Наконец-то в России вышел
учебник по SystemVerilog уровнем выше чем для начинающих. Учебник описывает технологии и приемы, которые спрашивают на интервью в NVidia, Intel, AMD, Apple и другие электронные компании: использование concurrent assertions и functional coverage, что сейчас требуют не только от инженеров по верификации, но и от дизайнеров микросхем; алгоритм работы симулятора с дельта-циклами; вменяемое объяснение static timing analysis; схемы коммуникации аппаратных блоков через аппаратные очереди; реализацию этих коммуникаций с помощью конечных автоматов с трактами данных и т.д.
В главе про последнее российского читателя может озадачить упоминание «политкорректной системы». Что бы это значило? Это вероятно намек на
казус, который произошел в округе Лос-Анжелес в 2003 году. Чиновники Лос-Анджелеса попросили производителей, поставщиков и подрядчиков прекратить использование терминов «master/slave» («хозяин» и «раб») в отношении компьютерного оборудования, так как одному из работников округа эти термины напомнили про рабовладельческое прошлое.
Сейчас авторы технической литературы избегают терминов master/slave. В современной Америке работают и афро-американские инженеры (например София Мвокани из Камеруна — на фото слева), и использование старых терминов выглядит архаично, как выглядели бы например термины «пан/холоп» в украинской технической литературе вместо принятых «провідний/ведений» (рус. «ведущий/ведомый»).
Это не первый раз, когда в российском электронном образовании появляется тема борьбы афро-американцев за гражданские права. Например Татьяна Волкова, известный специалист по образованию в электронике, носит маечку с эмблемой «Черных Пантер», калифорнийского движения, которое в свое время сочло мирный протест недостаточным, и занялось вооруженным протестом.
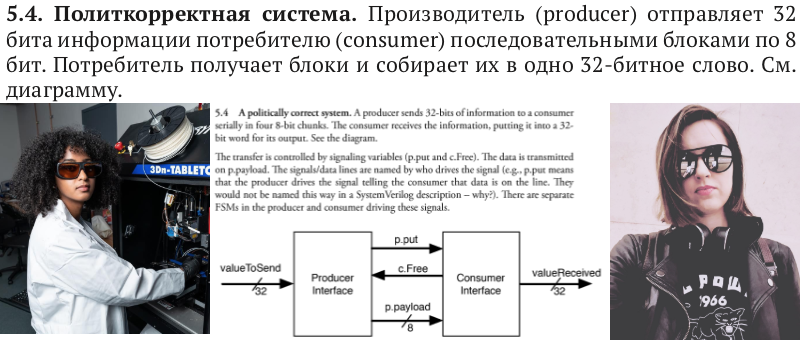
Полное изображение эмблемы под кожанкой Татьяны Александровны — под катом, но в основном я буду рассказывать про дельта-циклы и конечные автоматы:

 Предлагаемая иерархия инструментов (здесь и далее изображения из оригинальной статьи)
Предлагаемая иерархия инструментов (здесь и далее изображения из оригинальной статьи)