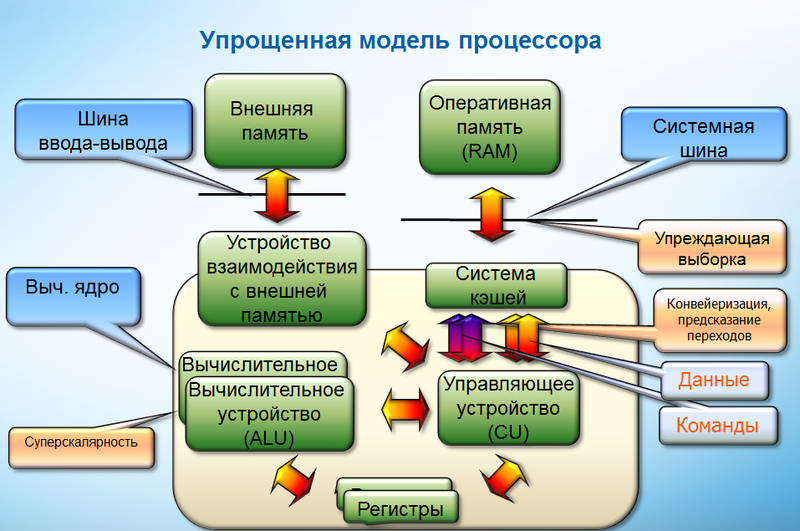
В предыдущем топике я обещал подробнее описать особенности программирования промышленных PLC, и почему такое программирование все больше напоминает разработку обычного софта. О языке IEC61131-3 ST (промышленном диалекте Паскаля) я уже писал, также хорошим вступлением можно считать вот этот хабратопик. Этот пост — о компиляторах PLC, средах разработки, особенностях программирования и эволюции языка и экосистемы.
В предыдущем топике я обещал подробнее описать особенности программирования промышленных PLC, и почему такое программирование все больше напоминает разработку обычного софта. О языке IEC61131-3 ST (промышленном диалекте Паскаля) я уже писал, также хорошим вступлением можно считать вот этот хабратопик. Этот пост — о компиляторах PLC, средах разработки, особенностях программирования и эволюции языка и экосистемы. Angry Birds на PLC?
4 мин
В предыдущем топике я обещал подробнее описать особенности программирования промышленных PLC, и почему такое программирование все больше напоминает разработку обычного софта. О языке IEC61131-3 ST (промышленном диалекте Паскаля) я уже писал, также хорошим вступлением можно считать вот этот хабратопик. Этот пост — о компиляторах PLC, средах разработки, особенностях программирования и эволюции языка и экосистемы.  С выпуском
С выпуском 
 Времена, когда программисты пытались выжать максимум из размера своего приложения, безвозвратно ушли. Основной причиной является существенное увеличение объемов оперативной памяти и дискового пространства на современных компьютерах. Немногие помнят, как при загрузке приложения с кассеты можно было пойти покушать. Или как можно было считать моргания дисковода, косвенно определяя размер приложения. Пожалуй, только разработчики програмного обеспечения под встраиваемые системы до сих пор заботятся о размере кода и потребляемой памяти. Могут ли таблетки и смартфоны вернуть разработчиков «назад в будущее»?
Времена, когда программисты пытались выжать максимум из размера своего приложения, безвозвратно ушли. Основной причиной является существенное увеличение объемов оперативной памяти и дискового пространства на современных компьютерах. Немногие помнят, как при загрузке приложения с кассеты можно было пойти покушать. Или как можно было считать моргания дисковода, косвенно определяя размер приложения. Пожалуй, только разработчики програмного обеспечения под встраиваемые системы до сих пор заботятся о размере кода и потребляемой памяти. Могут ли таблетки и смартфоны вернуть разработчиков «назад в будущее»? Один мой друг, историк по профессии, подкинул мне замечательную идею об использовании древней мнемонической и счетной систем в современной криптографии. В процессе его рассказов об узелковой письменности
Один мой друг, историк по профессии, подкинул мне замечательную идею об использовании древней мнемонической и счетной систем в современной криптографии. В процессе его рассказов об узелковой письменности