

Отчасти это действенный совет, отчасти — вопрос к читателям.
Совет: при создании нового приложения, требующего постоянного хранения данных, как это и бывает в случае большинства веб-приложений, по умолчанию следует выбирать Postgres.
Отчасти это действенный совет, отчасти — вопрос к читателям.
Совет: при создании нового приложения, требующего постоянного хранения данных, как это и бывает в случае большинства веб-приложений, по умолчанию следует выбирать Postgres.


Около двух лет назад вышла небольшая статья Kafka Streams — непростая жизнь в production, в которой я описывал сложности, с которыми наша команда столкнулась при попытке решить задачи проекта с помощью kafka-streams. Эксперимент вышел неудачным, и мы в итоге совсем отказались от этой технологии. Вместо нее решили попробовать Clickhouse (CH), и сейчас уже можно сказать, что эта база нам очень хорошо подошла и отлично решает почти все задачи, которые нам ставит бизнес. В этой статье я расскажу об особенностях использования CH.
Прим. перев.: в этой статье сербский «инженер по масштабируемости» нагруженного онлайн-проекта в подробностях рассказывает о своем опыте оптимизации большой БД на базе MySQL. Проведена она была для того, чтобы выдержать резкий рост трафика на сайт, случившийся из-за пандемии.
База данных становится слишком большой или старой? Ее тяжело обслуживать? Что ж, надеюсь, я смогу немного помочь. Текст, который вы собираетесь прочитать, содержит реальный опыт масштабирования монолитной базы данных, лежащей в основе одного из сайтов Топ-250 (согласно alexa.com). На момент написания этой статьи chess.com занимал 215 место в мире по популярности. Ежедневно к нам заглядывали более 4 млн уникальных пользователей, а наши MySQL-базы обрабатывали в общей сложности более 7 млрд запросов. Год назад сайт ежедневно посещали 1 млн уникальных пользователей; в марте прошлого года их число увеличилось до 1,3 млн; сегодня более 4 млн человек заходят на chess.com ежедневно, а число сыгранных партий превышает 8 млн. Я, конечно, знаю, что это не сопоставимо с самыми крупными игроками на рынке, однако наш опыт все же может помочь в такой сложной задаче, как «исправление» монолитной базы данных и ее вывод на новый уровень производительности.

Алексей Миловидов работал инженером в Яндекс.Метрике, и перед ним стояла непростая задача.
Яндекс.Метрика работала с петабайтами данных — это был третий по популярности сервис веб-аналитики в мире. Для него нужна была база данных, которая может обрабатывать огромное количество данных в реальном времени, очень быстро, при этом не сжигая миллиарды денег.
Долгое время такая СУБД разрабатывалась только для внутренних нужд — но в 2016 вышла в опенсорс под названием ClickHouse, и сообщество встречает инструмент по-разному.
Мы поговорили с Алексеем о том, как он стал разработчиком, почему ClickHouse намного быстрее всех аналогов и как так получилось, какова цена производительности, почему ClickHouse стал опенсорсным и куда вообще движется индустрия.
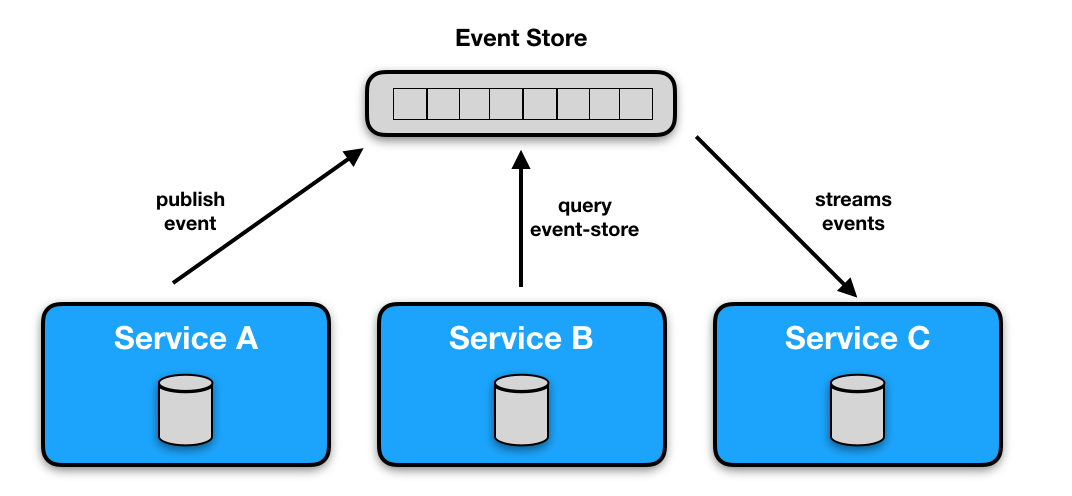
Tarantool — это платформа in-memory вычислений с гибкой схемой данных. На её основе можно создать распределённое хранилище, веб-сервер, высоконагруженное приложение или, в конце концов, сервис, включающий в себя всё вышеперечисленное. Но какой бы ни была ваша промышленная задача, однажды настанет момент, когда её решение придётся мониторить. В этой статье я хочу дать обзор существующих средств для мониторинга приложения на базе Tarantool и пройтись по основным кейсам работы с ними.
Я работаю в команде, которая занимается разработкой, внедрением и поддержкой готовых решений на основе Tarantool. Для вывода наших приложений в эксплуатацию на контуре заказчика было необходимо не только разобраться в текущих возможностях мониторинга, но и доработать их. Большая часть доработок в результате вошла в те или иные стандартные пакеты. Данный материал является текстовой выжимкой этого опыта, и может пригодиться тем, кто решит пройти по той же тропе.

Привет! Меня зовут Влад Божьев, я старший разработчик юнита АБ-тестирования Авито. Один из наших ключевых инструментов – M42, сервис для визуализации метрик. Он позволяет быстро проверять гипотезы, анализировать отклонения и оценивать инициативы.
В этой статье мы с вами погружаемся в самое сердце M42 и разбираем, как же там хранятся отчеты по метрикам. Это не просто рассказ, это почти детективная история о том, как мы искали оптимальное решение.
В нашем семантическом слое данных больше 20 000 метрик, и есть десятки разрезов для каждой из них. Под катом рассказываю, как мы храним терабайты данных и автоматизируем добавление новых разрезов в отчёт M42.

Привет, Хабр! Последние несколько лет я занимаюсь разработкой баз данных ВКонтакте. Аудитория такой крупной соцсети ежедневно генерирует огромные массивы информации.
В этой статье я расскажу про хранилище ВКонтакте: как оно менялось, что мы делаем для оптимизации занятого места и как гарантируем сохранность данных.


Привет, Хабр! Недавно мы делали доклад на конференции HighLoad 2023 — «Мифы и реалии Мультимастера в архитектуре СУБД PostgreSQL». Мы — это Павел Конотопов (@kakoka) и Михаил Жилин (@mizhka), сотрудники компании Postgres Professional. Павел занимается архитектурой построения отказоустойчивых кластеров, а Михаил — анализом производительности СУБД. У каждого за плечами более десяти лет опыта в своей области.
Порассуждаем о том, как развивалась технология «Мультимастер» в экосистеме PostgreSQL, остановимся на том, что она из себя представляет, на каких внутренних механизмах PostgreSQL основана и как её можно использовать.
Мы также поговорим о том, существует ли «Честный Мультимастер» (само понятие «Честный Мультимастер» достаточно специфично и в основном употребляется в кругу разработчиков), какие реализации у него есть и как его следует применять.

Вчера Hubert 'depesz' Lubaczewski закрыл доступ с российских IP ко всем своим сайтам, включая широко известный визуализатор планов PostgreSQL-запросов explain.depesz.com.
Но это не беда, потому что в компании "Тензор" мы разработали сервис explain.tensor.ru, функционал которого гораздо обширнее, и которым можете воспользоваться и вы.

"Шеф, всё пропало, у нас serial на мегатаблице кончился!" - а это значит, что либо вы его неаккуратно накрутили сами, либо у вас действительно данных столько, что разрядности integer-столбца уже не хватает для вашей большой и активной таблицы в PostgreSQL-базе.
Да и столбец этот не простой, а целый PRIMARY KEY, на который еще и ряд других немаленьких таблиц по FOREIGN KEY завязан. А еще и приложение останавливать совсем не хочется, ибо клиентам 24x7 обещано...
В общем, надо как-то с минимальными блокировками увеличить размер PK-поля в большой таблице, на которое многое завязано.
WITH TIES из стандарта SQL:2008:OFFSET start { ROW | ROWS }
FETCH { FIRST | NEXT } [ count ] { ROW | ROWS } { ONLY | WITH TIES }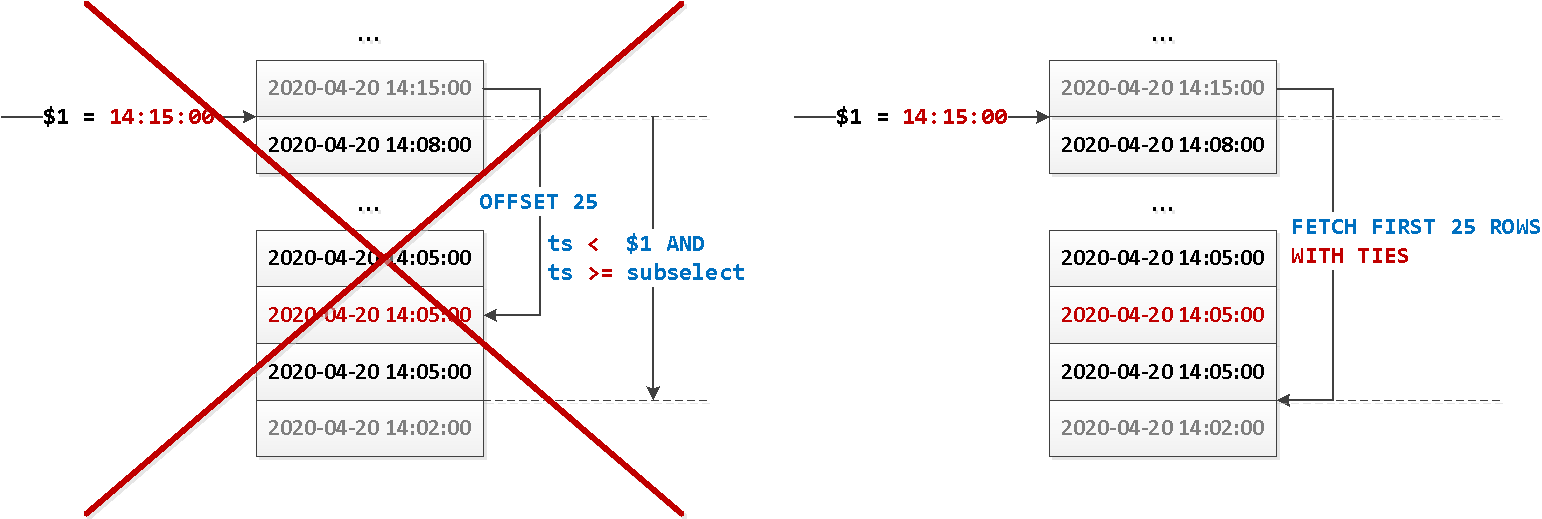
В их внешнем облике ничто не вызывает подозрений. Более того, они даже кажутся тебе хорошо и давно знакомыми. Но это только до тех пор, пока ты их не проверишь. Вот тут-то они и проявят свою коварную сущность, сработав совсем не так, как ты ожидал. А иногда выкидывают такое, от чего волосы просто встают дыбом — к примеру, теряют доверенные им секретные данные. Когда ты делаешь им очную ставку, они утверждают, что не знают друг друга, хотя в тени усердно трудятся под одним колпаком. Пора уже наконец-то вывести их на чистую воду. Давайте же и мы разберемся с этими подозрительными типами.
Типизация данных в PostgreSQL, при всей своей логичности, действительно преподносит порой очень странные сюрпризы. В этой статье мы постараемся прояснить некоторые их причуды, разобраться в причине их странного поведения и понять, как не столкнуться с проблемами в повседневной практике. Сказать по правде, я составил эту статью в том числе и в качестве некоего справочника для самого себя, справочника, к которому можно было бы легко обратиться в спорных случаях. Поэтому он будет пополняться по мере обнаружения новых сюрпризов от подозрительных типов. Итак, в путь, о неутомимые следопыты баз данных!




Легкий и простой способ настроить бесплатную синхронизацию Obsidian между всеми своими устройствами.
