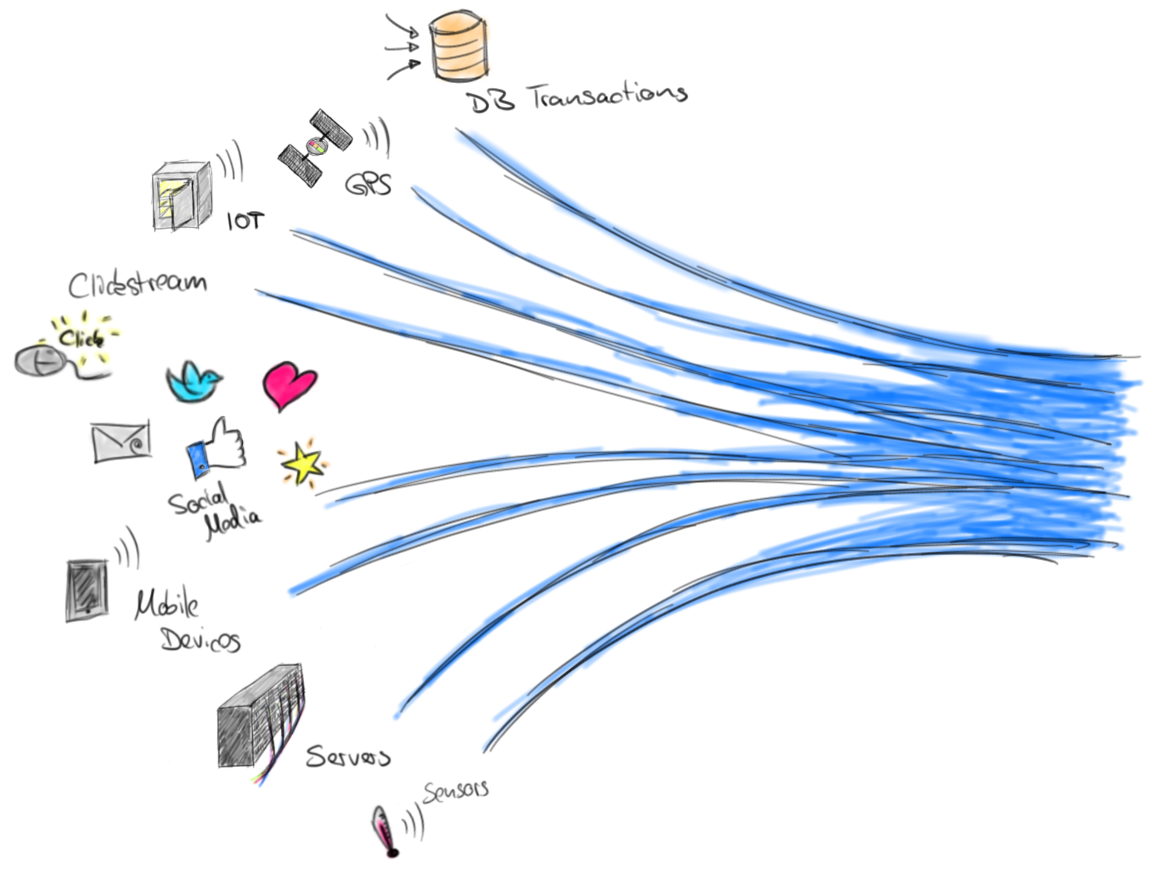
Data Cleaning: Problems and Current Approaches, 2000 г.
Достаточно часто каждый аналитик сталкивается с ситуацией, когда загрузил данные в блок анализа, а в ответ – тишина, хотя в тестовом режиме все работает. Причина обычно в том, что данные недостаточно очищены, где в этой ситуации искать аналитику засаду и с чего начинать обычно задачка не из легких. Можно конечно использовать механизмы сглаживания, но каждый знает, что если из черного ящика с красными и зелеными шарами отсыпать килограмм шаров и вместо них вбросить килограмм белых, то в понимании распределения красных и зеленых это мало приблизит.
Когда находишься в ситуации «а с чего начать» помогает таксономия «грязных данных». Хотя в учебниках и дают список проблем, но он обычно неполный, вот постоянно искал исследования, которые рассматривают эту тему подробней. Попалась работа T.Gschwandtner, J.Gartner, W.Aigner, S.Miksch хотя они ее делали для рассмотрения способов очистки данных связанных с датами и временем но, на мой взгляд, это оказалось исключение, которое потребовало разобраться с правилами поглубже чем в учебниках. По собственному опыту знаю, что сопряжение дат и времени «вынос мозга» практически в прямом смысле и поэтому и зацепился за исследование этих авторов.
В своей работе они проанализировали несколько работ других авторов и составили мощный список «загрязнений данных» логика их анализа заслуживает уважения и, с другой стороны, дает возможность более «со стороны» посмотреть на любую задачу очистки данных. Все это видно когда сопоставляешь всю совокупность работ, по которым они делают сравнительный анализ. Поэтому и сделал перевод самых используемых ими 5 статей, список с ссылками на эти переводы ниже.
Это вторая статья из цикла
1. Таксономия форматов времени и дат в неочищенных данных, 2012 г.
2. Очистка данных: проблемы и современные подходы 2000 г.
3. Таксономия «грязных данных» 2003 г.
4. Проблемы, методы и вызовы комплексной очистки данных 2003 г.
5. Формульное определение проблем качества данных 2005 г.
6. Обзор инструментов качества данных 2005 г.