Я только что закончил серию изменений в коде браузера Chrome, которая уменьшила размер его бинарника под Windows примерно на 1 мегабайт, перенесла около 500 КB из read/write сегмента в read-only, а также уменьшила потребление оперативной памяти в общем примерно на 200 KB на каждый процесс Chrome. Удивительное заключается в том, что конкретно данная серия изменений состояла исключительно из удаления и добавления ключевого слова const в некоторых местах кода. Да, компиляторы — странные.
Эта задача возникла, когда я
писал документацию для некоторых утилит, которые я использую для исследования регрессий кода, связанных с увеличением размера скомпилированных бинарников под Windows. Я запустил утилиту, скопировал в документацию её вывод и начал его описывать, когда заметил нечто странное: несколько больших глобальных объектов, которые согласно архитектуре должны были быть константными, почему-то находились в сегменте read/write данных. Сокращённая версия того вывода утилиты показана ниже:
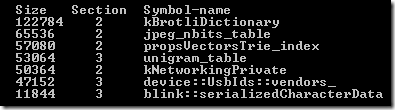
Большинство исполняемых форматов имеют как минимум два сегмента данных — один для read/write объектов и ещё один для read-only. Если у вас есть константные данные, такие, например, как
kBrotliDictionary, то их будет логично поместить в read-only сегмент, который является сегментом «2» в бинарнике Chrome под Windows. Однако некоторые константные данные, такие как
unigram_table,
device::UsbIds::vendors_ и
blink::serializedCharacterData были в секции «3», то есть в read/write сегменте.






 Привет, Хабр!
Привет, Хабр! 

