видами хранилищ, фрагментируя инфраструктуру и усложняя логику сохранения данных в приложениях.
Возможное решение проблемы — использование Cassandra в связке с Apache Ignite. Это позволит сохранить ключевые преимущества Cassandra, при этом скомпенсировав ее недостатки за счет симбиоза двух систем.
Как? Читайте дальше, и смотрите пример кода.

Apache Ignite — это In-Memory Computing Platform, платформа для распределенного хранения данных в оперативной памяти и распределенных вычислений по ним в реальном времени с поддержкой JCache, SQL99, ACID-транзакциями и базовой алгеброй машинного обучения.
Apache Cassandra является классическим решением в своей области. Как и в случае с любым специализированным решением, её преимущества достигнуты благодаря ряду компромиссов, значительная часть которых вызвана ограничениями дисковых хранилищ данных. Cassandra оптимизирована под максимально быструю работу с ними в ущерб остальному. Примеры компромиссов: отсутствие ACID-транзакций и поддержки SQL, невозможность произвольных транзакционных и аналитических транзакций, если под них заранее не адаптированы данные. Эти компромиссы, в свою очередь, вызывают закономерные затруднения у пользователей, приводя к некорректному использованию продукта и негативному опыту, либо вынуждая разделять данные между различными видами хранилищ, фрагментируя инфраструктуру и усложняя логику сохранения данных в приложениях.
Возможное решение проблемы — использование Cassandra в связке с Apache Ignite. Это позволит сохранить ключевые преимущества Cassandra, при этом скомпенсировав ее недостатки за счет симбиоза двух систем.
Как? Читайте дальше, и смотрите пример кода.
Динамическое создание кластера Apache NiFi
3 мин
Apache NiFi — удобная платформа для работы с различными данными в режиме реального времени, с возможностью визуального построения данных процессов. Целью данной статьи является описание возможностей создания кластера Apache NiFi.
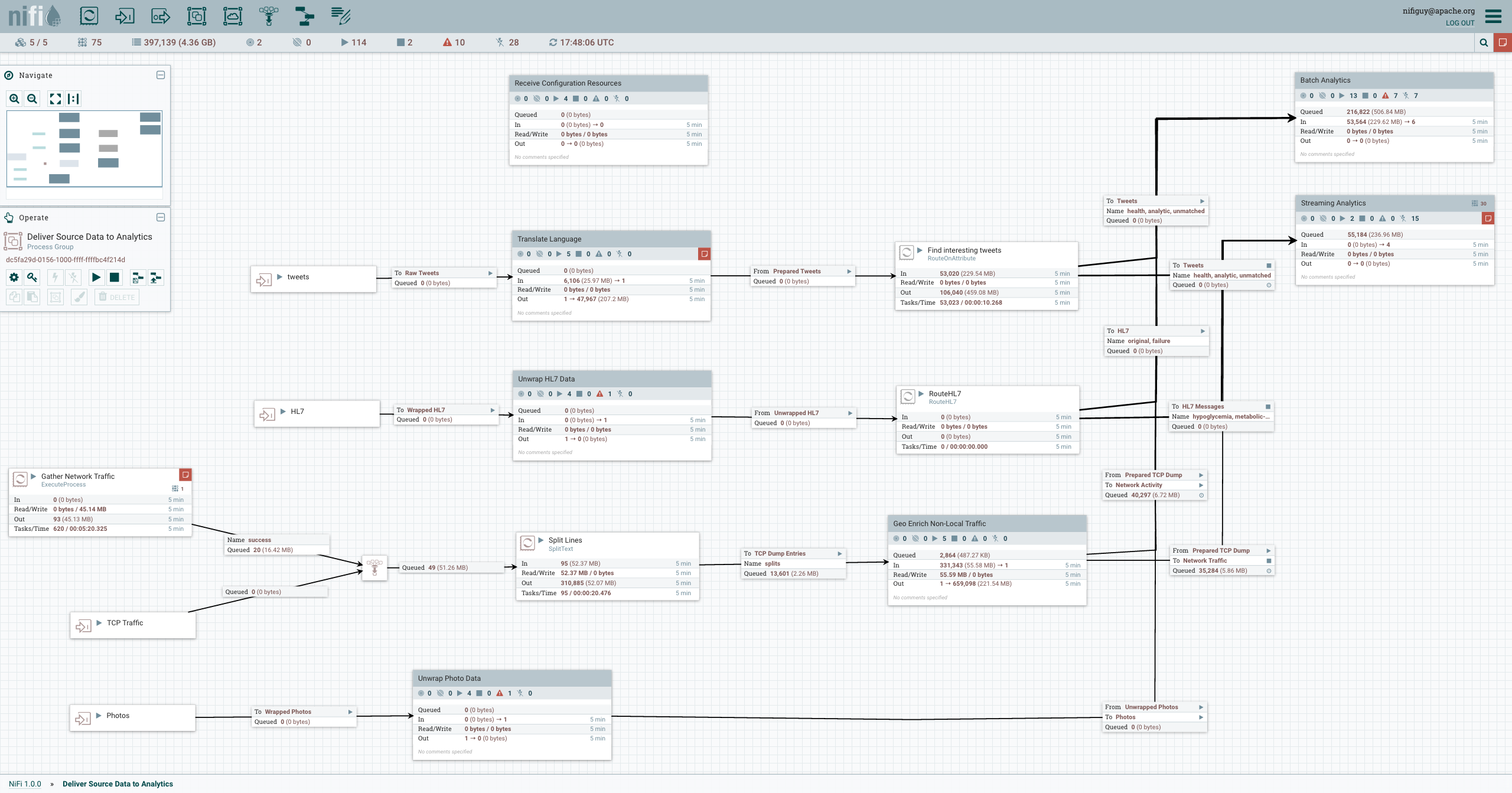 Рис. 1. GUI Apache NiFi.
Рис. 1. GUI Apache NiFi.
Особенности:
→ Подробнее тут
Рис. 1. GUI Apache NiFi.Особенности:
- Визуальное создание и управление направленными графиками процессоров.
- Асинхронный, что обеспечивает высокую пропускную способность и естественную буферизацию, даже когда скорость потока и обработки расходятся.
- Дает возможность создания связанных и слабо-связанных компонентов, которые затем могут быть повторно использованы в других контекстах.
- Удобная обработка ошибок, которая облегчает работу и поиск проблемных мест.
- Источники, по которым поступают данные, а также то, как они протекают и обрабатываются, визуально видимы и легко отслеживаются.
→ Подробнее тут
Полезные функции Google Таблиц, которых нет в Excel
8 мин
Туториал
Cтатья написана в соавторстве с Ренатом Шагабутдиновым.

В этой статье речь пойдет о нескольких очень полезных функциях Google Таблиц, которых нет в Excel (SORT, объединение массивов, FILTER, IMPORTRANGE, IMAGE, GOOGLETRANSLATE, DETECTLANGUAGE)
Очень много букв, но есть разборы интересных кейсов, все примеры, кстати, можно рассмотреть поближе в Google Документе goo.gl/cOQAd9 (файл-> создать копию, чтобы скопировать файл себе на Google Диск и иметь возможность редактирования).
В этой статье речь пойдет о нескольких очень полезных функциях Google Таблиц, которых нет в Excel (SORT, объединение массивов, FILTER, IMPORTRANGE, IMAGE, GOOGLETRANSLATE, DETECTLANGUAGE)
Очень много букв, но есть разборы интересных кейсов, все примеры, кстати, можно рассмотреть поближе в Google Документе goo.gl/cOQAd9 (файл-> создать копию, чтобы скопировать файл себе на Google Диск и иметь возможность редактирования).
Материалы студенческой школы «Recent Advances in Algorithms»
1 мин

В конце мая в Петербурге в ПОМИ РАН прошла международная студенческая школа «Recent Advances in Algorithms». Идея школы заключалась в том, чтобы ведущие учёные рассказали о последних достижениях в области алгоритмов. В результате у нас получился следующий список курсов.

Отчет с Moscow Data Science Meetup 31 мая
1 мин

31 мая Moscow Data Science Meetup собрал в нашем офисе более 200 участников. На встрече мы поговорили о градиентном бустинге, бейзлайне на ConvAI.io и разобрали кейс, получивший 7-е место из 419 команд на конкурсе Dstl Satellite Imagery Feature Detection. Предлагаем вашему вниманию видеозаписи и презентации трёх докладов, представленных на встрече.
Data Science meetup в офисе Avito 24 июня
3 мин
24 июня мы собираем специалистов по Data Science в нашем московском офисе, чтобы обменяться опытом в создании рекомендательных сервисов. На встрече мы подведём итоги проходившего на площадке Dataring.ru конкурса Avito на построение рекомендательной системы для объявлений: наградим победителей и попросим их подробнее рассказать о своих решениях. Кроме того, в программе интересные доклады от представителей Яндекс.Дзена, OZON.ru и, конечно же, Avito. Подробности под катом!
Apache Spark как ядро проекта. Часть 2. Streaming, и на что мы напоролись
3 мин
Привет коллеги. Да, не прошло и три года с первой статьи, но проектная пучина отпустила только сейчас. Хочу с вами поделиться своими соображениями и проблемами касательно Spark streaming в связке с Kafka. Возможно среди вас есть люди с успешным опытом, поэтому буду рад пообщаться в комментариях.
AgeHack — первый онлайн-хакатон по продлению жизни на платформе MLBootCamp
3 мин

Сегодня, 15 июня, стартует чемпионат на платформе ML Boot Camp, посвященный проблемам здравоохранения и долголетия человечества. Чемпионат организован нами совместно с Insilico Medicine в сотрудничестве с Республиканским центром электронного здравоохранения при Министерстве здравоохранения Республики Казахстан. О том, почему это не очень обычный для нас конкурс — под катом.
Dropout — метод решения проблемы переобучения в нейронных сетях
7 мин
Перевод

Переобучение (overfitting) — одна из проблем глубоких нейронных сетей (Deep Neural Networks, DNN), состоящая в следующем: модель хорошо объясняет только примеры из обучающей выборки, адаптируясь к обучающим примерам, вместо того чтобы учиться классифицировать примеры, не участвовавшие в обучении (теряя способность к обобщению). За последние годы было предложено множество решений проблемы переобучения, но одно из них превзошло все остальные, благодаря своей простоте и прекрасным практическим результатам; это решение — Dropout (в русскоязычных источниках — “метод прореживания”, “метод исключения” или просто “дропаут”).
Поддержка исследователей в области Deep Learning
1 мин
Хабр, нам тут пришла одна идея… В настоящий момент у нас возникло некое межсезонье между разными образовательными программами. Мы подумали, зачем нашей инфраструктуре зря простаивать, когда есть люди, которые могли бы на этой инфраструктуре что-то классное сделать.
Мы решили сделать небольшой вклад в развитие deep learning в России и выделить 3 виртуальных сервера с GPU тем, кто что-то делает в этой области. 2 виртуалки мы решили отдать нашим выпускникам, а 1 виртуалку дать в пользование кому-то «со стороны».

Мы решили сделать небольшой вклад в развитие deep learning в России и выделить 3 виртуальных сервера с GPU тем, кто что-то делает в этой области. 2 виртуалки мы решили отдать нашим выпускникам, а 1 виртуалку дать в пользование кому-то «со стороны».
Ближайшие события
ГИС и распределенные вычисления
6 мин
Всем привет! Я снова буду рассказывать о геоинформационных технологиях. Этой статьей я начинаю серию о технологиях на стыке миров классических ГИС и все еще модного направления BigData. Я расскажу о ключевых особенностях применения распределенных вычислений к работе с геоданными, а также сделаю краткий обзор существующих инструментов.
Сегодня нас окружает огромное количество неструктурированных данных, которые до недавнего времени было немыслимо обработать. Примером таких данных могут служить, например, данные метеодатчиков, используемые для точного прогноза погоды. Более структурированные, но не менее массивные датасеты – это, например, спутниковые снимки (алгоритмам обработки снимков c помощью машинного обучения даже посвящен ряд статей у сообщества OpenDataScience). Набор снимков высокого разрешения, допустим, на всю Россию занимает несколько петабайт данных. Или история правок OpenStreetMap — это терабайт xml. Или данные лазерного сканирования. Наконец, данные с огромного количество датчиков, которыми обвешано множество техники – от дронов до тракторов (да, я про IoT). Более того, в цифровую эпоху мы сами создаем данные, многие из которых содержат в себе информацию о местоположении. Мобильная связь, приложения на смартфонах, кредитные карты – все это создает наш цифровой портрет в пространстве. Множества этих портретов создают поистине монструозные наборы неструктурированных данных.
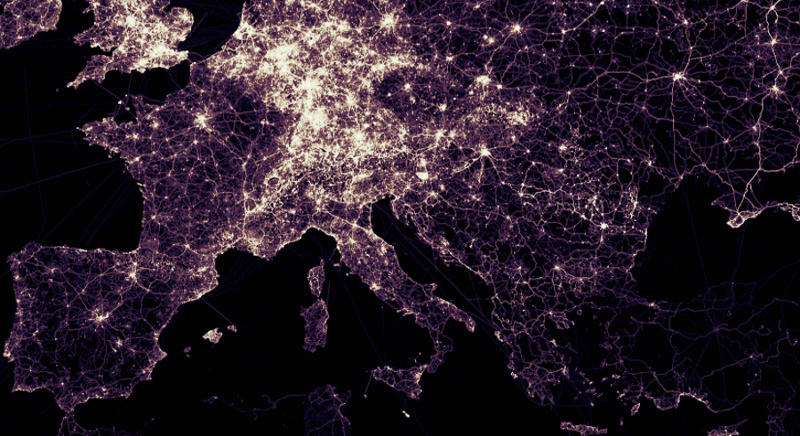
На рисунке — визуализация треков OpenStreetMap с помощью GeoWave
Где стык ГИС и распределенных вычислений? Что такое «большие геоданные»? Какие инструменты помогут нам?
Сегодня нас окружает огромное количество неструктурированных данных, которые до недавнего времени было немыслимо обработать. Примером таких данных могут служить, например, данные метеодатчиков, используемые для точного прогноза погоды. Более структурированные, но не менее массивные датасеты – это, например, спутниковые снимки (алгоритмам обработки снимков c помощью машинного обучения даже посвящен ряд статей у сообщества OpenDataScience). Набор снимков высокого разрешения, допустим, на всю Россию занимает несколько петабайт данных. Или история правок OpenStreetMap — это терабайт xml. Или данные лазерного сканирования. Наконец, данные с огромного количество датчиков, которыми обвешано множество техники – от дронов до тракторов (да, я про IoT). Более того, в цифровую эпоху мы сами создаем данные, многие из которых содержат в себе информацию о местоположении. Мобильная связь, приложения на смартфонах, кредитные карты – все это создает наш цифровой портрет в пространстве. Множества этих портретов создают поистине монструозные наборы неструктурированных данных.
На рисунке — визуализация треков OpenStreetMap с помощью GeoWave
Где стык ГИС и распределенных вычислений? Что такое «большие геоданные»? Какие инструменты помогут нам?
Диалектика нейронного машинного перевода
9 мин
или Перерастает ли количество в качество
Статья по мотивам выступления на конференции РИФ+КИБ 2017.
Про нейронные сети говорят уже давно, и, казалось бы, что одна из классических задач искусственного интеллекта – машинный перевод – просто напрашивается на то, чтобы решаться на базе этой технологии.
Тем не менее, вот динамика популярности в поиске запросов про нейронные сети вообще и про нейронный машинный перевод в частности:
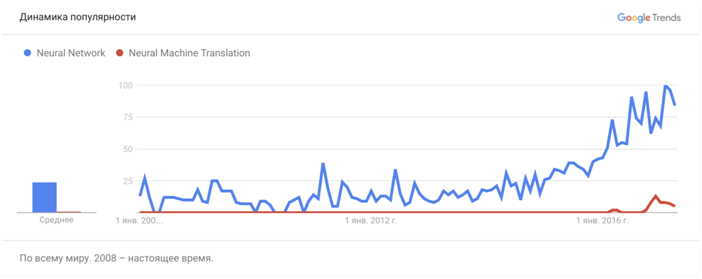
Прекрасно видно, что на радарах вплоть до недавнего времени нет ничего про нейронный машинный перевод – и вот в конце 2016 года свои новые технологии и системы машинного перевода, построенные на базе нейронных сетей, продемонстрировали сразу несколько компаний, среди которых Google, Microsoft и SYSTRAN. Они появились почти одновременно, с разницей в несколько недель или даже дней. Почему так?
Для того, чтобы ответить на этот вопрос, необходимо понять, что такое машинный перевод на базе нейронных сетей и в чем его ключевое отличие от классических статистических систем или аналитических систем, которые используются сегодня для машинного перевода.
Статья по мотивам выступления на конференции РИФ+КИБ 2017.
Neural Machine Translation: почему только сейчас?
Про нейронные сети говорят уже давно, и, казалось бы, что одна из классических задач искусственного интеллекта – машинный перевод – просто напрашивается на то, чтобы решаться на базе этой технологии.
Тем не менее, вот динамика популярности в поиске запросов про нейронные сети вообще и про нейронный машинный перевод в частности:
Прекрасно видно, что на радарах вплоть до недавнего времени нет ничего про нейронный машинный перевод – и вот в конце 2016 года свои новые технологии и системы машинного перевода, построенные на базе нейронных сетей, продемонстрировали сразу несколько компаний, среди которых Google, Microsoft и SYSTRAN. Они появились почти одновременно, с разницей в несколько недель или даже дней. Почему так?
Для того, чтобы ответить на этот вопрос, необходимо понять, что такое машинный перевод на базе нейронных сетей и в чем его ключевое отличие от классических статистических систем или аналитических систем, которые используются сегодня для машинного перевода.
Распределенные структуры данных (часть 2, как это сделано)
8 мин
В предыдущей статье — часть 1, обзорная — я рассказал о том, зачем нужны распределенные структуры данных (далее — РСД) и разобрал несколько вариантов, предлагаемых распределенным кешем Apache Ignite.
Сегодня же я хочу рассказать о подробностях реализации конкретных РСД, а также провести небольшой ликбез по распределенным кешам.
Итак:

Бесплатные билеты на In-Memory Computing Summit 2017 – Europe
1 мин
Всем привет! Возможно, вы знаете, что 20-21 июня в Амстердаме пройдет In-Memory Computing Summit 2017 – Europe. Все детали тут.

Мероприятие, ставшее уже традиционным в США, с этого года также будет ежегодно собирать экспертов из Европы и Азии на новой европейской площадке. На различных секциях конференции выступят представители компаний ING, Intel, Tata Consultancy Services, The Glue, Redis Labs, ScaleOut Software и WSO2.
У меня есть несколько бесплатных билетов, которыми я с удовольствием поделюсь с вами.
Напишите мне на почту mkuznetsov@gridgain.com или в личные сообщения на Хабре. От вас — ФИО и название компании на английском языке, адрес электронной почты и мобильный телефон.
Приезжайте, будет круто!
Мероприятие, ставшее уже традиционным в США, с этого года также будет ежегодно собирать экспертов из Европы и Азии на новой европейской площадке. На различных секциях конференции выступят представители компаний ING, Intel, Tata Consultancy Services, The Glue, Redis Labs, ScaleOut Software и WSO2.
У меня есть несколько бесплатных билетов, которыми я с удовольствием поделюсь с вами.
Напишите мне на почту mkuznetsov@gridgain.com или в личные сообщения на Хабре. От вас — ФИО и название компании на английском языке, адрес электронной почты и мобильный телефон.
Приезжайте, будет круто!
По дороге с облаками. Реляционные базы данных в новом технологическом контексте
10 мин
Привет, Хабр! Мы задумываемся об издании не совсем обычной книги, автор которой желает изложить очень интересную трактовку современного технологического ландшафта, охватывающего базы данных и технологии обработки Big Data. Автор полагает, что без активного использования облаков никуда не деться, и рассказывает об этом ландшафте именно в таком ракурсе.
Об авторе:
Александр Васильевич Сенько, кандидат физико-математических наук в области компьютерного моделирования и оптимизации мощных сверхвысокочастотных приборов.
Автор имеет сертификаты Microsoft в области создания приложений в среде Microsoft Azure: Microsoft Certified Professional и Microsoft Specialist: Developing Microsoft Azure Solutions. В 2008 году закончил Белорусский Государственный Университет Информатики и Радиоэлектроники (БГУИР) по специальности “Моделирование и компьютерное проектирование радиоэлектронных средств”. С 2007 по 2012-й годы автор работает в научно-исследовательском институте ядерных проблем БГУ на должностях техника, лаборанта, инженера. С 2013 года по настоящее время автор работает в компании ISSoft Solutions на должности разработчика ПО и DevOps с специализацией в области создания облачных приложений на базе стека Microsoft
Под катом вы сможете оценить идеи и стиль автора. Не стесняйтесь голосовать и комментировать — и добро пожаловать под кат!
Об авторе:
Александр Васильевич Сенько, кандидат физико-математических наук в области компьютерного моделирования и оптимизации мощных сверхвысокочастотных приборов.
Автор имеет сертификаты Microsoft в области создания приложений в среде Microsoft Azure: Microsoft Certified Professional и Microsoft Specialist: Developing Microsoft Azure Solutions. В 2008 году закончил Белорусский Государственный Университет Информатики и Радиоэлектроники (БГУИР) по специальности “Моделирование и компьютерное проектирование радиоэлектронных средств”. С 2007 по 2012-й годы автор работает в научно-исследовательском институте ядерных проблем БГУ на должностях техника, лаборанта, инженера. С 2013 года по настоящее время автор работает в компании ISSoft Solutions на должности разработчика ПО и DevOps с специализацией в области создания облачных приложений на базе стека Microsoft
Под катом вы сможете оценить идеи и стиль автора. Не стесняйтесь голосовать и комментировать — и добро пожаловать под кат!
Наука о нейронных сетях. Прямой эфир
2 мин
До конца года остаётся 213 дней, так что самое время начать изучать что-то новое, например, погрузиться в науку о нейронных сетях. Сегодня за один день мы познакомимся с устройством нейросетей в прямом эфире, начиная с простых архитектур и заканчивая глубоким обучением — сетями, в которых десятки и сотни слоев. Также рассмотрим сверточные сети, применяемые для распознавания изображений, и рекуррентные сети для анализа последовательностей. Причем вы сможете вместе с нами обучить нейронную сеть для решения нетривиальных задач — от распознавания рукописных цифр до узнавания котиков на фотографиях.

О чем говорят женщины? (Text mining of beauty blogs)
13 мин
В руках нашей команды из CleverDATA оказался уникальный материал – около 100 тыс. страниц англоязычных блогов, посвященных бьюти-сфере. Этот корпус к нам попал благодаря желанию одной косметической корпорации узнать законы, по которым «работает» блогосфера. Компания хотела эффективнее взаимодействовать с бьюти-блогерами – получать больший рекламный эффект, отдавая свои продукты в добрые руки лояльных авторов.

Источник
Источник