На наших предприятиях множество данных — от постоянно обновляющихся цен и технологических условий до логистических отчетов, графиков доставки и многое, много другое. Не говоря уже о чисто внутренней информации.
При должной сноровке все эти данные можно использовать с пользой, а не просто собирать где-то ради пары годовых отчётов. Но тут есть проблема.
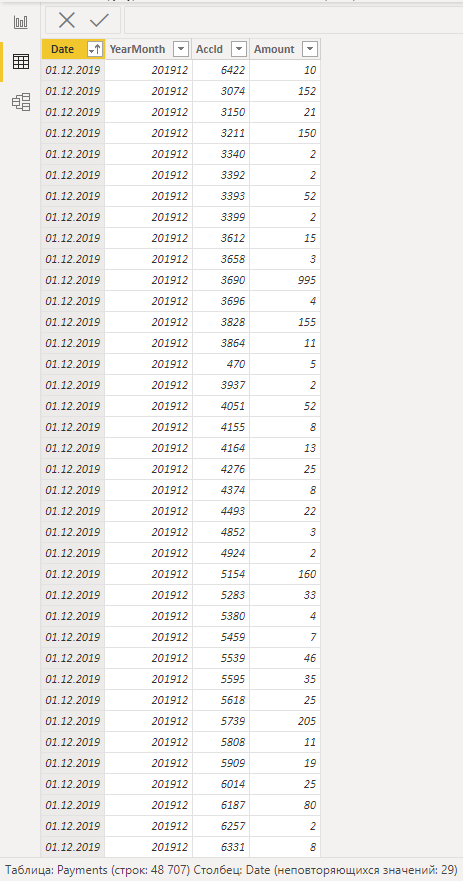
Данные разные, как и их источники. Где-то речь идет об огромных монструозных таблицах в Excel с кучей переменных и подвязок, где-то используются внутренние CRM, в общем, тут кто во что горазд и кому где удобнее работать. То есть информация вроде есть, ее много, на ее основе можно делать выводы и принимать решения, но вот наглядности — никакой.
И тут мы переходим к решению, так что самое время представиться. Меня зовут Марина Коробейникова, я отвечаю за дашборды в закупках и производстве СИБУРа. Именно дашборды помогают нам вырваться из описанного выше порочного круга, предоставляя возможность просто посмотреть на экран и понять, что вообще сейчас происходит. Ну то есть, в компании.
В СИБУРе дашборды применяются для самых разных департаментов – логистики, продаж, закупок, маркетинга, топ-менеджмента, и тд. И о каждом из этих направлений мы расскажем подробнее.
Но начнём, пожалуй, с закупок и производства.