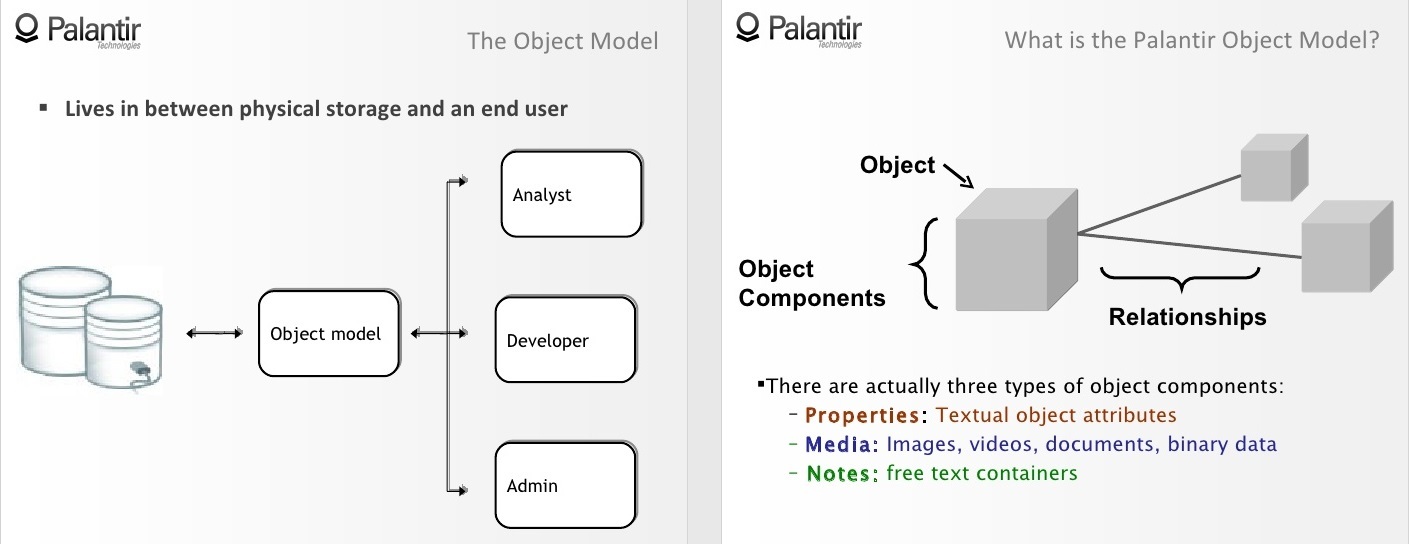
Palantir: Объектная модель
9 мин
Шрияс Виджайкумар, ведущий инженер по внедрению, расскажет про еще один элемент внутренней кухни системы Palantir.
Как организации управляются с данными, на текущий момент?
В существующих системах встречаются довольно распространенные артефакты, и многие из них, если не все, вам знакомы:
Что мы принципиально иначе делаем в Palantir?
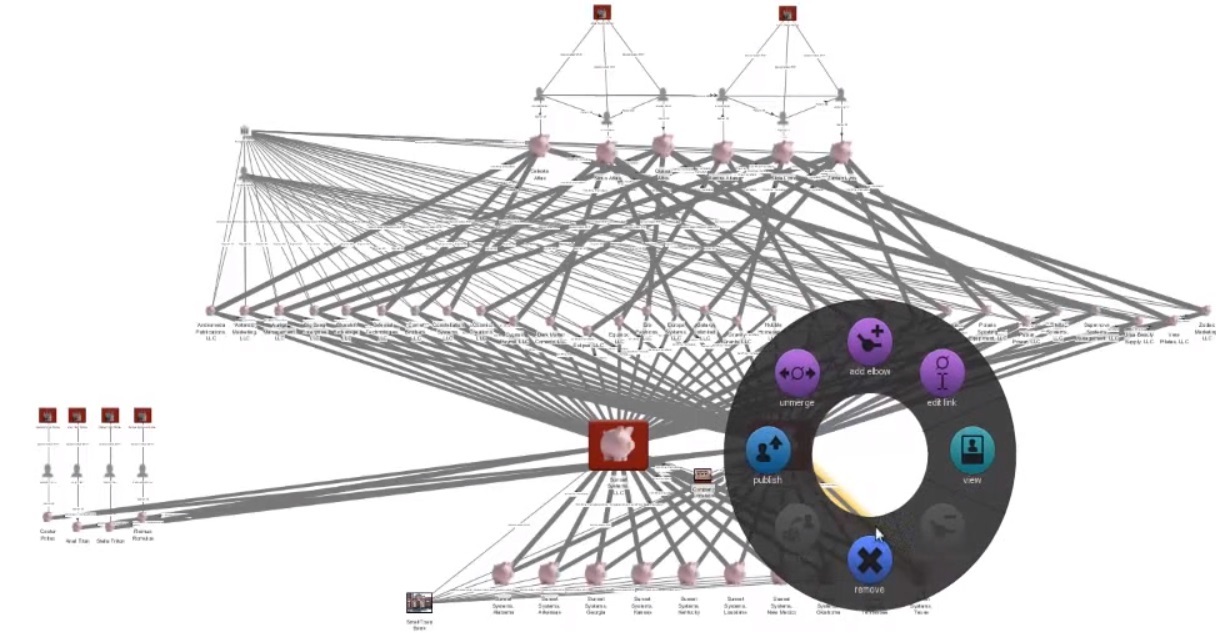
Когда мы разрабатывали систему, мы много работали с обратной связью от сообщества. Первое, что мы постарались запроектировать — это максимальная гибкость системы, дающая возможность моделировать все что угодно.
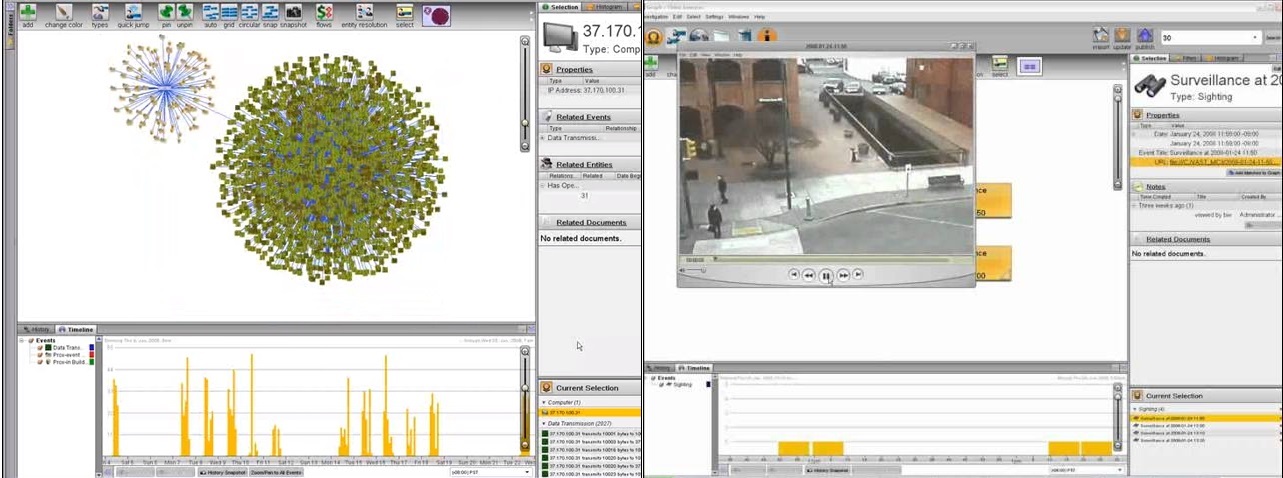
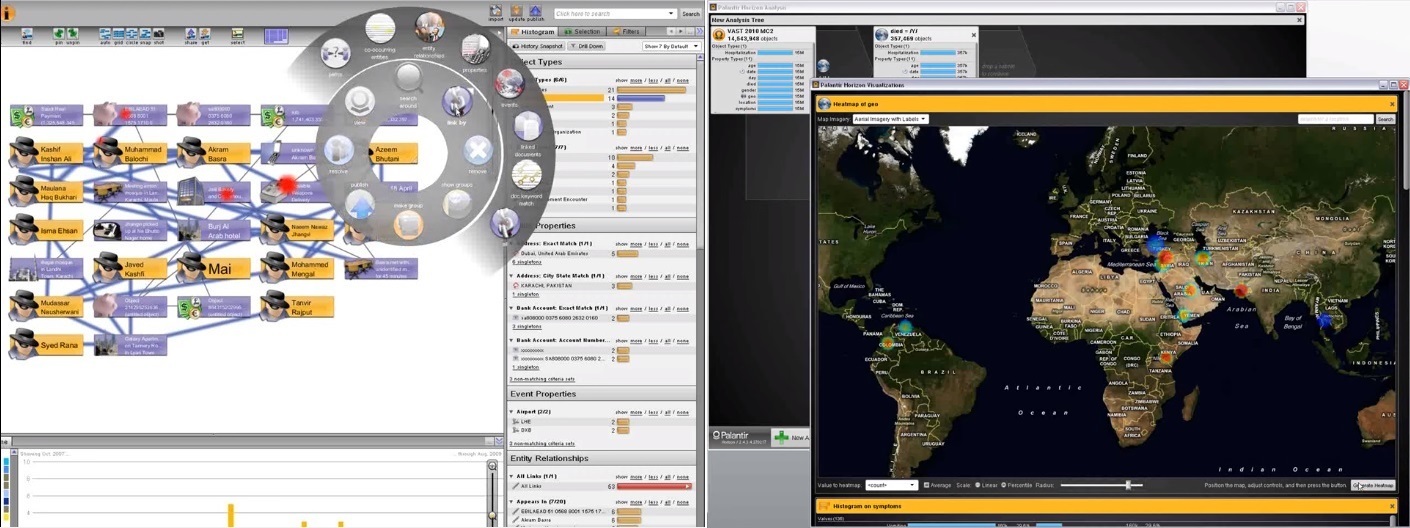
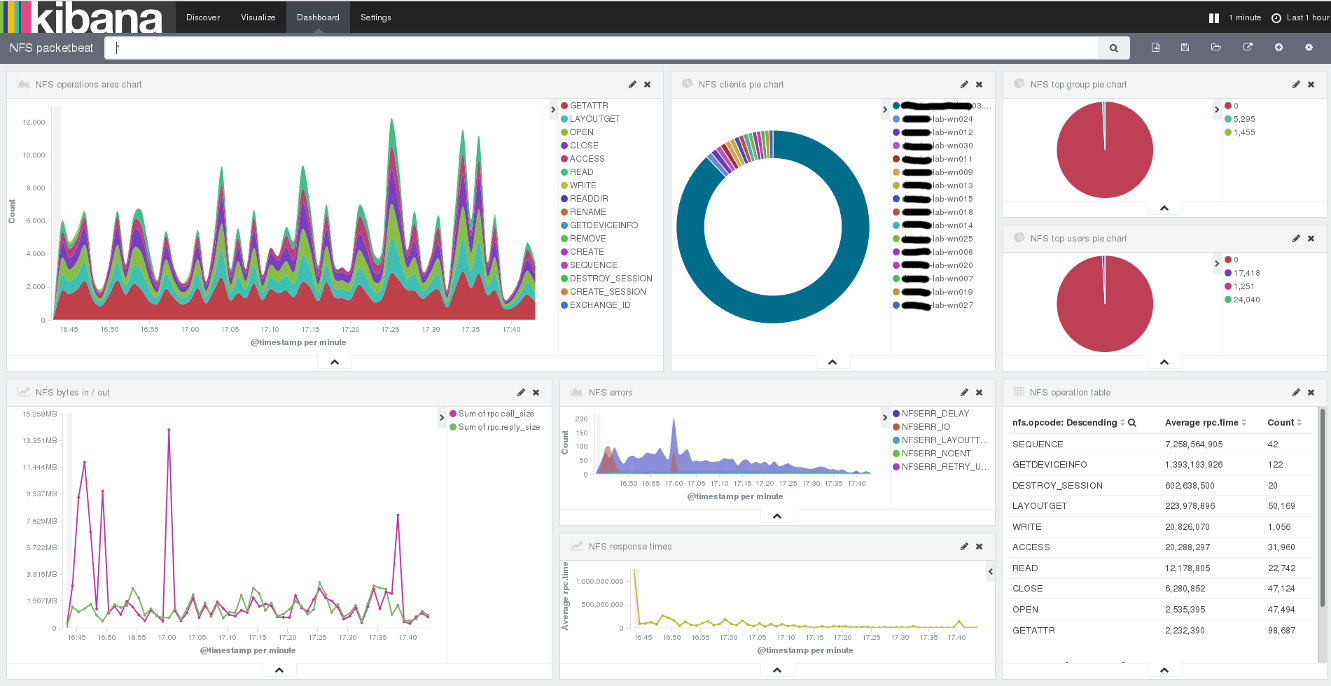
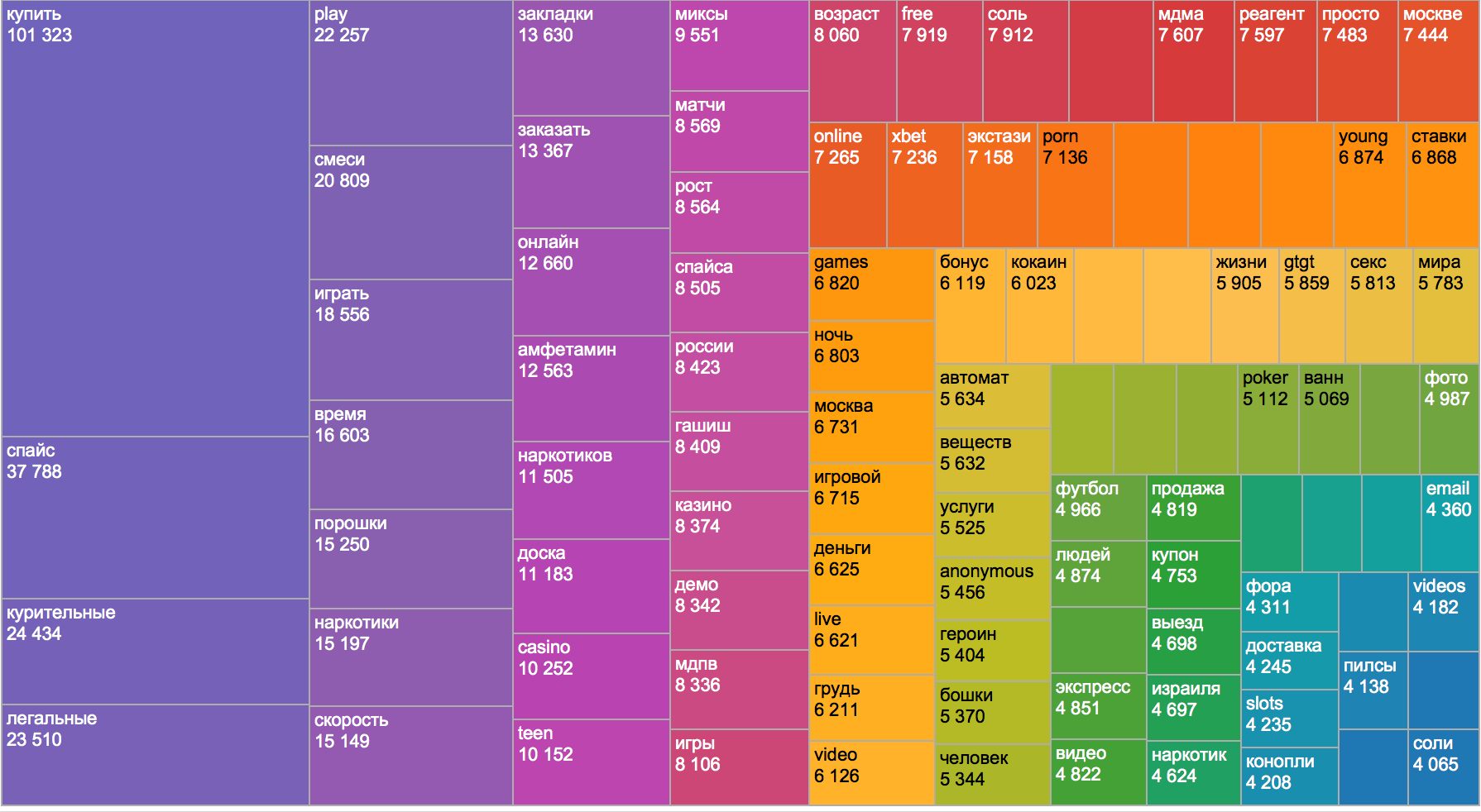
Гибкость означает, возможность работать с любыми типами данных в одном общем пространстве: от высокоструктурированных, таких как базы данных с выстроенными отношениями, до неструктурированных, таких как хранилище трафика сообщений, а также всех, находящихся между этими крайностями. Это также означает возможность создавать множество разнообразных полей для исследования без привязки к одной модели построения. Как и организация, они могут изменяться и эволюционировать со временем.
Следующей вещью, которую мы спроектировали, стало обобщение данных без потерь. Нам нужна платформа, которая бы отслеживала каждый обрывок информации до его источника или источников. В мультиплатформенной системе важное значение имеет контроль доступа, особенно если такая система, позволяет совершать всю полноту действий с данными.
Как организации управляются с данными, на текущий момент?
В существующих системах встречаются довольно распространенные артефакты, и многие из них, если не все, вам знакомы:
- пользователи часто оставляют заметки для себя в имени файла, так что мы можем встретить конструкции вида отправить_по_почте.пятница.10_утра.не_стирать!!;
- каждое изменение онтологии требует модификации всей схемы;
- данные из разных источников невозможно исследовать вместе, в одной среде, так что у вас может быть база данных людей и трафика сообщений, которые приходится исследовать по отдельности;
- пересинхронизация данных нецелесообразна или невозможна, — а это часто бывает нужно;
- информация не может быть прослежена до её источника.
Что мы принципиально иначе делаем в Palantir?
Когда мы разрабатывали систему, мы много работали с обратной связью от сообщества. Первое, что мы постарались запроектировать — это максимальная гибкость системы, дающая возможность моделировать все что угодно.
Гибкость означает, возможность работать с любыми типами данных в одном общем пространстве: от высокоструктурированных, таких как базы данных с выстроенными отношениями, до неструктурированных, таких как хранилище трафика сообщений, а также всех, находящихся между этими крайностями. Это также означает возможность создавать множество разнообразных полей для исследования без привязки к одной модели построения. Как и организация, они могут изменяться и эволюционировать со временем.
Следующей вещью, которую мы спроектировали, стало обобщение данных без потерь. Нам нужна платформа, которая бы отслеживала каждый обрывок информации до его источника или источников. В мультиплатформенной системе важное значение имеет контроль доступа, особенно если такая система, позволяет совершать всю полноту действий с данными.