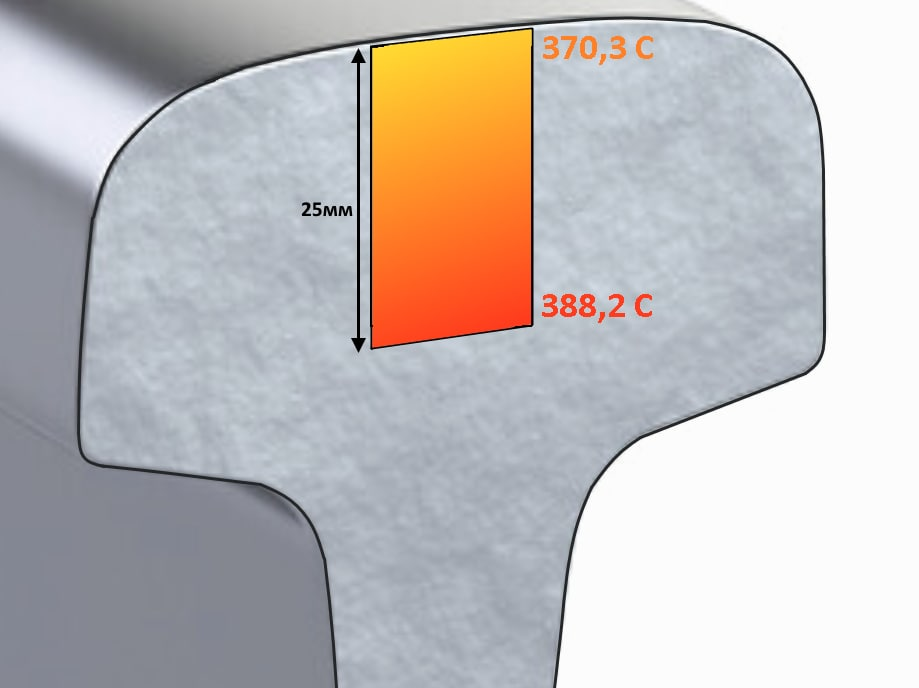
Скажите, если к вам придёт потенциальный клиент, но вместо красивого сайта, приложения или сотрудника его встретит чатик с текстовой нейросетью, которая что-то знает о вашем продукте и теоретически может его продать – вам будет комфортно? Это, может, нетипично для энтузиаста, закопавшегося по уши во всякие GPT и PaLM, но лично мне в такой ситуации будет очень страшно. А вдруг нейросеть продаст что-то несуществующее? Или вообще ничего не будет продавать? Или нагрубит клиенту?
Похоже что эти опасения разделяют многие: каждую неделю появляется ворох новых сервисов, пишущих нейросетью что-то для последующей обработки человеком (начиная с кода и заканчивая рекламными текстами), а вот примеров, в которых нейросеть "пускают" напрямую к клиентам далеко не так много. Но, как мне кажется, я нашёл способ от этих опасений в существенной степени избавиться. (Конечно, может быть, кто-то уже нашёл его раньше и я просто этого не заметил, но что уж поделаешь, сфера новая и очень быстро развивается.)
В этой статье я на примере простого сервиса для маршрутизации заявок в техподдержку покажу свой подход к созданию сервисов на нейросетях, которые не страшно напрямую использовать для общения с клиентами или в других важных процессах. А также приблизительно измерю процент случаев, в которых такой сервис сможет корректно отработать, и постараюсь отследить влияние различных особенностей запросов к нейросети на этот процент.