Прорабатываем навык использования группировки и визуализации данных в Python
5 мин
Привет, Хабр!
Сегодня будем прорабатывать навык использования средств группирования и визуализации данных в Python. В предоставленном датасете на Github проанализируем несколько характеристик и построим набор визуализаций.
По традиции, в начале, определим цели:
- Сгруппировать данные по полу и году и визуализировать общую динамику рождаемости обоих полов;
- Найти самые популярные имена за всю историю;
- Разбить весь временной промежуток в данных на 10 частей и для каждой найти самое популярное имя каждого пола. Для каждого найденного имени визуализировать его динамику за все время;
- Для каждого года рассчитать сколько имен покрывает 50% людей и визуализировать (мы увидим разнообразие имен за каждый год);
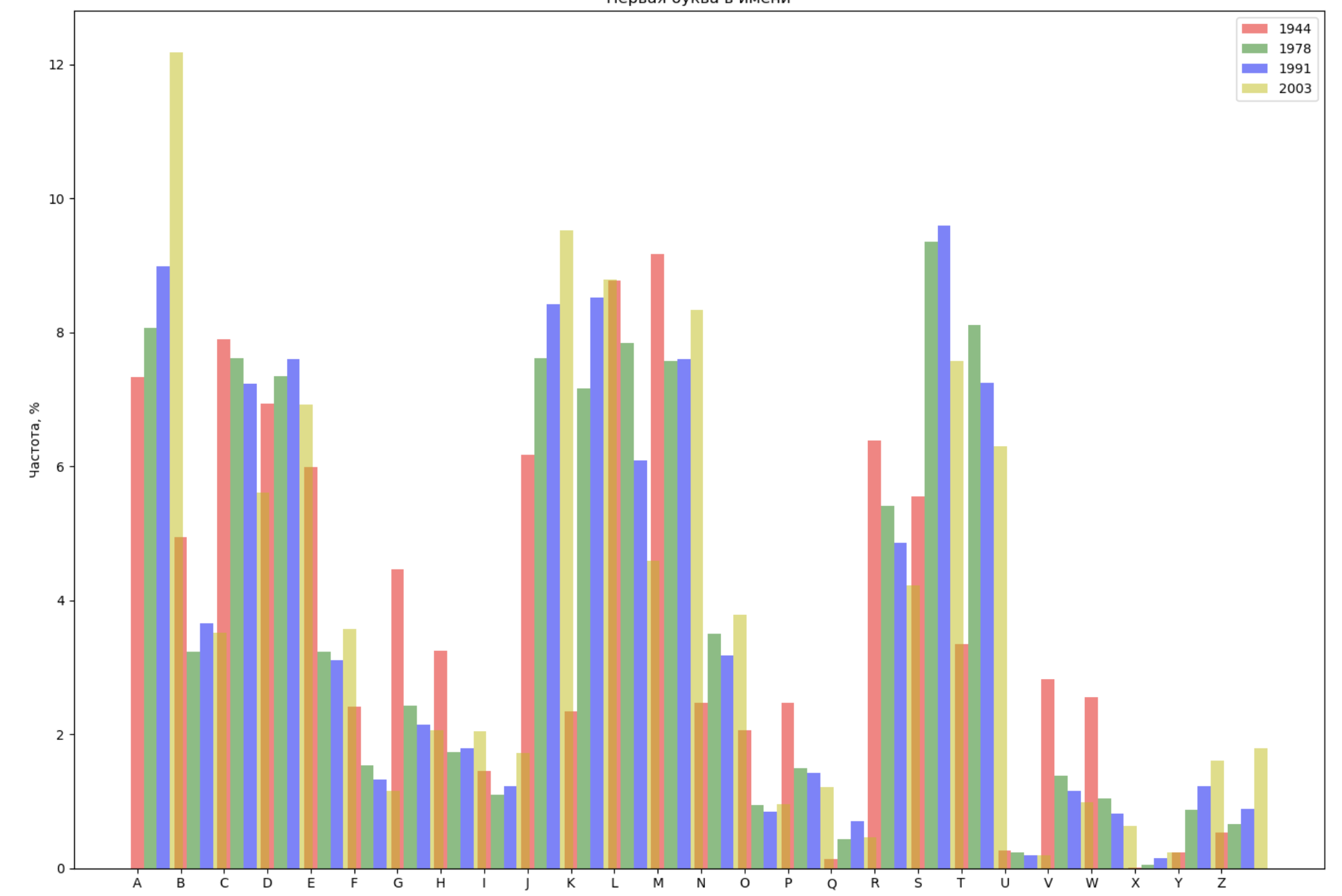
- Выбрать 4 года из всего промежутка и отобразить для каждого года распределение по первой букве в имени и по последней букве в имени;
- Составить список из нескольких известных людей (президенты, певцы, актеры, киногерои) и оценить их влияние на динамику имен. Построить наглядную визуализацию.
Меньше слов, больше кода!
И, поехали.