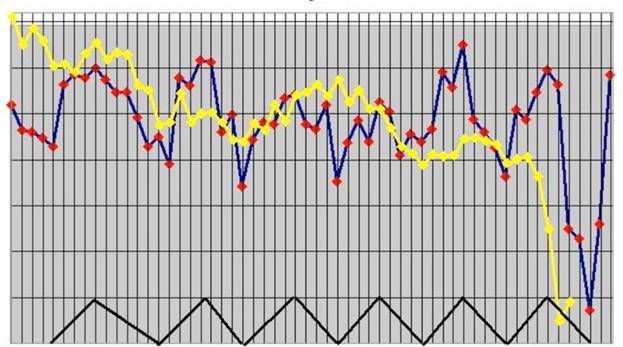
«Лучший способ избавиться от дракона — это иметь своего собственного»

На Хабре нет ни одного упоминания о Palantir`е, в русской Википедии об этом проекте нет статьи, Mithgol молчит — что-то идет не так. Или так.
А между тем Palantir стала второй крупнейшей частной компанией Кремниевой Долины с оценкой в 20 000 000 000$ (уступив Uber). Среди прочих заслуг Palantir`а — раскрытие крупных китайских разведывательных операций Ghostnet и Shadow Network.
Приходится собирать информацию о Palantir`е по крохам. И такая жирная кроха прячется в книге Питера Тиля «От нуля к единице» (хотя в этой книге множество намеков и информации между строк, так же как в легендарном курсе и его переводе на Хабре, спасибо zag2art).

Надеюсь, благодаря этой статье и комментам хабрачитателей, положение дел относительно Palantir`а станет чуточку яснее.
(Есть многомиллиардный рынок, связанный с аналитикой и ИБ, а мы ничего про него не знаем.)
На Хабре нет ни одного упоминания о Palantir`е, в русской Википедии об этом проекте нет статьи, Mithgol молчит — что-то идет не так. Или так.
А между тем Palantir стала второй крупнейшей частной компанией Кремниевой Долины с оценкой в 20 000 000 000$ (уступив Uber). Среди прочих заслуг Palantir`а — раскрытие крупных китайских разведывательных операций Ghostnet и Shadow Network.
Журналист: — В «Википедии» говорится, что вы входите в управляющий комитет Бильдербергского клуба. Правда ли это, и если да, чем вы там занимаетесь? Организуете тайное мировое господство?
Питер Тиль: — Это правда, хотя все не до такой степени тайно или секретно, чтобы я не мог вам рассказать. Суть в том, что ведется хороший диалог между разными политическими, финансовыми, медиа- и бизнес-лидерами Америки и Западной Европы. Никакого заговора нет. И это проблема нашего общества. Нет секретного плана. У наших лидеров нет секретного плана, как решить все наши проблемы. Возможно, секретные планы – это и плохо, но гораздо возмутительнее, по-моему, отсутствие плана в принципе.
Приходится собирать информацию о Palantir`е по крохам. И такая жирная кроха прячется в книге Питера Тиля «От нуля к единице» (хотя в этой книге множество намеков и информации между строк, так же как в легендарном курсе и его переводе на Хабре, спасибо zag2art).
Питер Тиль: Цель, которую я ставил перед собой, читая стэнфордский курс о стартапах и предпринимательстве, заключалась в том, чтобы донести все те знания о бизнесе, которые я приобрел за последние 15 лет в Кремниевой долине как инвестор и предприниматель, собрать их воедино. С книгой то же самое.
Надеюсь, благодаря этой статье и комментам хабрачитателей, положение дел относительно Palantir`а станет чуточку яснее.
(Есть многомиллиардный рынок, связанный с аналитикой и ИБ, а мы ничего про него не знаем.)


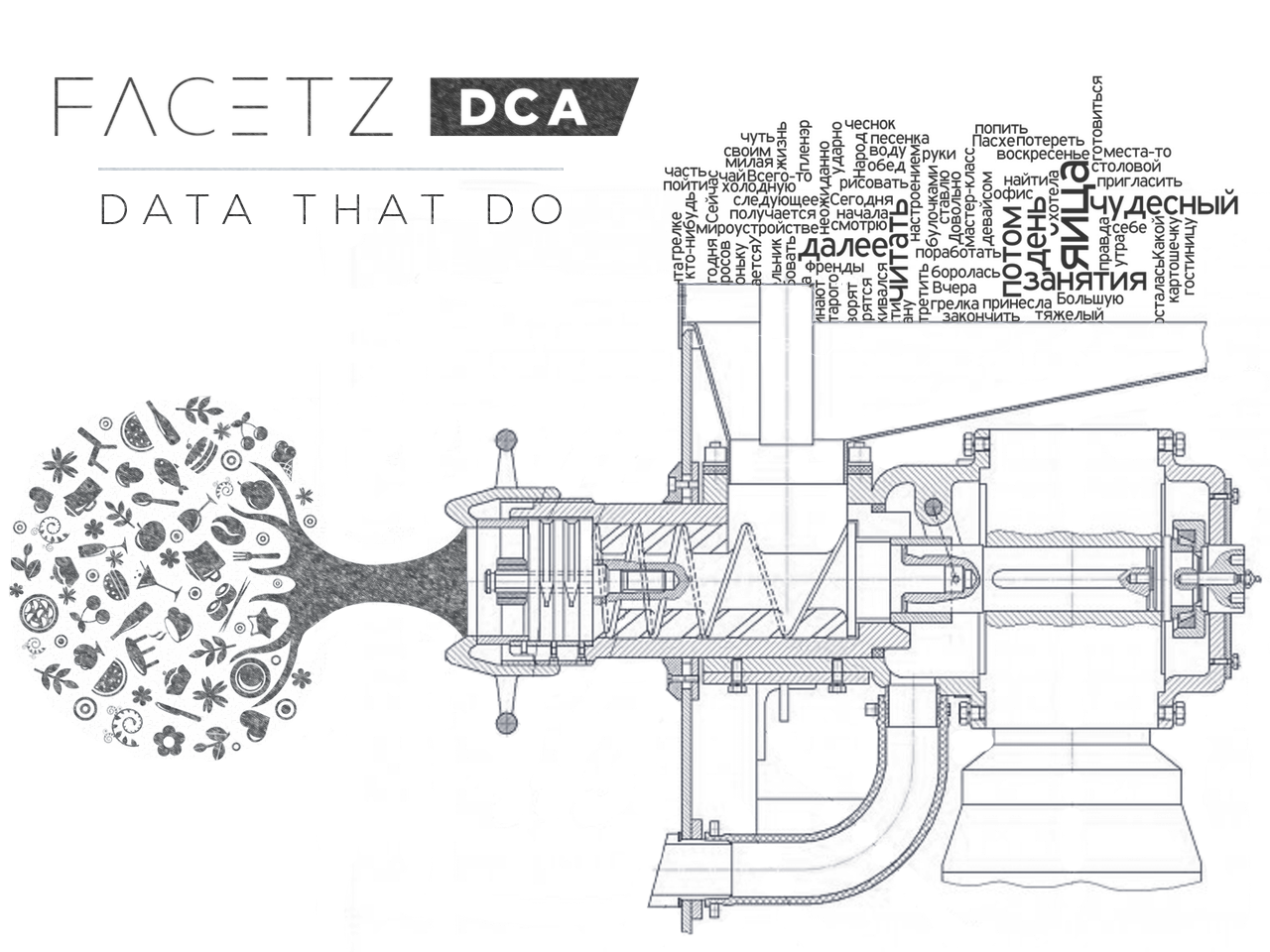


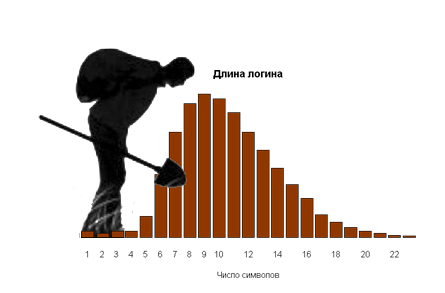
 Здравствуйте!
Здравствуйте!