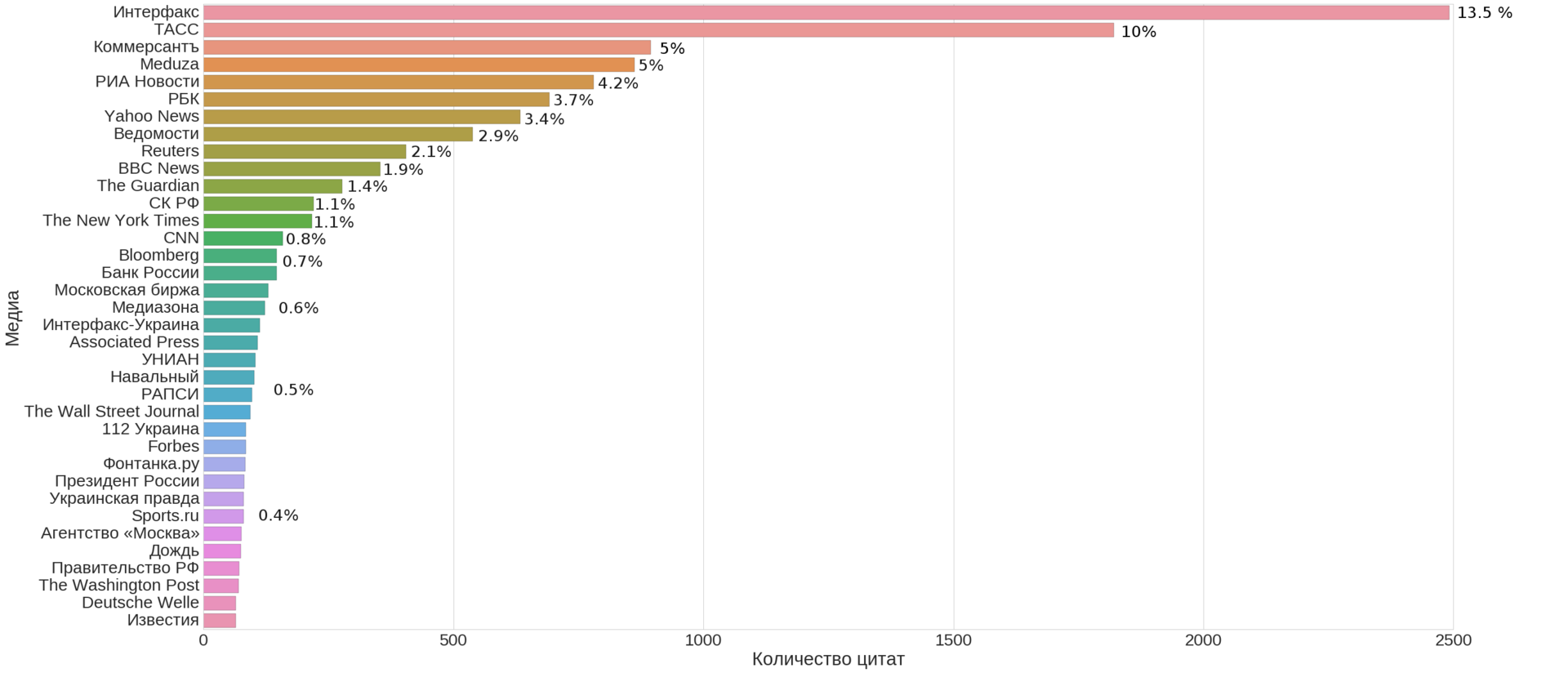
«Интернет вещей» — направление, на котором развитие идет с невероятной скоростью, где даже стратегические планы приходится пересматривать чуть ли не ежегодно. О том, чем живет передний край ИТ, как изменились подходы к найму и обучению инженеров, какие перспективы это открывает для молодых специалистов, рассказал Игорь Илюнин, лидер IoT-практики DataArt.
И. И.: Около полутора лет назад мы поняли, что в области IoT ветер начинает дуть немного в другую сторону. Раньше клиентов интересовали подключение устройств, знание конкретных протоколов обмена данными между ними, различные типы подключения к сети, построение инфраструктуры на уровне устройств. Но в этот момент к нам пришли сразу несколько заказчиков – достаточно крупных компаний, причем одним из них был производитель компьютерной техники. Эта компания собиралась строить собственный IoT-cloud, который бы обслуживал всех их клиентов, хотела обеспечить перемещение данных, самостоятельно их обрабатывать, позволив самим клиентам делать кастомизацию. То есть создать платформу на все случаи жизни. При этом они озвучили список современных технологий, которыми должны владеть инженеры их поставщика, и на тот момент во всей компании мы нашли всего пару человек, которые хотя бы частично удовлетворяли этим требованиям. Надо сказать, что и сам заказчик говорил: «нам нужна команда в 3-4 человека, которые будут работать над нашим проектом — в Кремниевой долине мы таких не нашли». Мы увидели в этом отличную возможность — тогда появился концепт внутренней Big Data академии.
 Хабр, привет! Приглашаем вас на форум Data Science Week, который проходит при поддержке DCA.
Хабр, привет! Приглашаем вас на форум Data Science Week, который проходит при поддержке DCA. 




 Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.
Spark – проект Apache, предназначенный для кластерных вычислений, представляет собой быструю и универсальную среду для обработки данных, в том числе и для машинного обучения. Spark также имеет API и для R(пакет SparkR), который входит в сам дистрибутив Spark. Но, помимо работы с данным API, имеется еще два альтернативных способа работы со Spark в R. Итого, мы имеем три различных способа взаимодействия с кластером Spark. В данном посте приводиться обзор основных возможностей каждого из способов, а также, используя один из вариантов, построим простейшую модель машинного обучения на небольшом объеме текстовых файлов (3,5 ГБ, 14 млн. строк) на кластере Spark развернутого в Azure HDInsight.