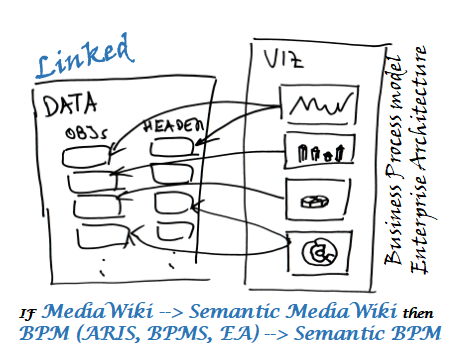
Онтологический инжиниринг в области Управления бизнес-процессами (BPM). Семантический BPM (Business Process Management), впрочем, как и семантический ЕА (Enterprise Architecture), – это заимствование концепций (подходов к описанию и онтологизации) \ инструментов Linked Data к указанным направлениям (формализация процессов и архитектур предприятий).
«Красная нить»: когда мы формализуем процессы - мы говорим об одном и том же, но на разных языках (нотациях), поэтому стандартизация Языка семантики, онтологических концептов BPM (EA) – важная, но еще недостаточно популяризированная составляющая развития BPM (следующий этап, ВРМ 3.0). Отделение («мух от котлет») семантики от синтаксиса позволит «рафинировать» понятийный (смысловой) анализ бизнес-процессов и при их аналитике оперировать базовыми (семантическими) концептами (образами).
В Semantic BPM, как и в Semantic Web (семантическая паутина), смысл представленного процесса \ архитектуры понятен не только человеку, но и машинам и они могут его читать и обрабатывать. Эти смыслы, обычно передаваемые «человек – человек» на языке синтаксиса / графической грамматики через нотации VAD, EPC, BPMN, UML (плюс еще несколько десятков подобных вариантов \ форматов «обертывания», включая Дракон), исходно формализуются на языке семантики (стек Linked Data или аналогичный) и уже потом упаковываются в схемы с конкретной нотацией («пишутся» на языке какой-либо нотации). Для единого понимания смысловой составляющей схем применяется общая ВРМ-онтология, толковый словарь ВРМ.