Визуализация зависимостей и наследований между моделями машинного обучения
3 мин
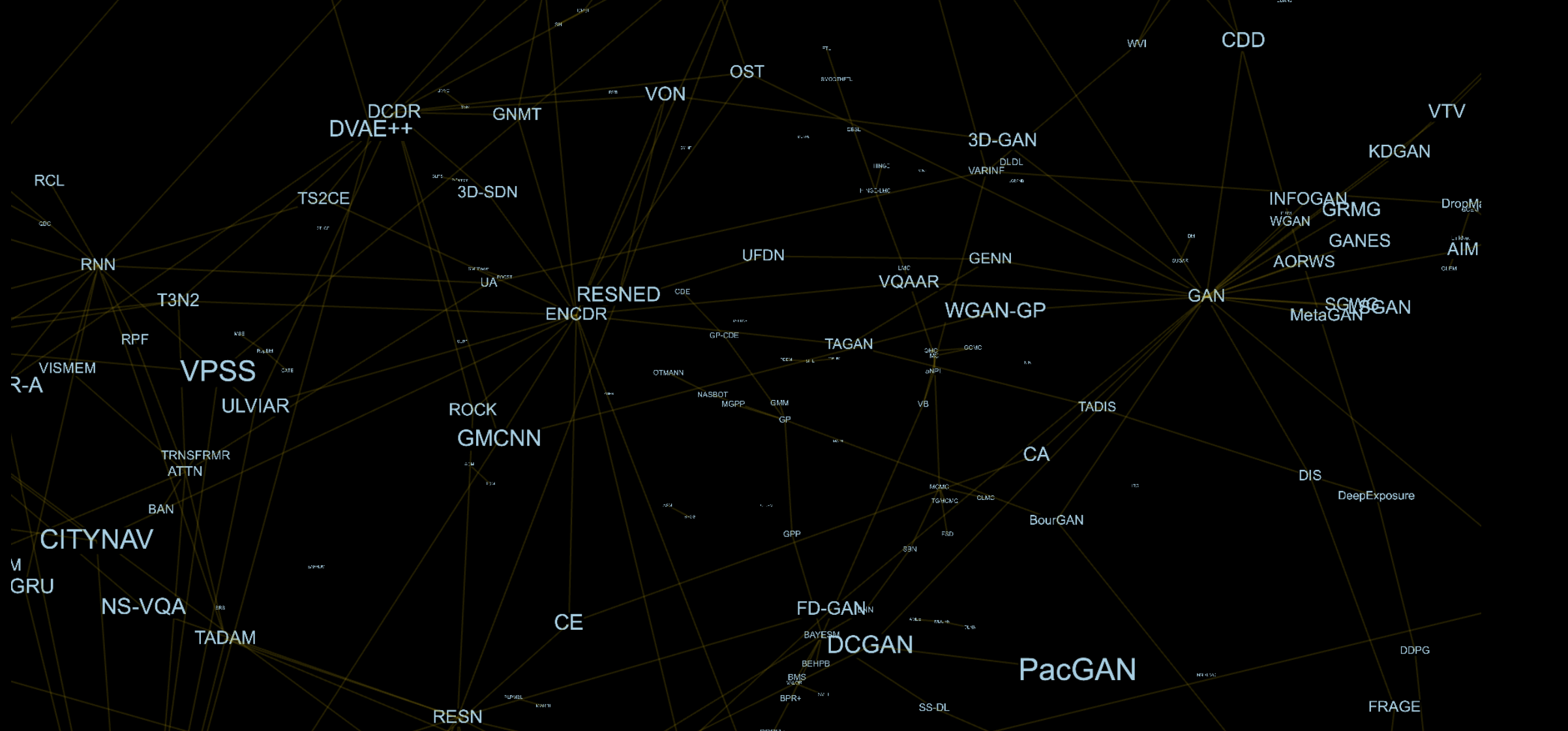
Несколько месяцев назад я столкнулся с проблемой, моя модель построенная на алгоритмах машинного обучения просто на просто не работала. Я долго думал над тем, как решить эту проблему и в какой-то момент осознал что мои знания очень ограничены, а идеи скудны. Я знаю пару десятков моделей, и это очень малая часть тех работ которые могут быть очень полезны.
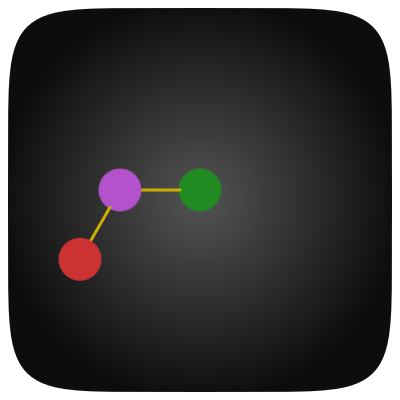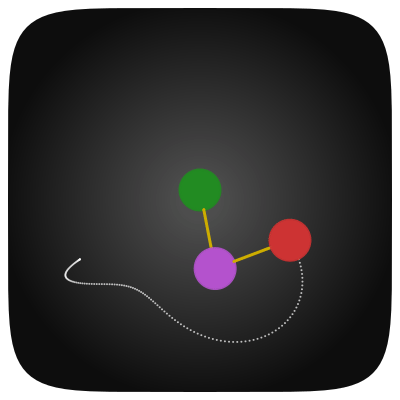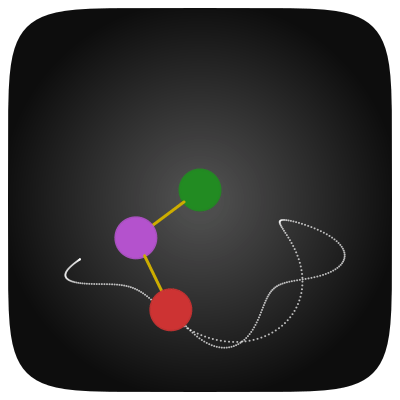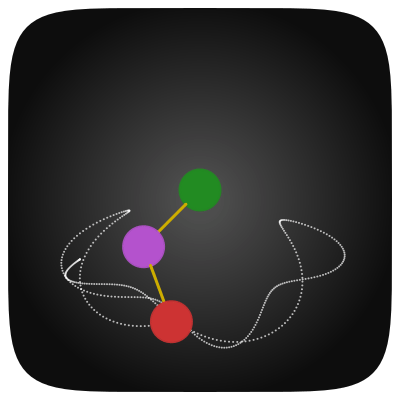
Первая мысль которая пришла в голову это то что, если я буду знать и пойму больше моделей, мои качества как исследователя и инженера в целом, возрастут. Эта идея подтолкнула меня к изучению статей с последних конференций по машинному обучению. Структурировать такую информацию довольно сложно, и необходимо записывать зависимости и связи между методами. Я не хотел представлять зависимости в виде таблицы или списка, а хотелось что-то более естественное. В итоге, я понял что иметь для себя трехмерный граф с ребрами между моделями и их компонентами, выглядит довольно интересно.
Например, архитектурно GAN [1] состоит из генератора (GEN) и дискриминатора (DIS), Состязательный Автокодировщик (AAE) [2] состоит из Автокодировщика (AE) [3] и DIS,. Каждый компонент является отдельной вершиной в данном графе, поэтому для AAE у нас будет ребро с AE и DIS.
Шаг за шагом, я анализировал статьи, выписывал из каких методов они состоят, в какой предметной области они применяются, на каких данных они тестировались, и так далее. В процессе работы я понял сколько очень интересных решений остаются неизвестными, и не находят своего применения.