
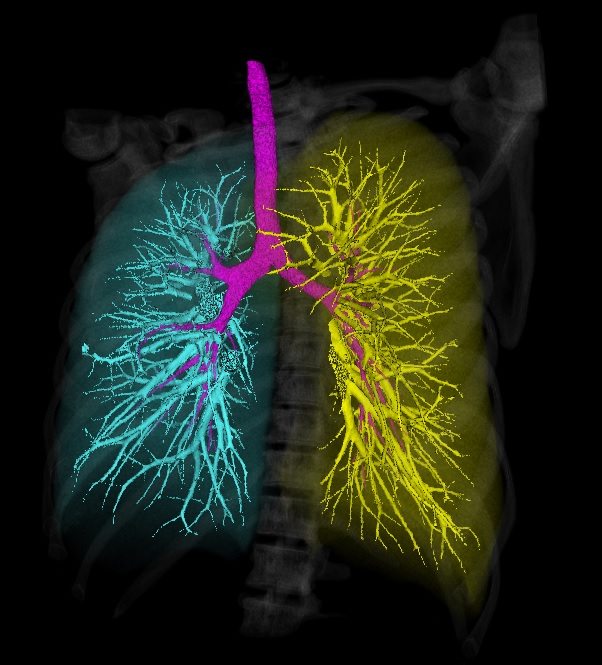
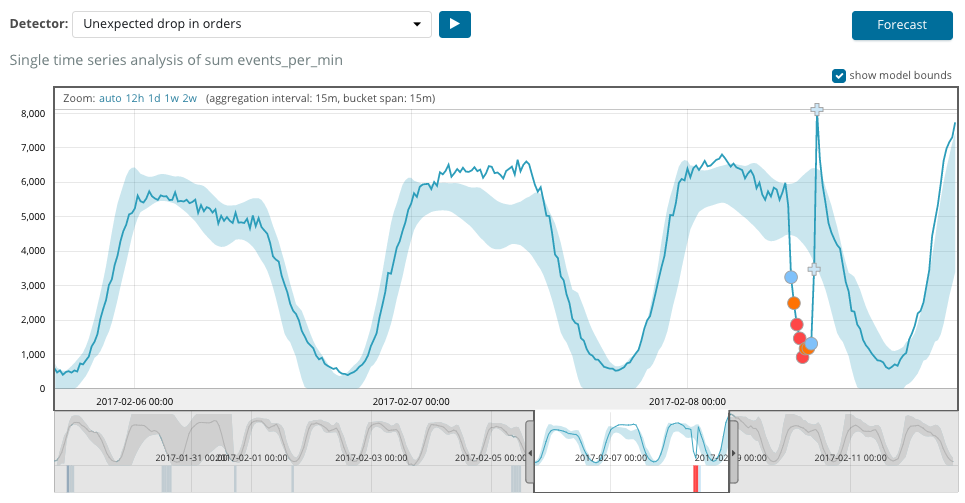
Автоматическая сегментация дыхательных органов
Ручная сегментация легких занимает около 10 минут и требуется определенная сноровка, чтобы получить такой же качественный результат, как при автоматической сегментации. Автоматическая сегментация занимает около 15 секунд.
Я предполагал, что без нейронной сети удастся получить точность не выше 70%. Также я предполагал, что морфологические операции – это только подготовка изображения к более сложным алгоритмам. Но в результате обработки тех, хоть и немногочисленных 40 образцов томографических данных, что есть на руках, алгоритм выделил легкие без ошибок, причём после теста на первых пяти случаях алгоритм уже не претерпевал значительных изменений и с первого применения правильно отработал на остальных 35 исследованиях без изменения настроек.
Также нейронные сети имеют минус – для их обучения нужны сотни обучающих образцов лёгких, которые придётся размечать вручную.











{kind=link}