Недавно Владимир Подольский vpodolskiy, аналитик в департаменте по работе с образованием IBS, закончил обучение по специализации Data Science на Coursera. Это набор из 9 курсеровских курсов от Университета Джонса Хопкинса + дипломная работа, успешное завершение которых дает право на сертификат. Для нашего блога на Хабре он написал подробный пост о своей учебе. Для удобства мы разбили его на 2 части. Добавим, что Владимир стал еще и редактором проекта по переводу специализации Data Science на русский язык, который весной запустили IBS и ABBYY LS.
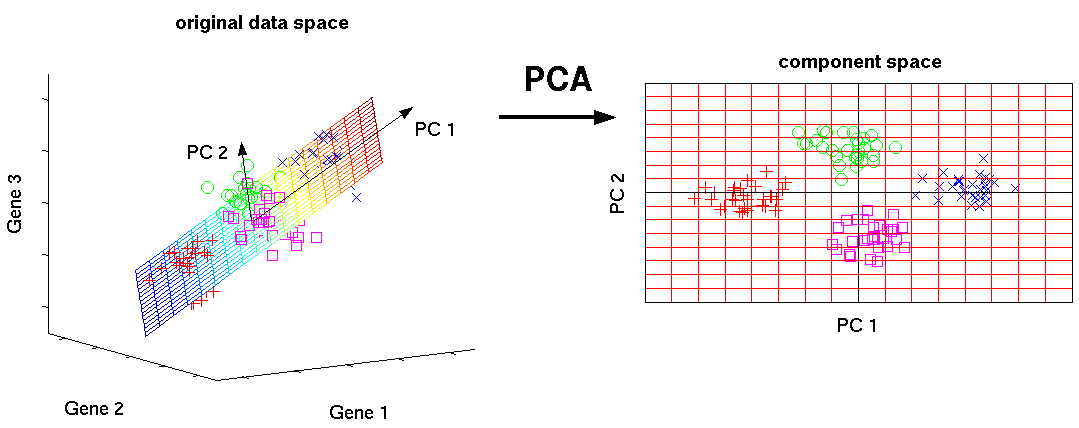
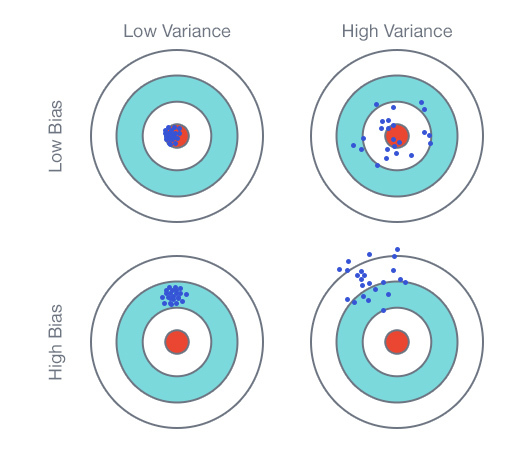
Часть 1. О специальности Data Science в общих чертах. Курсы: Инструменты анализа данных (программирование на R); Предварительная обработка данных; Документирование процесса обработки данных.
Привет, Хабр!
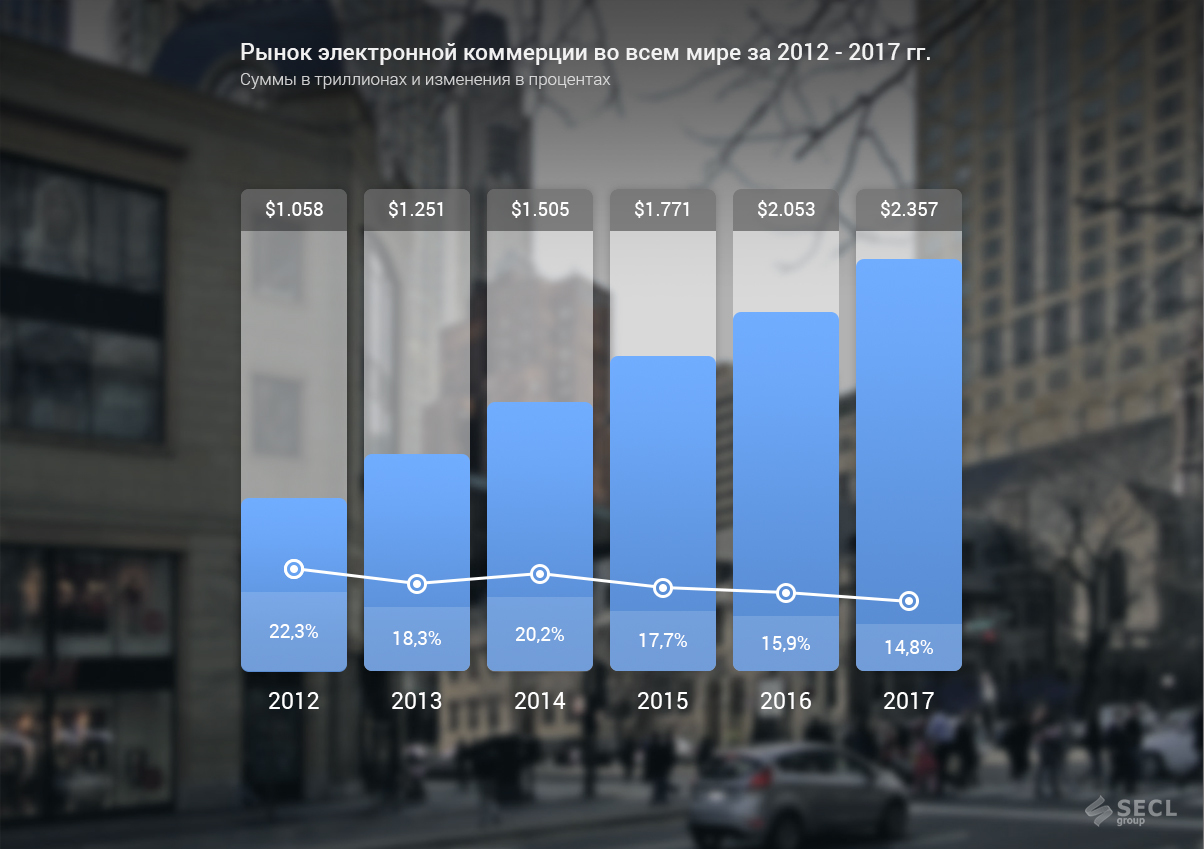
Не так давно закончился мой 7-месячный марафон по освоению специализации «Наука о данных» (Data Science) на Coursera. Организационные стороны освоения специальности очень точно описаны тут. В своём посте я поделюсь впечатлениями от контента курсов. Надеюсь, после прочтения этой заметки каждый сможет сделать для себя выводы о том, стоит ли тратить время на получение знаний по аналитике данных или нет.
 16-18 октября в рамках проекта
16-18 октября в рамках проекта