
Подвигло меня к написанию этого материала публикация «История языков программирования: как Fortran позволил пользователям общаться с ЭВМ на «ты».
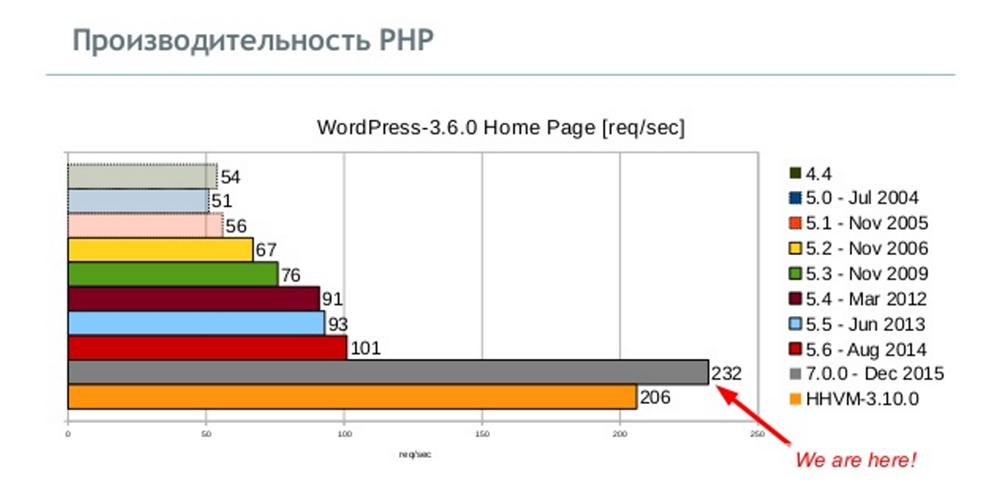
Обзор расширения OPCache для PHP
33 мин
Перевод

PHP — это скриптовый язык, который по умолчанию компилирует те файлы, которые вам нужно запустить. Во время компилирования он извлекает опкоды, исполняет их, а затем немедленно уничтожает. PHP был так разработан: когда он переходит к выполнению запроса R, то «забывает» всё, что было выполнено в ходе запроса R-1.
Очень маловероятно, что на production-серверах PHP-код изменится между выполнением нескольких запросов. Так что можно считать, что при компилированиях всегда считывается один и тот же исходный код, а значит и опкод будет точно таким же. И если извлекать его для каждого скрипта, то получается бесполезная трата времени и ресурсов.
История языков программирования: как Fortran позволил пользователям общаться с ЭВМ на «ты»
8 мин

В 2017 году языку Fortran исполняется 60 лет. За это время язык несколько раз дорабатывался. «Современными» версиями считаются Fortran 90, 95, 2003 и 2008. Если изначально это был язык программирования высокого уровня с чисто структурной парадигмой, то в более поздних версиях появились средства поддержки ООП и параллельного программирования. На сегодняшний день Fortran реализован для большинства платформ.
До появления языка Fortran разработчики программировали, используя машинный код и ассемблер. Язык высокого уровня быстро набрал популярность, так как был прост в изучении и обеспечивал генерацию эффективного исполняемого кода. Это существенно упростило жизнь программистам.
Оптимизация кода: процессор
Сложный
18 мин
Все программы должны быть правильными, но некоторые программы должны быть быстрыми. Если программа обрабатывает видео-фреймы или сетевые пакеты в реальном времени, производительность является ключевым фактором. Недостаточно использовать эффективные алгоритмы и структуры данных. Нужно писать такой код, который компилятор легко оптимизирует и транслирует в быстрый исполняемый код.
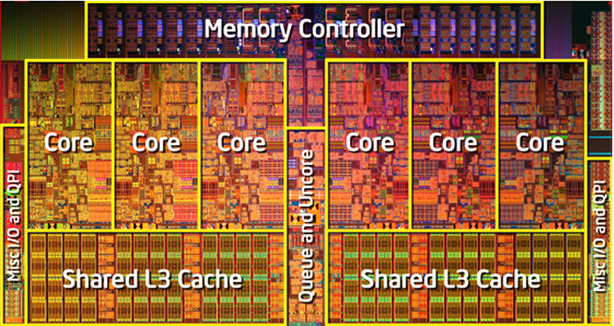
В этой статье мы рассмотрим базовые техники оптимизации кода, которые могут увеличить производительность вашей программы во много раз. Мы также коснёмся устройства процессора. Понимание как работает процессор необходимо для написания эффективных программ.
В этой статье мы рассмотрим базовые техники оптимизации кода, которые могут увеличить производительность вашей программы во много раз. Мы также коснёмся устройства процессора. Понимание как работает процессор необходимо для написания эффективных программ.
«Как я провёл это лето»: видео с летних встреч JUG.ru
2 мин
Вот и наступила осень. Кто-то возвращается в город с центнером яблок в багажнике, кто-то — c норвежским пивом прямиком с JavaZone, а мы подготовили для вас материал, который, надеемся, скоротает дождливые вечера. Мы расскажем о трёх летних встречах JUG.ru. Посему разработчики, вернувшись из отпусков, имеют замечательную возможность запастись чашкой горячего чая, завернуться в плед и посмотреть видео с наших митапов.
Итак, летом у нас было три встречи:
— Douglas Hawkins из Azul рассказал об особенностях работы JIT-компиляторов в HotSpot JVM;
— Alvaro Hernandez, разработчик ToroDB, рассказал о том, как Java работает с PostgreSQL;
— наконец, Евгений Борисов порадовал нас новой порцией загадок на тему Spring.
Итак, летом у нас было три встречи:
— Douglas Hawkins из Azul рассказал об особенностях работы JIT-компиляторов в HotSpot JVM;
— Alvaro Hernandez, разработчик ToroDB, рассказал о том, как Java работает с PostgreSQL;
— наконец, Евгений Борисов порадовал нас новой порцией загадок на тему Spring.
[СПб, Анонс] Встреча CodeFreeze с разработчиком PHP Дмитрием Стоговым про внутреннее устройство виртуальной машины PHP
1 мин
В среду, 7 сентября, в 20:00 в питерском офисе компании JetBrains состоится встреча с Дмитрием Стоговым, разработчиком компилятора PHP, сотрудником Zend Technologies. Тема встречи — внутреннее устройство виртуальной машины PHP и, в частности, последние изменения в PHP 7.
Участие, как всегда, бесплатное. Регистрация — по ссылке. Количество мест ограничено.
О докладе
Виртуальная машина PHP имеет различные внутренние изменения, однако самые интересные — поднимающие производительность от версии к версии. Именно о них расскажет Дмитрий, уделив внимание последним изменениям, реализованным в PHP 7 и принесшим двукратное улучшение, и новым идеям, реализуемым в ещё не выпущенных версиях.
Доклад будет интересен всем интересующимся разработкой интерпретируемых языков программирования.
Когда «О» большое подводит
8 мин
Перевод
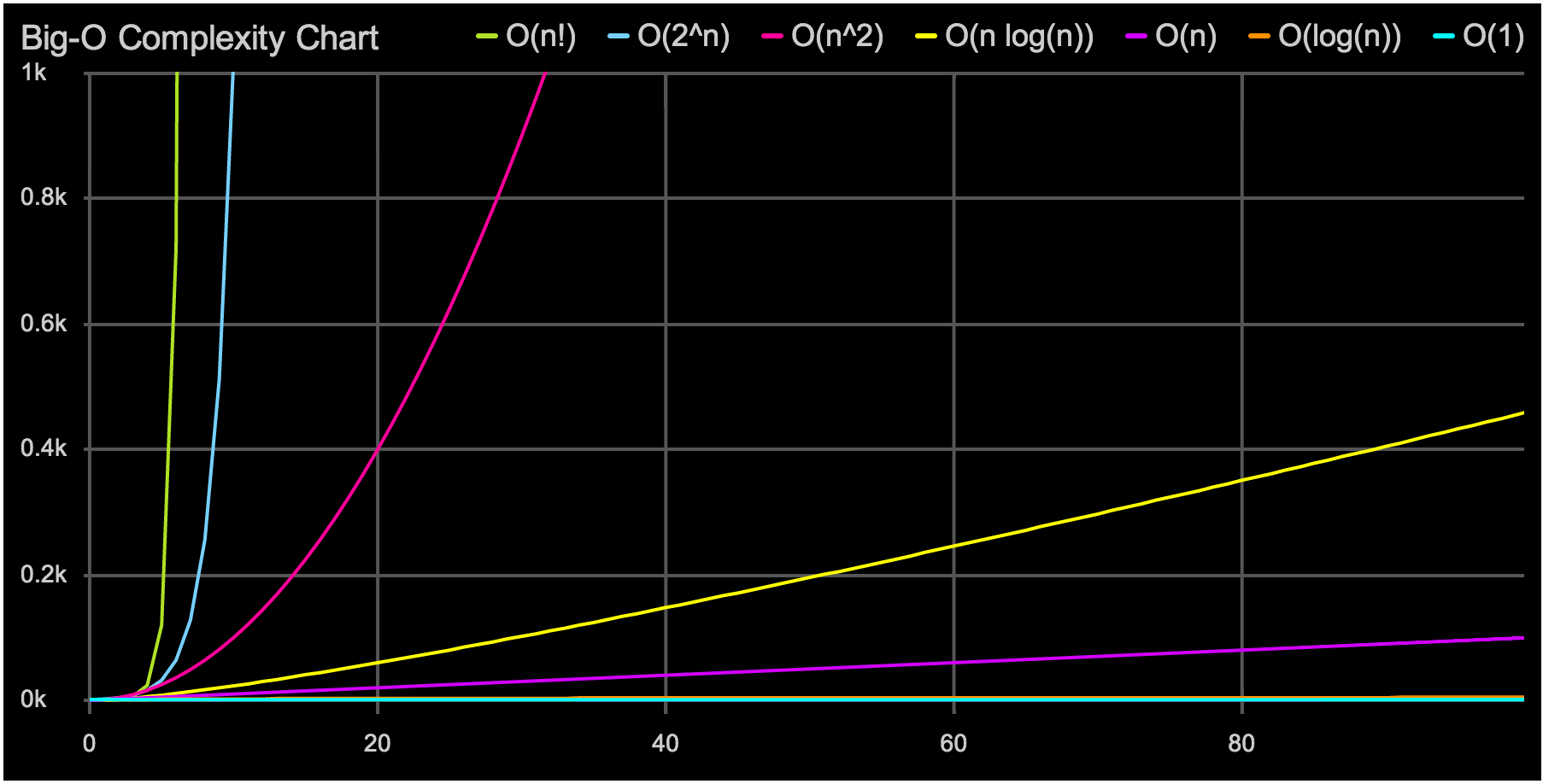
"О" большое — это отличный инструмент. Он позволяет быстро выбрать подходящую структуру данных или алгоритм. Но иногда простой анализ "О" большого может обмануть нас, если не подумать хорошенько о влиянии константных множителей. Пример, который часто встречается при программировании на современных процессорах, связан с выбором структуры данных: массив, список или дерево.
Память, медленная-медленная память
В начале 1980-х время, необходимое для получения данных из ОЗУ и время, необходимое для произведения вычислений с этими данными, были примерно одинаковым. Можно было использовать алгоритм, который случайно двигался по динамической памяти, собирая и обрабатывая данные. С тех пор процессоры стали производить вычисления в разы быстрее, от 100 до 1000 раз, чем получать данные из ОЗУ. Это значит, что пока процессор ждет данных из памяти, он простаивает сотни циклов, ничего не делая. Конечно, это было бы совсем глупо, поэтому современные процессоры содержат несколько уровней встроенного кэша. Каждый раз когда вы запрашиваете один фрагмент данных из памяти, дополнительные прилегающие фрагменты памяти будут записаны в кэш процессора. В итоге, при последовательном проходе по памяти можно получать к ней доступ почти настолько же быстро, насколько процессор может обрабатывать информацию, потому что куски памяти будут постоянно записываться в кэш L1. Если же двигаться по случайным адресам памяти, то зачастую кэш использовать не получится, и производительность может сильно пострадать. Если хотите узнать больше, то доклад Майка Актона на CppCon — это отличная отправная точка (и отлично проведенное время).
Оптимизация сравнения this с нулевым указателем в gcc 6.1
3 мин

Хорошие новостиTM ждут пользователей gcc при переходе на версию 6.1 Код такого вида (взят отсюда):
class CWindow {
HWND handle;
public:
HWND GetSafeHandle() const
{
return this == 0 ? 0 : handle;
}
};«сломается» — при вызове метода через нулевой указатель на объект теперь может происходить разыменование нулевого указателя, потому что компилятор теперь может просто взять и удалить проверку. Код, конечно, с самого начала сломан, а gcc 6.1 его только немного доломает.
Массивы в РНР 7: хэш-таблицы
22 мин
Перевод
Хэш-таблицы используются везде, в каждой серьёзной С-программе. По сути, они позволяют программисту хранить значения в «массиве», индексируя его с помощью строк, в то время как в языке С допускаются только целочисленные ключи массива. В хэш-таблице строчные ключи сначала хэшируются, а затем уменьшаются до размеров таблицы. Здесь могут возникать коллизии, поэтому нужен алгоритм их разрешения. Существует несколько подобных алгоритмов, и в РНР используется стратегия связных списков (linked list).
В Сети есть немало замечательных статей, подробно освещающих устройство хэш-таблиц и их реализации. Начать можно с http://preshing.com/. Но имейте в виду, вариантов структуры хэш-таблиц — несметное множество, и ни один из них не совершенен, в каждом есть компромиссы, несмотря на оптимизацию циклов процессора, использования памяти или хорошее масштабирование потокового окружения (threaded environment). Одни варианты лучше при добавлении данных, другие — при поиске и т. д. Выбирайте реализацию в зависимости от того, что для вас важнее.
Хэш-таблицы в РНР 5 подробно рассмотрены в материале phpinternalsbook, который я написал вместе с Nikic, автором хорошей статьи про хэш-таблицы в РНР 7. Возможно, её вы тоже сочтёте интересной. Правда, она писалась до релиза, поэтому некоторые вещи в ней слегка отличаются.
Здесь же мы подробно рассмотрим, как устроены хэш-таблицы в РНР 7, как с ними можно работать с точки зрения языка С и как ими управлять средствами РНР (используя структуры, называемые массивами). Исходный код в основном доступен в zend_hash.c. Не забывайте, что хэш-таблицы мы используем везде (обычно в роли словарей), следовательно, нужно проектировать их так, чтобы они быстро обрабатывались процессором и потребляли мало памяти. Эти структуры решающе влияют на общую производительность РНР, поскольку местные массивы не единственное место, где используются хэш-таблицы.
В Сети есть немало замечательных статей, подробно освещающих устройство хэш-таблиц и их реализации. Начать можно с http://preshing.com/. Но имейте в виду, вариантов структуры хэш-таблиц — несметное множество, и ни один из них не совершенен, в каждом есть компромиссы, несмотря на оптимизацию циклов процессора, использования памяти или хорошее масштабирование потокового окружения (threaded environment). Одни варианты лучше при добавлении данных, другие — при поиске и т. д. Выбирайте реализацию в зависимости от того, что для вас важнее.
Хэш-таблицы в РНР 5 подробно рассмотрены в материале phpinternalsbook, который я написал вместе с Nikic, автором хорошей статьи про хэш-таблицы в РНР 7. Возможно, её вы тоже сочтёте интересной. Правда, она писалась до релиза, поэтому некоторые вещи в ней слегка отличаются.
Здесь же мы подробно рассмотрим, как устроены хэш-таблицы в РНР 7, как с ними можно работать с точки зрения языка С и как ими управлять средствами РНР (используя структуры, называемые массивами). Исходный код в основном доступен в zend_hash.c. Не забывайте, что хэш-таблицы мы используем везде (обычно в роли словарей), следовательно, нужно проектировать их так, чтобы они быстро обрабатывались процессором и потребляли мало памяти. Эти структуры решающе влияют на общую производительность РНР, поскольку местные массивы не единственное место, где используются хэш-таблицы.
Не так-то просто обнулять массивы в VC++ 2015
5 мин
Перевод
 В чем разница между двумя этими определениями инициализированных локальных переменных С/С++?
В чем разница между двумя этими определениями инициализированных локальных переменных С/С++?char buffer[32] = { 0 };
char buffer[32] = {};Одно отличие состоит в том, что первое допустимо в языках С и С++, а второе — только в С++.
Что ж, давайте тогда сосредоточимся на С++. Что означают эти два определения?
Первое гласит: компилятор должен установить значение первого элемента массива в ноль и затем (грубо говоря) инициализировать нулями оставшиеся элементы массива. Второе означает, что компилятор должен инициализировать нулями весь массив.
Эти определения несколько различаются, но по факту результат один — весь массив должен быть инициализирован нулями. Поэтому согласно правилу «as-if» в С++ они одинаковы. То есть любой достаточно современный оптимизатор должен генерировать идентичный код для каждого из этих фрагментов. Верно?
Компилятор LLVM для MultiClet: бенчмарк WhetStone
7 мин
 В разговорах о мультиклеточной архитектуре ранее часто обсуждалась её применимость к той или иной задаче в контексте количества присутствующего в ней естественного параллелизма. Так, при выполнении различных бенчмарков, в частности, CoreMark, велась речь о несоответствии таких программ мультиклеточной архитектуре, ввиду достаточно жесткой последовательности алгоритма, не позволяющего клеткам внутри группы извлекать достаточное количество параллельно исполняемых в ходе работы команд. В данной статье мы оценим мультиклеты в более показательных условиях — при помощи бенчмарка WhetStone.
В разговорах о мультиклеточной архитектуре ранее часто обсуждалась её применимость к той или иной задаче в контексте количества присутствующего в ней естественного параллелизма. Так, при выполнении различных бенчмарков, в частности, CoreMark, велась речь о несоответствии таких программ мультиклеточной архитектуре, ввиду достаточно жесткой последовательности алгоритма, не позволяющего клеткам внутри группы извлекать достаточное количество параллельно исполняемых в ходе работы команд. В данной статье мы оценим мультиклеты в более показательных условиях — при помощи бенчмарка WhetStone.Const и оптимизации в C
3 мин
Перевод
Сегодня на /r/C_Programming задали вопрос о влиянии const в C на оптимизацию. Я много раз слышал варианты этого вопроса в течении последних двадцати лет. Лично я обвиняю во всём именование const.
Борьба с загадочными падениями MSBuild на XamlTaskFactory
4 мин
Наша команда разрабатывает кроссплатформенное ядро приложений, которое должно собираться на Windows под Visual Studio 2015, Linux с gcc 4.9+, MacOS, iOS, Android и Windows Phone 8.1+. Для автоматической проверки кода на Jenkins настроены сборки под все требуемые конфигурации. Задача сборок отловить код, который не собирается на одной или нескольких из платформ или не проходит юнит-тесты и не дать ему попасть к командам конечных приложений до внесения соответствующих исправлений. Такой процесс CI позволяет разработчику локально использовать удобную ему операционную систему и среду разработки, будь то Visual Studio, XCode, QtCreator или вообще vim + ninja, при этом не бояться, что его изменения не соберутся или будут валить тесты в другом окружении.
В идеальном мире красная сборка на Jenkins (именно он у нас используется в роли билдсервера) говорит о проблеме в коде. Увидев красный свет на висящем в углу комнаты мониторе, «дежурный за сборку» должен пойти и поправить найденную проблему. В реальности же причины падения билда могут быть самыми разными, например, обрыв соединения с нодой, на которой проходила компиляция, закончившееся место на диске или прилёт инопланетян. Такие ложные срабатывания отнимают лишнее время у команды, притупляют внимание и в целом снижают доверие к CI в команде. Историю борьбы с одной из таких проблем я хочу рассказать.
В идеальном мире красная сборка на Jenkins (именно он у нас используется в роли билдсервера) говорит о проблеме в коде. Увидев красный свет на висящем в углу комнаты мониторе, «дежурный за сборку» должен пойти и поправить найденную проблему. В реальности же причины падения билда могут быть самыми разными, например, обрыв соединения с нодой, на которой проходила компиляция, закончившееся место на диске или прилёт инопланетян. Такие ложные срабатывания отнимают лишнее время у команды, притупляют внимание и в целом снижают доверие к CI в команде. Историю борьбы с одной из таких проблем я хочу рассказать.
Ближайшие события
Чем меньше, тем лучше — о возможностях языков программирования
10 мин
Туториал
Перевод
Многие языки программирования включают в себя избыточные возможности. Развитие языка включает в себя работу по их исключению.
Существует много языков программирования, и новые продолжают появляться всё время. Лучше ли они тех, что уже существовали раньше? Очевидно, что на этот вопрос невозможно ответить, пока не будет дано чёткое определение что же такое «лучше» в отношении языков программирования.
Если вы посмотрите на исторические тренды, то заметите один из путей сделать лучший язык программирования — определить какую-нибудь избыточную возможность в уже существующем языке и спроектировать новый язык без неё.
Антуан де Сент-Экзюпери
В этой статье вы увидите несколько примеров возможностей различных языков программирования, которые уже общепризнанны избыточными и ещё несколько других, которые имеют те же черты и могут когда-нибудь быть отнесены к той же группе.
Существует много языков программирования, и новые продолжают появляться всё время. Лучше ли они тех, что уже существовали раньше? Очевидно, что на этот вопрос невозможно ответить, пока не будет дано чёткое определение что же такое «лучше» в отношении языков программирования.
Если вы посмотрите на исторические тренды, то заметите один из путей сделать лучший язык программирования — определить какую-нибудь избыточную возможность в уже существующем языке и спроектировать новый язык без неё.
«Совершенство достигается не тогда, когда нечего добавить, а тогда, когда нечего убрать»
Антуан де Сент-Экзюпери
В этой статье вы увидите несколько примеров возможностей различных языков программирования, которые уже общепризнанны избыточными и ещё несколько других, которые имеют те же черты и могут когда-нибудь быть отнесены к той же группе.
Троллейбус из буханки или alias analysis в LLVM
1 мин
 В преддверии очередной конференции C++ Siberia, я решил выложить на всеобщее обо
В преддверии очередной конференции C++ Siberia, я решил выложить на всеобщее обоЗачастую, знакомство с алиасингом в C++ у многих программистов начинается и заканчивается одинаково:
В докладе сделана попытка заглянуть под капот компилятора и понять, что же там, внутри? Что такое alias analysis, где он может быть полезен, в чем его преимущества и недостатки. Тема рассмотрена и со стороны программиста и со стороны разработчика компилятора. А по сему, вопрос «зачем?» был центральным.
В докладе вы найдете:
- Код Quake3 и стандарт IEEE754
- Магическую константу 0x5F3759DF
- Много ассемблера x86
- Много IR кода LLVM
- Rust, Java и даже Fortran
Инкремент в PHP
9 мин
Перевод

Возьмите переменную и увеличьте её на 1. Звучит просто, верно? Ну… С точки зрения PHP-разработчика, наверное, да. Но так ли это на самом деле? Здесь могут возникнуть некоторые трудности. Существует несколько способов инкрементировать значения, они могут выглядеть равноценными, но под капотом PHP работают по-разному, что может привести к, так сказать, интересным результатам.
C--. Первое знакомство
4 мин
 Процесс портирования и создания средств разработки программ для KolibriOS продолжается. По наиболее активно используемым языкам программирования мы публикуем статьи. Сегодня мы начинаем рассказывать о языке С--, вокруг которого сложилось активное сообщество в 2000-е годы. Подробности под катом.
Процесс портирования и создания средств разработки программ для KolibriOS продолжается. По наиболее активно используемым языкам программирования мы публикуем статьи. Сегодня мы начинаем рассказывать о языке С--, вокруг которого сложилось активное сообщество в 2000-е годы. Подробности под катом.
JIT-компилятор оптимизирует не круто, а очень круто
6 мин
Недавно Лукас Эдер заинтересовался в своём блоге, способен ли JIT-компилятор Java оптимизировать такой код, чтобы убрать ненужный обход списка из одного элемента:
// ... а тут мы "знаем", что список содержит только одно значение
for (Object object : Collections.singletonList("abc")) {
doSomethingWith(object);
}Вот мой ответ: JIT может даже больше. Мы будем говорить про HotSpot JVM 64 bit восьмой версии. Давайте рассмотрим вот такой простой метод, который считает суммарную длину строк из переданного списка:
static int testIterator(List<String> list) {
int sum = 0;
for (String s : list) {
sum += s.length();
}
return sum;
}Последние новости о развитии C++
7 мин
Недавно в финском городе Оулу завершилась встреча международной рабочей группы WG21 по стандартизации C++, в которой впервые официально участвовали сотрудники Яндекса. На ней утвердили черновой вариант C++17 со множеством новых классов, методов и полезных нововведений языка.

Во время поездки мы обедали с Бьярне Строуструпом, катались в лифте с Гербом Саттером, жали руку Беману Дейвсу, выходили «подышать воздухом» с Винцентом Боте, обсуждали онлайн-игры с Гором Нишановым, были на приёме в мэрии Оулу и общались с мэром. А ещё мы вместе со всеми с 8:30 до 17:30 работали над новым стандартом C++, зачастую собираясь в 20:00, чтобы ещё четыре часика поработать и успеть добавить пару хороших вещей.
Теперь мы готовы поделиться с вами «вкусностями» нового стандарта. Всех желающих поглядеть на многопоточные алгоритмы, новые контейнеры, необычные возможности старых контейнеров, «синтаксический сахар» нового чудесного C++, прошу под кат.
Во время поездки мы обедали с Бьярне Строуструпом, катались в лифте с Гербом Саттером, жали руку Беману Дейвсу, выходили «подышать воздухом» с Винцентом Боте, обсуждали онлайн-игры с Гором Нишановым, были на приёме в мэрии Оулу и общались с мэром. А ещё мы вместе со всеми с 8:30 до 17:30 работали над новым стандартом C++, зачастую собираясь в 20:00, чтобы ещё четыре часика поработать и успеть добавить пару хороших вещей.
Теперь мы готовы поделиться с вами «вкусностями» нового стандарта. Всех желающих поглядеть на многопоточные алгоритмы, новые контейнеры, необычные возможности старых контейнеров, «синтаксический сахар» нового чудесного C++, прошу под кат.
Введение в компиляторы, интерпретаторы и JIT’ы
13 мин
Перевод
С рождением PHP 7 не прекращаются споры об абстрактных синтаксических деревьях, just-in-time компиляторах, статическом анализе и т. д. Но что означают все эти термины? Это какие-то волшебные свойства, делающие PHP гораздо производительнее? И если да, то как это всё работает? В этой статье мы рассмотрим основы работы языков программирования и разъясним для себя процесс, который должен выполняться до того, как компьютер запустит, например, ваш PHP-скрипт.