Подходы к автоматизации создания окружений для R&D-команд
Средний
12 мин
Туториал

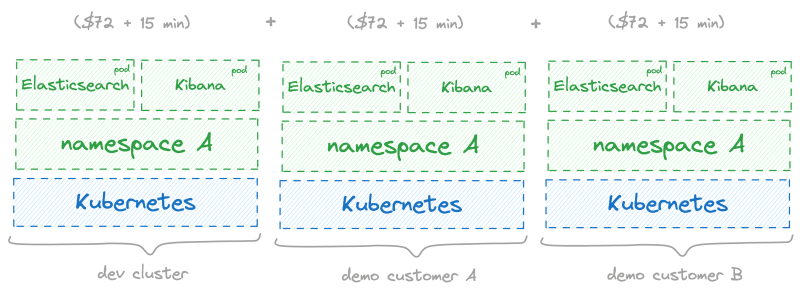
Привет! Меня зовут Михаил Кажемский, я ведущий DevOps-инженер в ИТ‑интеграторе Hilbert Team. В этой статье я расскажу о различных подходах к созданию унифицированных типовых R&D-окружений: создание динамических окружений в Kubernetes, создание статических окружений с помощью Terraform и Terragrunt и создание окружений с помощью CrossPlane и Argo CD.
Прочитав статью, вы поймёте, как разрабатывать цифровые продукты быстрее и эффективнее и избавить команды разработчиков от лишней рутины.